
Ten dokument jest kontynuacją artykułu WebAssembly i WebGPU – ulepszenia na potrzeby szybszej AI w internecie, część 1. Zanim przejdziesz dalej, przeczytaj ten post lub obejrzyj wykład z konferencji IO 24.



WebGPU
WebGPU zapewnia aplikacjom internetowym dostęp do sprzętowego GPU klienta, aby umożliwić wydajne, wysoce równoległe przetwarzanie. Od czasu wprowadzenia WebGPU w Chrome widzieliśmy w internecie niesamowite demonstracje sztucznej inteligencji (AI) i uczenia maszynowego (ML).
Na przykład dyfuzja stabilna w sieci pokazała, że można używać AI do generowania obrazów na podstawie tekstu bezpośrednio w przeglądarce. W tym roku zespół Mediapipe w Google opublikował eksperymentalne wsparcie dla wnioskowania na podstawie dużych modeli językowych.
Na tej animacji widać Gemma, duży model językowy open source (LLM) firmy Google, który działa w czasie rzeczywistym na urządzeniu w Chrome.
W tym filmie demonstracyjnym firmy Hugging Face z wykorzystaniem modelu Segment Anything firmy Meta można zobaczyć, jak na kliencie generowane są wysokiej jakości maski obiektów.
To tylko kilka z niesamowitych projektów, które pokazują możliwości WebGPU w zakresie AI i ML. WebGPU pozwala tym modelom i innym działać znacznie szybciej niż na procesorze.
Test porównawczy WebGPU dla umieszczania tekstu firmy Hugging Face pokazuje ogromne przyspieszenie w porównaniu z implementacją tego samego modelu na procesorze CPU. Na laptopie z procesorem Apple M1 Max WebGPU był ponad 30 razy szybszy. Inni użytkownicy zgłaszają, że WebGPU przyspiesza test porównawczy ponad 120 razy.
Ulepszanie funkcji WebGPU na potrzeby AI i ML
WebGPU świetnie sprawdza się w przypadku modeli AI i ML, które mogą mieć miliardy parametrów dzięki obsłudze shaderów obliczeniowych. Shadery obliczeniowe działają na karcie graficznej i ułatwiają równoległe wykonywanie operacji na tablicach na dużych zbiorach danych.
W ubiegłym roku wprowadziliśmy wiele ulepszeń WebGPU, w tym nowe możliwości, które zwiększają wydajność ML i AI w internecie. Niedawno wprowadziliśmy 2 nowe funkcje: 16-bitowe produkty z liczbą zmiennoprzecinkową i zapakowane produkty z liczbą całkowitą.
16-bitowa liczba zmiennoprzecinkowa
Pamiętaj, że obciążenia związane z uczeniem maszynowym nie wymagają precyzji. shader-f16 to funkcja, która umożliwia używanie typu f16 w języku cieniowania WebGPU. Ten typ liczby zmiennoprzecinkowej zajmuje 16 bitów zamiast zwykłych 32 bitów. f16 ma mniejszy zakres i mniejszą dokładność, ale w przypadku wielu modeli uczenia maszynowego jest to wystarczające.
Ta funkcja zwiększa wydajność na kilka sposobów:
Mniej pamięci: tensory z elementami f16 zajmują połowę miejsca, co zmniejsza wykorzystanie pamięci o połowę. Obliczenia GPU często są ograniczane przez przepustowość pamięci, więc połowa pamięci może oznaczać, że shadery działają dwa razy szybciej. Teoretycznie nie musisz używać f16, aby zaoszczędzić na przepustowości pamięci. Dane można przechowywać w formacie o niskiej precyzji, a potem rozszerzać do pełnego formatu f32 w shaderze na potrzeby obliczeń. Jednak GPU zużywa dodatkową moc obliczeniową na pakowanie i rozpakowywanie danych.
Mniejsza konwersja danych: f16 zużywa mniej zasobów obliczeniowych, ponieważ minimalizuje konwersję danych. Dane o niskiej dokładności można przechowywać i wykorzystywać bezpośrednio bez konwertowania.
Zwiększony paralelizm: nowoczesne procesory graficzne mogą jednocześnie przetwarzać więcej wartości w jednostkach wykonawczych, co pozwala im wykonywać większą liczbę obliczeń równoległych. Na przykład GPU, który obsługuje do 5 bilionów operacji zmiennoprzecinkowych typu f32 na sekundę, może obsługiwać 10 bilionów operacji zmiennoprzecinkowych typu f16 na sekundę.
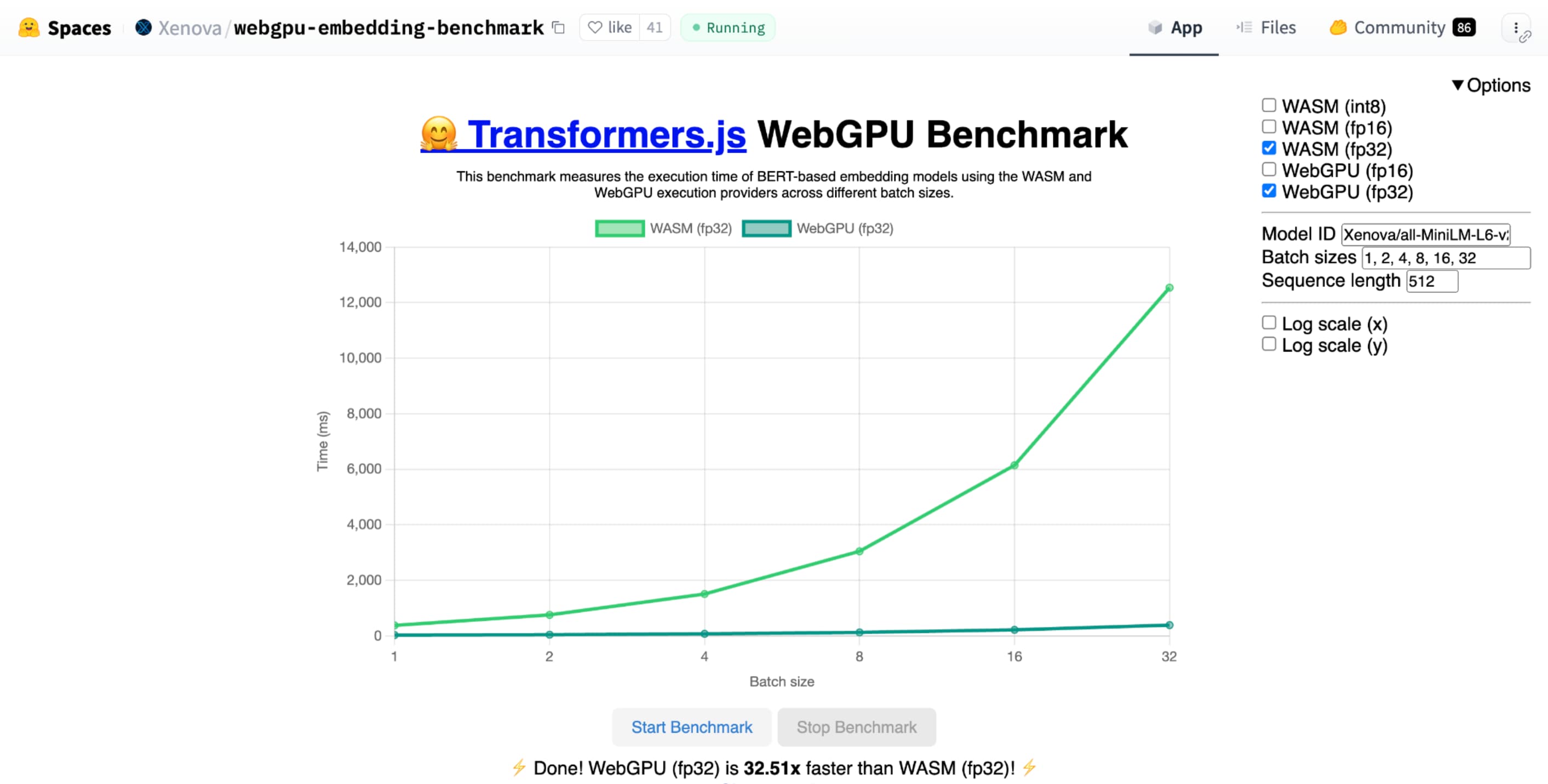
shader-f16 test WebGPU dla umieszczania tekstu w Hugging Face działa 3 razy szybciej niż f32 na laptopie Apple M1 Max.
WebLLM to projekt, który może uruchamiać wiele dużych modeli językowych. Używa ona Apache TVM, czyli platformy kompilacji systemów uczących się typu open source.
Poprosiłem WebLLM o zaplanowanie podróży do Paryża, korzystając z modelu Llama 3 z 8 miliardami parametrów. Wyniki pokazują, że podczas fazy wstępnego wypełniania modelu f16 jest 2,1 raza szybszy niż f32. Podczas fazy dekodowania jest to ponad 1, 3 raza szybciej.
Aplikacje muszą najpierw potwierdzić, że adapter GPU obsługuje f16, i jeśli jest dostępny, włączyć go wyraźnie podczas żądania urządzenia z GPU. Jeśli funkcja f16 nie jest obsługiwana, nie możesz jej wywołać w tablicy requiredFeatures.
// main.js
const adapter = await navigator.gpu.requestAdapter();
const supportsF16 = adapter.features.has('shader-f16');
if (supportsF16) {
// Use f16.
const device = await adapter.requestDevice({
requiredFeatures: ['shader-f16'],
});
initApp(device);
}
Następnie w shaderach WebGPU musisz wyraźnie włączyć f16 u góry. Następnie możesz używać go w shaderze tak jak każdego innego typu danych typu float.
// my-shader.wgsl
enable f16;
struct Data {
values : array<vec4<f16>>
}
@group(0) @binding(0) var<storage, read> data : Data;
@compute @workgroup_size(64) fn main(@builtin(global_invocation_id) gid : vec3u) {
let value : vec4<f16> = data.values[gid.x];
...
}
Zapakowane produkty typu dot oparte na liczbach całkowitych
Wiele modeli nadal działa dobrze z zaledwie 8 bitami dokładności (połowa wartości f16). Jest to popularne w przypadku modeli LLM i modeli obrazów do segmentacji i rozpoznawania obiektów. Należy jednak pamiętać, że jakość wyjściowa modeli spada wraz ze spadkiem dokładności, dlatego kwantyzacja 8-bitowa nie jest odpowiednia do wszystkich zastosowań.
Wbudowane wsparcie dla wartości 8-bitowych ma stosunkowo niewiele kart graficznych. Właśnie w takich przypadkach przydają się produkty typu dot w pakiecie. Wprowadziliśmy DP4a w Chrome 123.
Nowoczesne procesory graficzne mają specjalne instrukcje, które umożliwiają pobranie 2 liczb całkowitych 32-bitowych, interpretowanie ich jako 4 kolejne zapakowane liczby całkowite 8-bitowe i obliczanie ich iloczynu skalarny.
Jest to szczególnie przydatne w przypadku AI i uczenia maszynowego, ponieważ rdzeny mnożenia macierzy składają się z bardzo wielu produktów dot.
Załóżmy na przykład, że mnożymy macierz 4 x 8 przez wektor 8 x 1. Obliczenie tego wymaga 4 iloczynów skalarnych, aby obliczyć każdą z wartości wektora wyjściowego, czyli A, B, C i D.
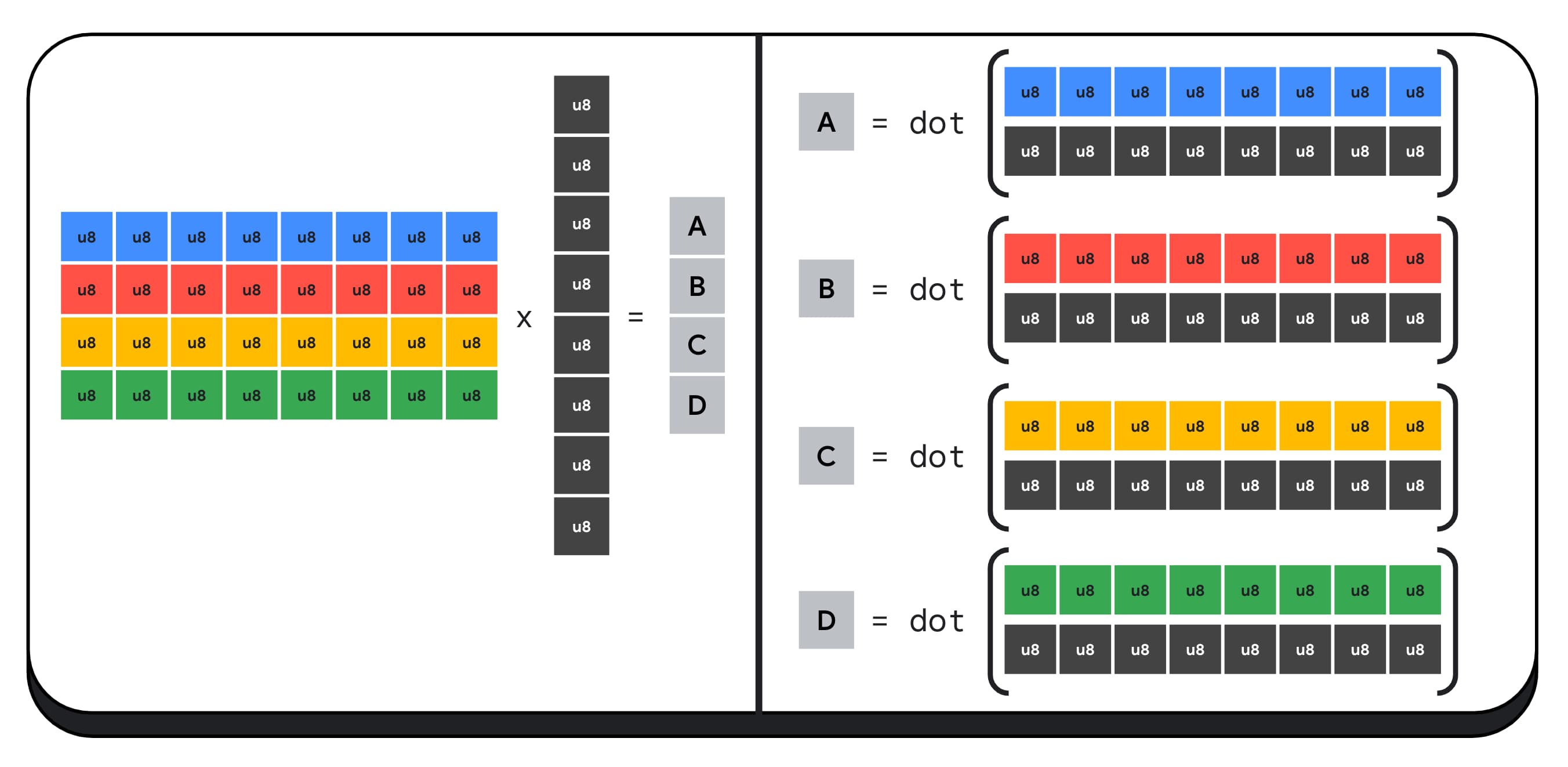
Proces obliczania każdego z tych wyników jest taki sam. Przyjrzymy się krokom związanym z obliczeniem jednego z nich. Przed wykonaniem obliczeń musimy najpierw przekonwertować 8-bitowe dane całkowite na typ, za pomocą którego można wykonywać operacje arytmetyczne, np. f16. Następnie wykonujemy mnożenie element po elemencie i na koniec sumujemy wszystkie produkty. W przypadku całej mnożenia macierzy przez wektor wykonujemy łącznie 40 konwersji liczb całkowitych na liczby zmiennoprzecinkowe, aby rozpakować dane, 32 mnożenia liczb zmiennoprzecinkowych i 28 dodatków liczb zmiennoprzecinkowych.
W przypadku większych macierzy z większą liczbą operacji zapakowane mnożenia wektorów z liczb całkowitych mogą pomóc w zmniejszeniu nakładu pracy.
W przypadku każdego z wyjść wektora wyników wykonujemy 2 operacje iloczynu skalarnego za pomocą wbudowanego języka shadringu WebGPU dot4U8Packed, a potem zliczamy wyniki. W przypadku całej mnożącej się macierzy i wektora nie wykonujemy żadnej konwersji danych. Wykonujemy 8 operacji dodawania liczb całkowitych i 4 operacje dodawania liczb całkowitych zapakowanych w punktach.
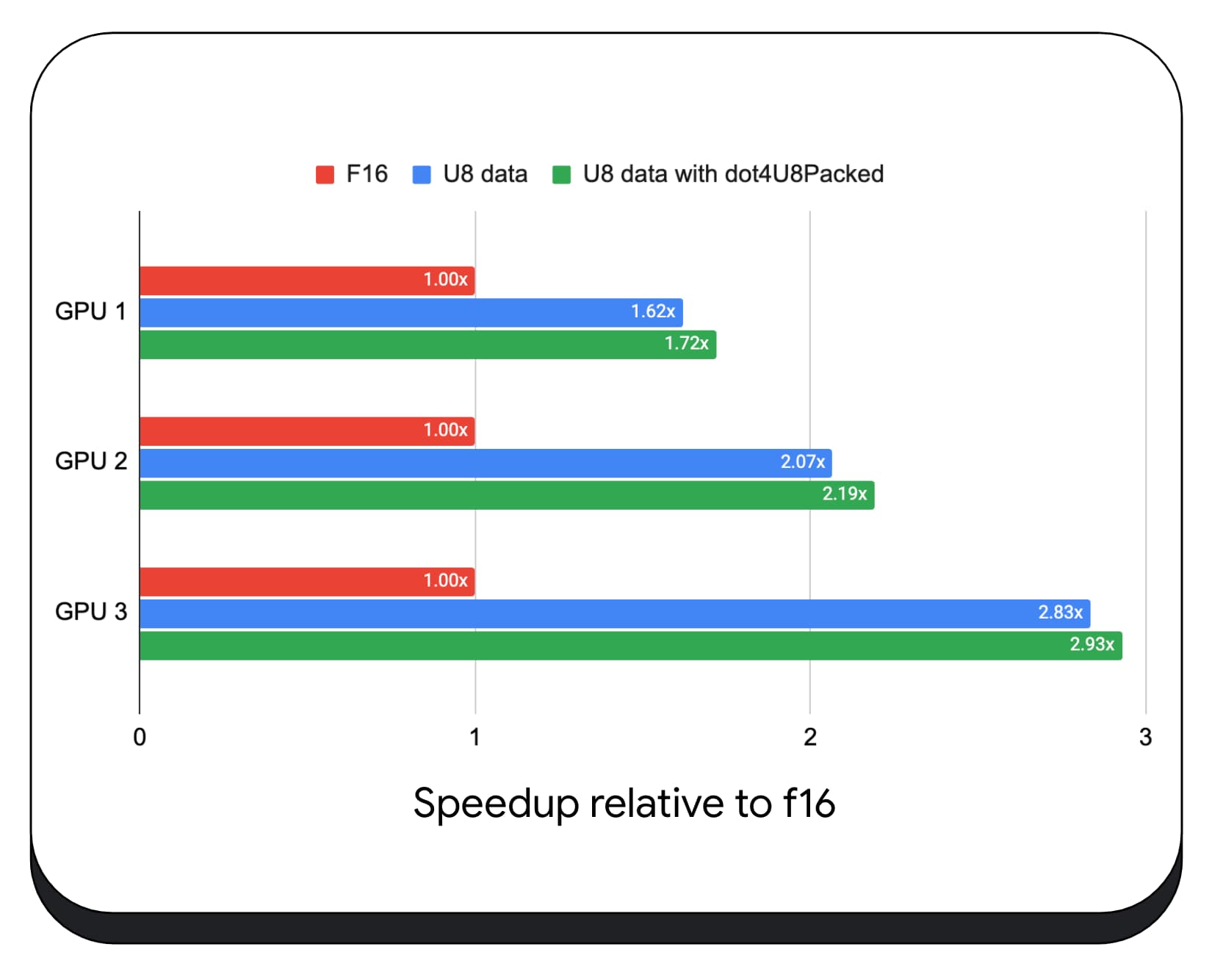
Testowaliśmy spakowane produkty typu dot z 8-bitowymi danymi na różnych kartach graficznych dla użytkowników. W porównaniu z 16-bitową liczbą zmiennoprzecinkową 8-bitowa jest od 1,6 do 2,8 raza szybsza. Gdy dodatkowo używamy spakowanych produktów typu dot, wydajność jest jeszcze lepsza. Jest ona 1,7–2,9 razy szybsza.
Sprawdź, czy przeglądarka obsługuje usługę wgslLanguageFeatures. Jeśli GPU nie obsługuje natywną obsługę pakietów dot, przeglądarka polyfilluje własną implementację.
// main.js
if (navigator.gpu.wgslLanguageFeatures.has('packed_4x8_integer_dot_product')) {
// Use dot4U8Packed, dot4I8Packed builtin
// functions in the shaders.
}
Poniższy fragment kodu pokazuje różnice w kodzie, które wskazują na zmiany potrzebne do użycia zapakowanych liczb całkowitych w shaderze WebGPU.
Przed – shader WebGPU, który gromadzi częściowe iloczyny punktowe w zmiennej „sum”. Na końcu pętli zmienna „sum” zawiera pełny iloczyn punktowy wektora i jednego wiersza macierzy wejściowej.
// my-dot-product.wgsl @compute @workgroup_size(64) fn main(@builtin(global_invocation_id) gid : vec3u) { var sum : f16; let start = gid.x * uniforms.dim; for (var i = 0u; i < uniforms.dim; i++) { let v1 : vec4<f16> = vector.values[i]; let v2 : vec4<f16> = matrix.values[start + i]; sum += dot(v1, v2); } }
Po zmianach – shader WebGPU napisany z wykorzystaniem zapakowanych iloczynowych liczb całkowitych. Główna różnica polega na tym, że zamiast wczytywać 4 wartości zmiennoprzecinkowe z wektora i macierzy, ten shader wczytuje pojedynczą 32-bitową liczbę całkowitą. Ta 32-bitowa liczba całkowita zawiera dane 4 wartości liczb całkowitych 8-bitowych. Następnie wywołujemy funkcję dot4U8Packed, aby obliczyć iloczyn skalarny tych dwóch wartości.
// my-dot-product.wgsl
@compute @workgroup_size(64)
fn main(@builtin(global_invocation_id) gid : vec3u) {
var sum : f32;
let start = gid.x * uniforms.dim;
for (var i = 0u; i < uniforms.dim; i++) {
let v1 : u32 = vector.values[i];
let v2 : u32 = matrix.values[start + i];
sum += dot4U8Packed(v1, v2);
}
}
Zarówno 16-bitowe produkty z liczbami zmiennoprzecinkowymi, jak i produkty z zapakowanymi liczbami całkowitymi są funkcjami wbudowanymi w Chrome, które przyspieszają działanie AI i ML. 16-bitowa arytmetyka zmiennoprzecinkowa jest dostępna, gdy sprzęt ją obsługuje, a Chrome wdraża spakowane produkty całkowitoliczbowe na wszystkich urządzeniach.
Aby uzyskać lepszą wydajność, możesz już teraz korzystać z tych funkcji w Chrome Stable.
Proponowane funkcje
W przyszłości planujemy zająć się jeszcze dwoma funkcjami: podgrupami i współpracującą mnożącą macierzem.
Funkcja podgrup umożliwia komunikację na poziomie SIMD lub wykonywanie zbiorczych operacji matematycznych, takich jak suma dla większej liczby niż 16 liczb. Umożliwia to efektywne udostępnianie danych w różnych wątkach. Podgrupy są obsługiwane w przypadku interfejsów API nowoczesnych kart graficznych, ale mają różne nazwy i nieco inne formy.
Stworzyliśmy wspólny zestaw, który przedstawiliśmy grupie standaryzacyjnej WebGPU. Oprócz tego prototypowaliśmy podgrupy w Chrome za pomocą flagi eksperymentalnej i przedstawiliśmy wstępne wyniki. Głównym problemem jest zapewnienie zachowania przenośności.
Współdzielone mnożenie macierzy to nowość w procesorach graficznych. Duże mnożenie macierzy można podzielić na wiele mniejszych mnożeń macierzy. Współdziałanie mnożenia macierzy wykonuje mnożenie na tych mniejszych blokach o stałym rozmiarze w jednym logicznym kroku. W ramach tego kroku grupa wątków współpracuje ze sobą, aby obliczyć wynik.
Zbadaliśmy obsługę w podstawowych interfejsach API GPU i planujemy przedstawić propozycję grupie standaryzacyjnej WebGPU. Podobnie jak w przypadku podgrup, spodziewamy się, że większość dyskusji będzie dotyczyć przenoszenia.
Aby ocenić wydajność operacji na podgrupach w rzeczywistych zastosowaniach, zintegrowaliśmy eksperymentalną obsługę podgrup w MediaPipe i przetestowaliśmy ją z protokołem Chrome do operacji na podgrupach.
W fazie wstępnego wypełniania dużego modelu językowego użyliśmy podgrup w jądrach GPU, więc podaję tylko przyspieszenie w fazie wstępnego wypełniania. Na karcie graficznej Intel okazuje się, że podgrupy działają 2,5 raza szybciej niż w przypadku wartości bazowej. Jednak te ulepszenia nie są spójne w przypadku różnych układów GPU.
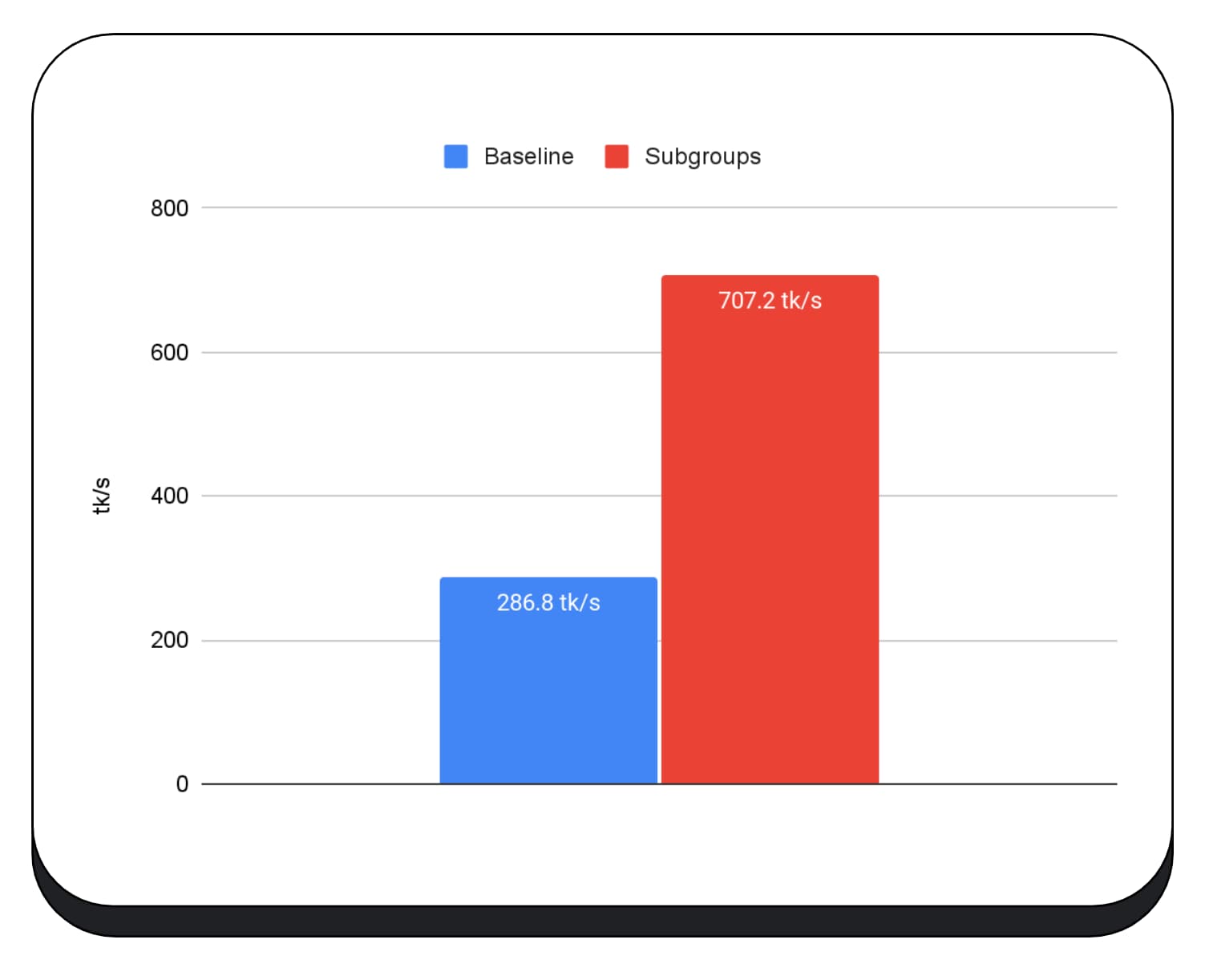
Następujący wykres pokazuje wyniki zastosowania podgrup do optymalizacji mikrobenchmarku mnożenia macierzy na różnych konsumenckich procesorach graficznych. Mnożenie macierzy jest jedną z cięższych operacji w modelach językowych. Dane wskazują, że w przypadku wielu GPU podgrupy zwiększają szybkość 2-, 5-, a nawet 13-krotnie w porównaniu z wartością bazową. Zwróć jednak uwagę, że w przypadku pierwszego GPU podgrupy nie są wcale dużo lepsze.
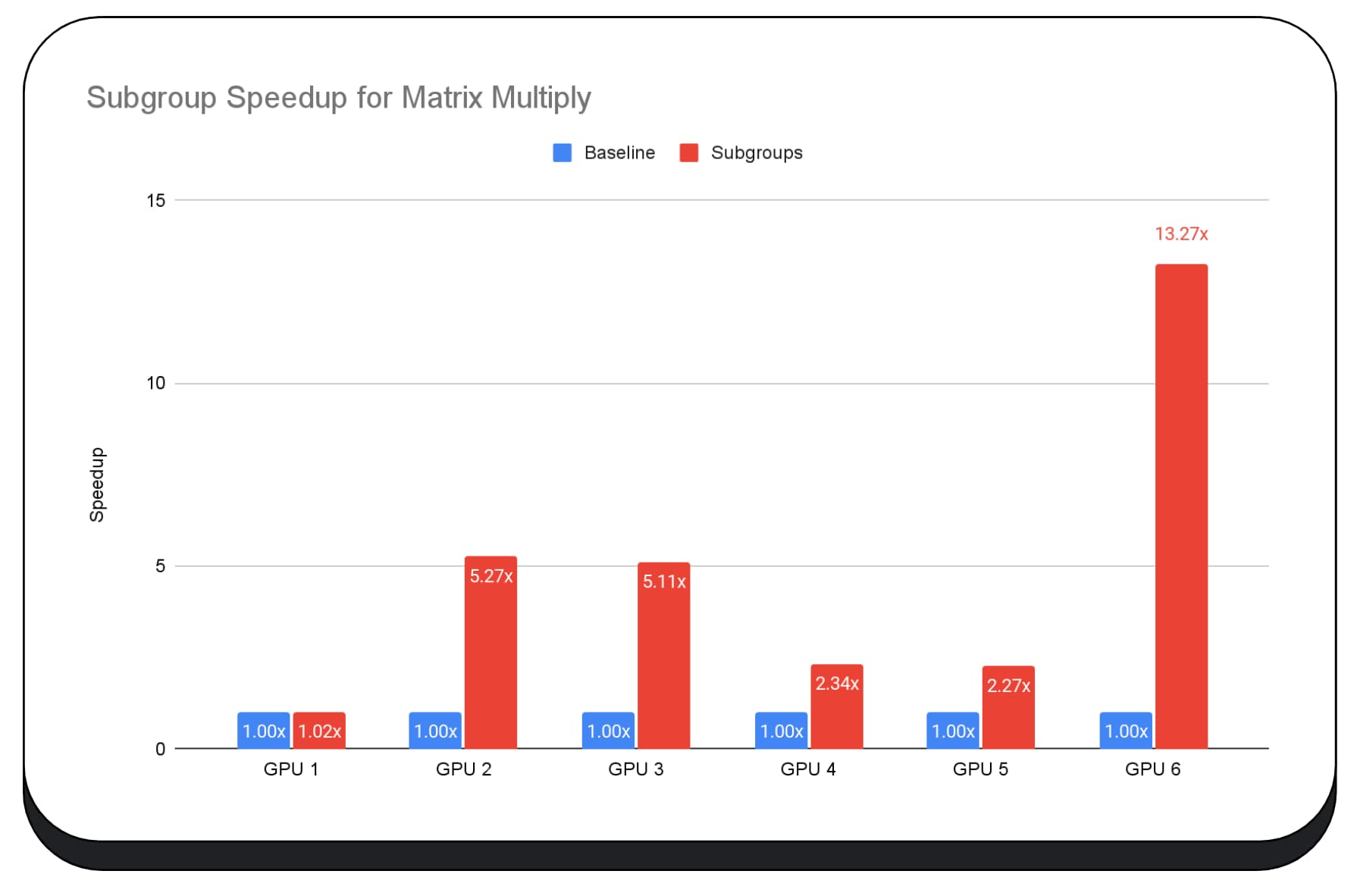
Optymalizacja GPU jest trudna
Ostatecznie najlepszy sposób optymalizacji GPU zależy od tego, jakie GPU oferuje klient. Korzystanie z nowych, zaawansowanych funkcji karty graficznej nie zawsze przynosi oczekiwane efekty, ponieważ może być zależne od wielu złożonych czynników. Najlepsza strategia optymalizacji na jednym GPU może nie być najlepsza na innym.
Chcesz zminimalizować przepustowość pamięci, jednocześnie w pełni wykorzystując wątki obliczeniowe GPU.
Ważne mogą być też wzorce dostępu do pamięci. Procesory graficzne działają znacznie lepiej, gdy wątki obliczeniowe uzyskują dostęp do pamięci w sposób optymalny dla danego sprzętu. Ważne: na różnych kartach graficznych możesz się spodziewać różnych wyników. W zależności od karty graficznej może być konieczne przeprowadzenie różnych optymalizacji.
Na poniższym wykresie mamy ten sam algorytm mnożenia macierzy, ale dodaliśmy dodatkowy wymiar, aby lepiej pokazać wpływ różnych strategii optymalizacji oraz złożoność i zmienność na różnych procesorach graficznych. Wprowadziliśmy tu nową technikę, którą nazwaliśmy „Swizzle”. Swizzle optymalizuje wzorce dostępu do pamięci pod kątem sprzętu.
Jak widać, przełączanie pamięci ma duży wpływ. Czasami jest on nawet większy niż w przypadku podgrup. W przypadku GPU 6 zamiana zapewnia 12-krotne przyspieszenie, a podgrupy – 13-krotne. W zbiorze zapewniają niesamowity 26-krotny wzrost szybkości. W przypadku innych kart graficznych czasem mieszanie i subgrupy działają lepiej niż pojedynczo. Na innych kartach graficznych najlepiej sprawdza się wyłącznie mieszanie.
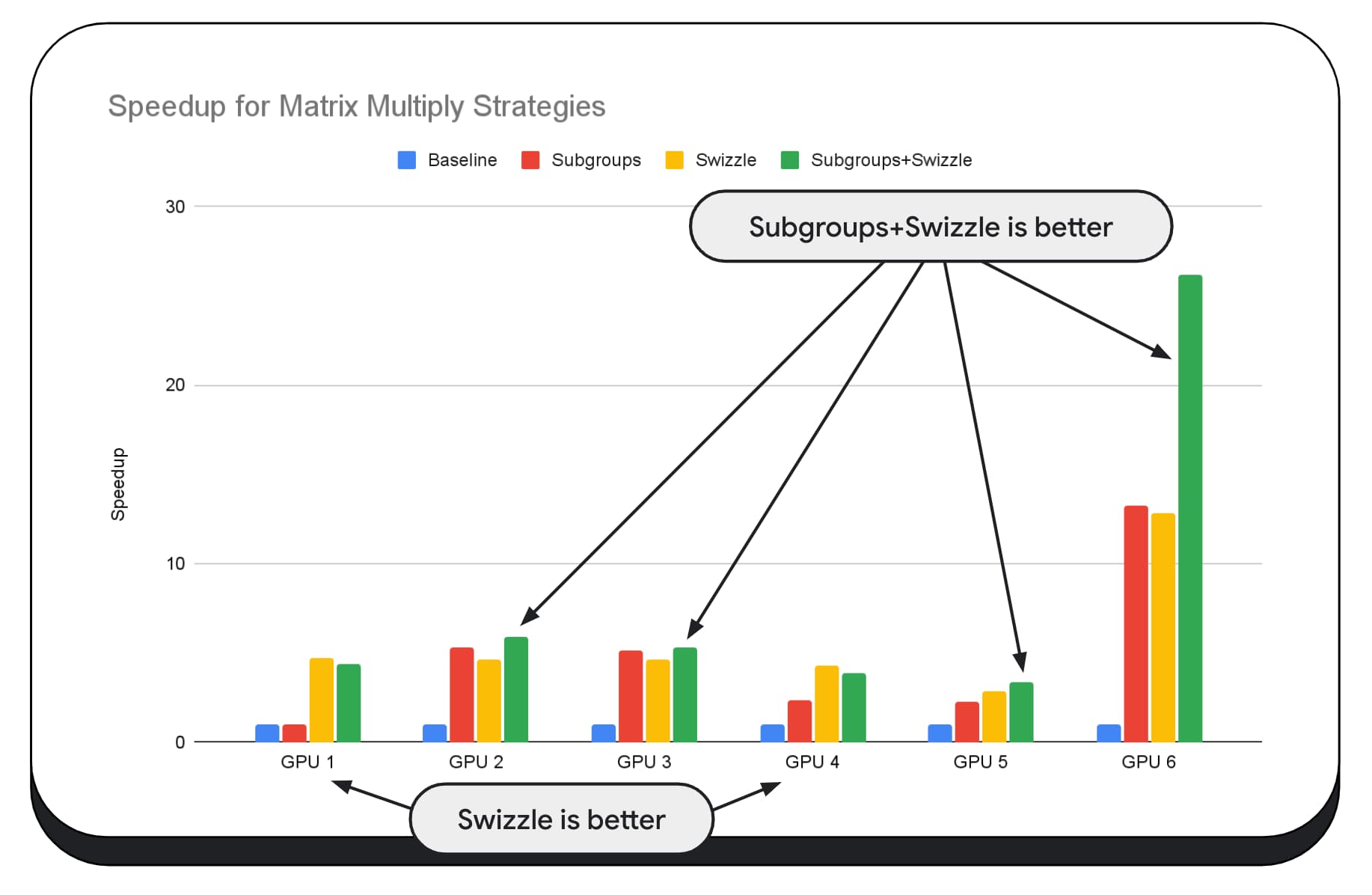
Dostosowanie i zoptymalizowanie algorytmów GPU pod kątem prawidłowego działania na każdym sprzęcie może wymagać dużego doświadczenia. Na szczęście wielu utalentowanych programistów pracuje nad bibliotekami i ramami programowymi wyższego poziomu, takimi jak Mediapipe, Transformers.js, Apache TVM, ONNX Runtime Web i inne.
Biblioteki i ramy są dobrze przygotowane do obsługi złożoności zarządzania różnymi architekturami GPU oraz generowania kodu dla konkretnej platformy, który będzie dobrze działać na kliencie.
Wnioski
Zespół Chrome nadal pracuje nad ulepszaniem standardów WebAssembly i WebGPU, aby ulepszać platformę internetową pod kątem zadań związanych z uczeniem maszynowym. Inwestujemy w szybsze operacje obliczeniowe, lepszą współpracę z różnymi standardami internetowymi i zapewnienie, że zarówno duże, jak i małe modele będą mogły działać wydajnie na różnych urządzeniach.
Naszym celem jest maksymalizacja możliwości platformy przy zachowaniu najlepszych cech internetu: zasięgu, użyteczności i mobilności. Nie robimy tego sami. Współpracujemy z innymi dostawcami przeglądarek w ramach W3C oraz z wielu programistami.
Podczas pracy z WebAssembly i WebGPU warto pamiętać o tych kwestiach:
- Wnioskowanie oparte na AI jest teraz dostępne w internecie na różnych urządzeniach. Daje to korzyści związane z działaniem na urządzeniach klienta, takie jak niższe koszty serwera, niskie opóźnienie i większa prywatność.
- Chociaż wiele omawianych funkcji jest istotnych przede wszystkim dla autorów frameworków, Twoje aplikacje również mogą na nich skorzystać bez nadmiernych kosztów.
- Standardy internetowe są płynne i stale ewoluują, dlatego zawsze chętnie poznamy Twoją opinię. Udostępnij swoje dane dotyczące WebAssembly i WebGPU.
Podziękowania
Dziękujemy zespołowi ds. grafiki internetowej firmy Intel, który odegrał kluczową rolę w rozwijaniu funkcji WebGPU f16 i zapakowanych liczb całkowitych w ramach funkcji dot. Dziękujemy innym członkom grup roboczych W3C ds. WebAssembly i WebGPU, w tym innym dostawcom przeglądarek.
Dziękujemy zespołom AI i ML zarówno w Google, jak i w społeczności open source za to, że są niesamowitymi partnerami. I oczywiście wszystkim naszym współpracownikom, którzy to wszystko umożliwili.