
이 문서는 더 빠른 웹 AI를 위한 WebAssembly 및 WebGPU 개선사항, 1부의 연속입니다. 계속하기 전에 이 게시물을 읽거나 IO 24에서 강연을 시청하는 것이 좋습니다.



WebGPU
WebGPU를 사용하면 웹 애플리케이션이 클라이언트의 GPU 하드웨어에 액세스하여 효율적이고 고도로 병렬화된 계산을 실행할 수 있습니다. Chrome에서 WebGPU를 출시한 이후 웹에서 인공지능 (AI) 및 머신러닝 (ML)의 놀라운 데모를 확인할 수 있었습니다.
예를 들어 Web Stable Diffusion은 AI를 사용하여 브라우저에서 직접 텍스트로 이미지를 생성할 수 있음을 보여주었습니다. 올해 초 Google의 자체 Mediapipe팀은 대규모 언어 모델 추론을 위한 실험적 지원을 발표했습니다.
다음 애니메이션은 Chrome에서 온디바이스로 완전히 실행되는 Google의 오픈소스 대규모 언어 모델 (LLM)인 Gemma를 실시간으로 보여줍니다.
다음 Hugging Face의 데모에서는 Meta의 Segment Anything 모델을 사용하여 클라이언트에서 완전히 고품질 객체 마스크를 생성합니다.
다음은 AI 및 ML을 위한 WebGPU의 강력한 기능을 보여주는 몇 가지 놀라운 프로젝트입니다. WebGPU를 사용하면 이러한 모델과 다른 모델을 CPU에서 실행할 때보다 훨씬 더 빠르게 실행할 수 있습니다.
Hugging Face의 텍스트 임베딩을 위한 WebGPU 벤치마크는 동일한 모델의 CPU 구현과 비교하여 엄청난 속도 향상을 보여줍니다. Apple M1 Max 노트북에서는 WebGPU가 30배 이상 빠르게 작동했습니다. WebGPU가 벤치마크를 120배 이상 가속화한다는 사용자도 있습니다.
AI 및 ML을 위한 WebGPU 기능 개선
WebGPU는 컴퓨팅 셰이더 지원 덕분에 수십억 개의 매개변수를 보유할 수 있는 AI 및 ML 모델에 적합합니다. 컴퓨팅 셰이더는 GPU에서 실행되며 대규모 데이터에서 병렬 배열 작업을 실행하는 데 도움이 됩니다.
지난 1년 동안 WebGPU에 이루어진 수많은 개선사항 중 웹에서 ML 및 AI 성능을 개선하기 위한 기능이 계속 추가되었습니다. 최근에는 16비트 부동 소수점 및 패킹된 정수 내적이라는 두 가지 새로운 기능을 출시했습니다.
16비트 부동 소수점
ML 워크로드에는 정밀도가 필요하지 않습니다. shader-f16는 WebGPU 셰이딩 언어에서 f16 유형을 사용할 수 있는 기능입니다. 이 부동 소수점 유형은 일반적인 32비트 대신 16비트를 사용합니다. f16은 범위가 더 작고 정밀도가 떨어지지만 많은 ML 모델에 충분합니다.
이 기능은 다음과 같은 몇 가지 방법으로 효율성을 높입니다.
메모리 감소: f16 요소가 있는 텐서는 공간의 절반을 차지하므로 메모리 사용량이 절반으로 줄어듭니다. GPU 계산은 메모리 대역폭에서 병목 현상이 발생하는 경우가 많으므로 메모리를 절반으로 줄이면 셰이더가 두 배 더 빠르게 실행될 수 있습니다. 기술적으로 메모리 대역폭을 절약하기 위해 f16이 필요하지는 않습니다. 데이터를 저장하고 나서 셰이더에서 계산을 위해 전체 f32로 확장할 수 있습니다. 하지만 GPU는 데이터를 압축하고 압축 해제하는 데 추가 컴퓨팅 성능을 사용합니다.
데이터 변환 감소: f16은 데이터 변환을 최소화하여 컴퓨팅을 적게 사용합니다. 정밀도가 낮은 데이터는 저장한 후 변환 없이 직접 사용할 수 있습니다.
동시 로드 증가: 최신 GPU는 GPU의 실행 단위에 더 많은 값을 동시에 맞출 수 있으므로 더 많은 수의 병렬 연산을 실행할 수 있습니다. 예를 들어 초당 최대 5조 개의 f32 부동 소수점 연산을 지원하는 GPU는 초당 10조 개의 f16 부동 소수점 연산을 지원할 수 있습니다.
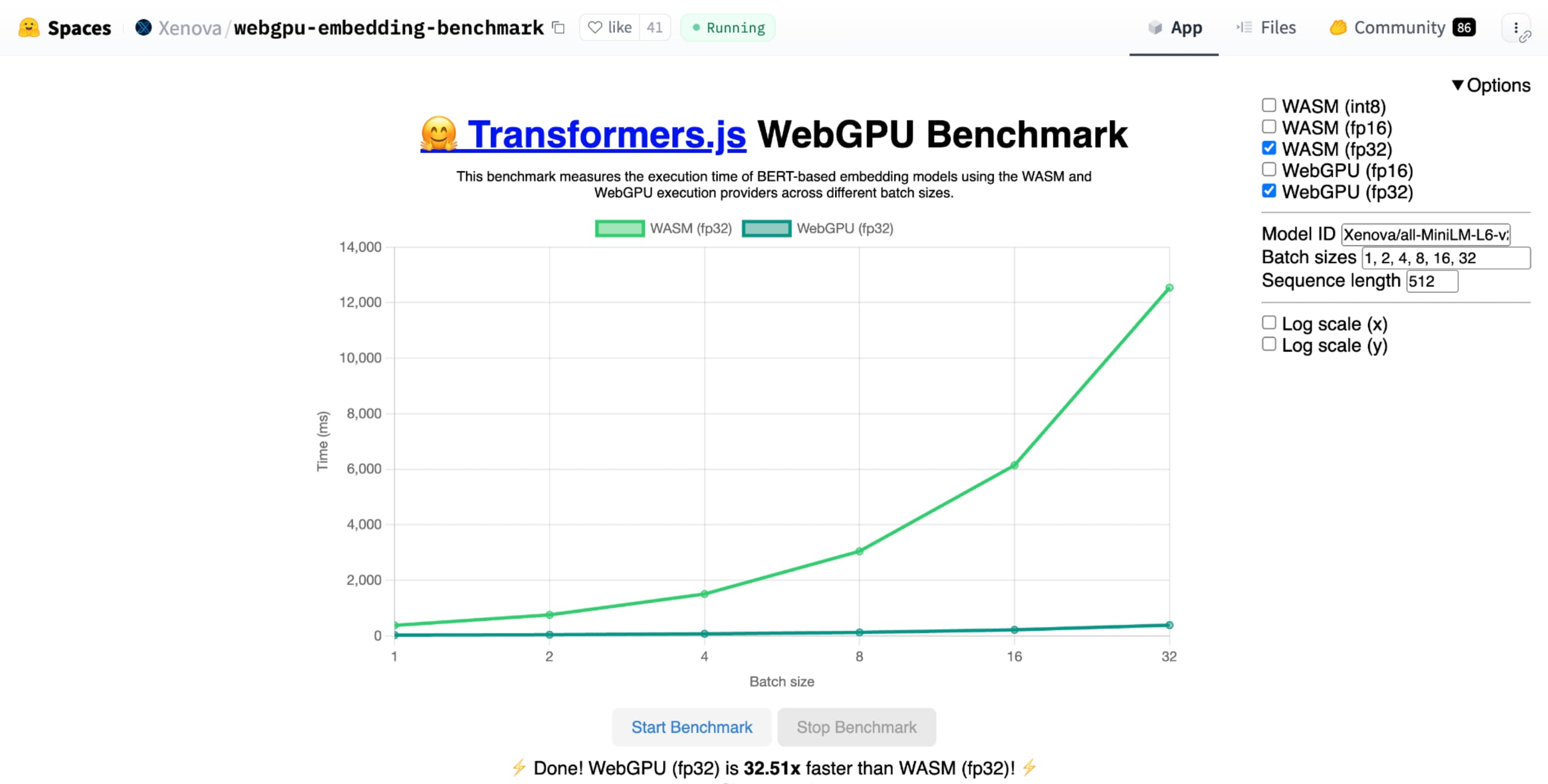
shader-f16를 사용하면 Hugging Face의 텍스트 임베딩을 위한 WebGPU 벤치마크 벤치마크가 Apple M1 Max 노트북에서 f32보다 3배 빠르게 벤치마크를 실행합니다.
WebLLM은 여러 대규모 언어 모델을 실행할 수 있는 프로젝트입니다. 오픈소스 머신러닝 컴파일러 프레임워크인 Apache TVM을 사용합니다.
Llama 3 80억 매개변수 모델을 사용하여 파리 여행을 계획해 달라고 WebLLM에 요청했습니다. 결과는 모델의 미리 채우기 단계에서 f16이 f32보다 2.1배 빠르다는 것을 보여줍니다. 디코딩 단계에서는 1.3배 더 빠릅니다.
애플리케이션은 먼저 GPU 어댑터가 f16을 지원하는지 확인하고, 사용 가능한 경우 GPU 기기를 요청할 때 이를 명시적으로 사용 설정해야 합니다. f16이 지원되지 않으면 requiredFeatures 배열에서 요청할 수 없습니다.
// main.js
const adapter = await navigator.gpu.requestAdapter();
const supportsF16 = adapter.features.has('shader-f16');
if (supportsF16) {
// Use f16.
const device = await adapter.requestDevice({
requiredFeatures: ['shader-f16'],
});
initApp(device);
}
그런 다음 WebGPU 셰이더에서 상단에 f16을 명시적으로 사용 설정해야 합니다. 그런 다음 다른 부동 소수점 데이터 유형과 마찬가지로 셰이더 내에서 자유롭게 사용할 수 있습니다.
// my-shader.wgsl
enable f16;
struct Data {
values : array<vec4<f16>>
}
@group(0) @binding(0) var<storage, read> data : Data;
@compute @workgroup_size(64) fn main(@builtin(global_invocation_id) gid : vec3u) {
let value : vec4<f16> = data.values[gid.x];
...
}
팩킹된 정수 내적
많은 모델은 여전히 8비트 정밀도 (f16의 절반)로도 잘 작동합니다. 이는 세분화 및 객체 인식을 위한 LLM 및 이미지 모델에서 많이 사용됩니다. 하지만 정밀도가 낮을수록 모델의 출력 품질이 저하되므로 8비트 양자화는 모든 애플리케이션에 적합하지는 않습니다.
8비트 값을 기본적으로 지원하는 GPU는 비교적 적습니다. 이때 팩킹된 정수 내적을 사용합니다. Chrome 123의 DP4a가 출시되었습니다.
최신 GPU에는 32비트 정수 2개를 사용하여 각각을 연속으로 패킹된 8비트 정수 4개로 해석하고 구성요소 간의 내적을 계산하는 특수 명령이 있습니다.
이는 매트릭스 곱셈 커널이 수많은 내적으로 구성되므로 AI 및 머신러닝에 특히 유용합니다.
예를 들어 4x8 행렬을 8x1 벡터와 곱해 보겠습니다. 이를 계산하려면 4개의 내적을 사용하여 출력 벡터의 각 값(A, B, C, D)을 계산해야 합니다.
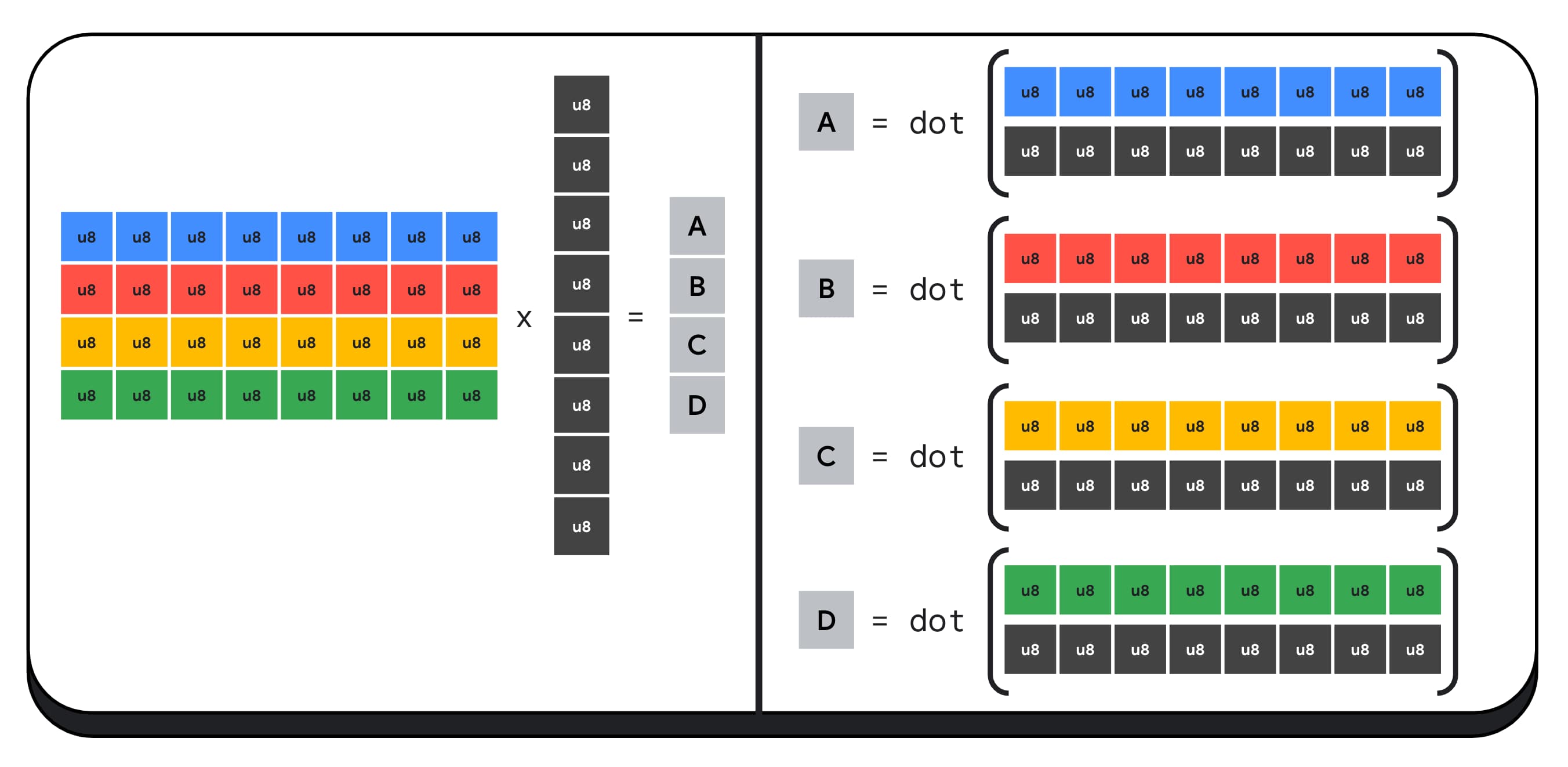
이러한 각 출력을 계산하는 프로세스는 동일합니다. 그중 하나를 계산하는 단계를 살펴보겠습니다. 계산을 시작하기 전에 먼저 8비트 정수 데이터를 산술을 실행할 수 있는 유형(예: f16)으로 변환해야 합니다. 그런 다음 요소별 곱셈을 실행하고 마지막으로 모든 곱셈식을 더합니다. 전체 행렬-벡터 곱셈의 경우 총 40회의 정수-부동 소수점 수 변환을 통해 데이터를 압축 해제하고 32회의 부동 소수점 수 곱셈, 28회의 부동 소수점 수 더하기를 실행합니다.
작업이 더 많은 대규모 매트릭스의 경우 팩킹된 정수 내적을 사용하면 작업량을 줄일 수 있습니다.
결과 벡터의 각 출력에 대해 WebGPU 셰이딩 언어 내장 dot4U8Packed를 사용하여 두 개의 패킹된 내적 연산을 실행한 다음 결과를 더합니다. 전체 행렬-벡터 곱셈에서 데이터 변환은 전혀 실행되지 않습니다. 8개의 패킹된 내적과 4개의 정수 덧셈을 실행합니다.
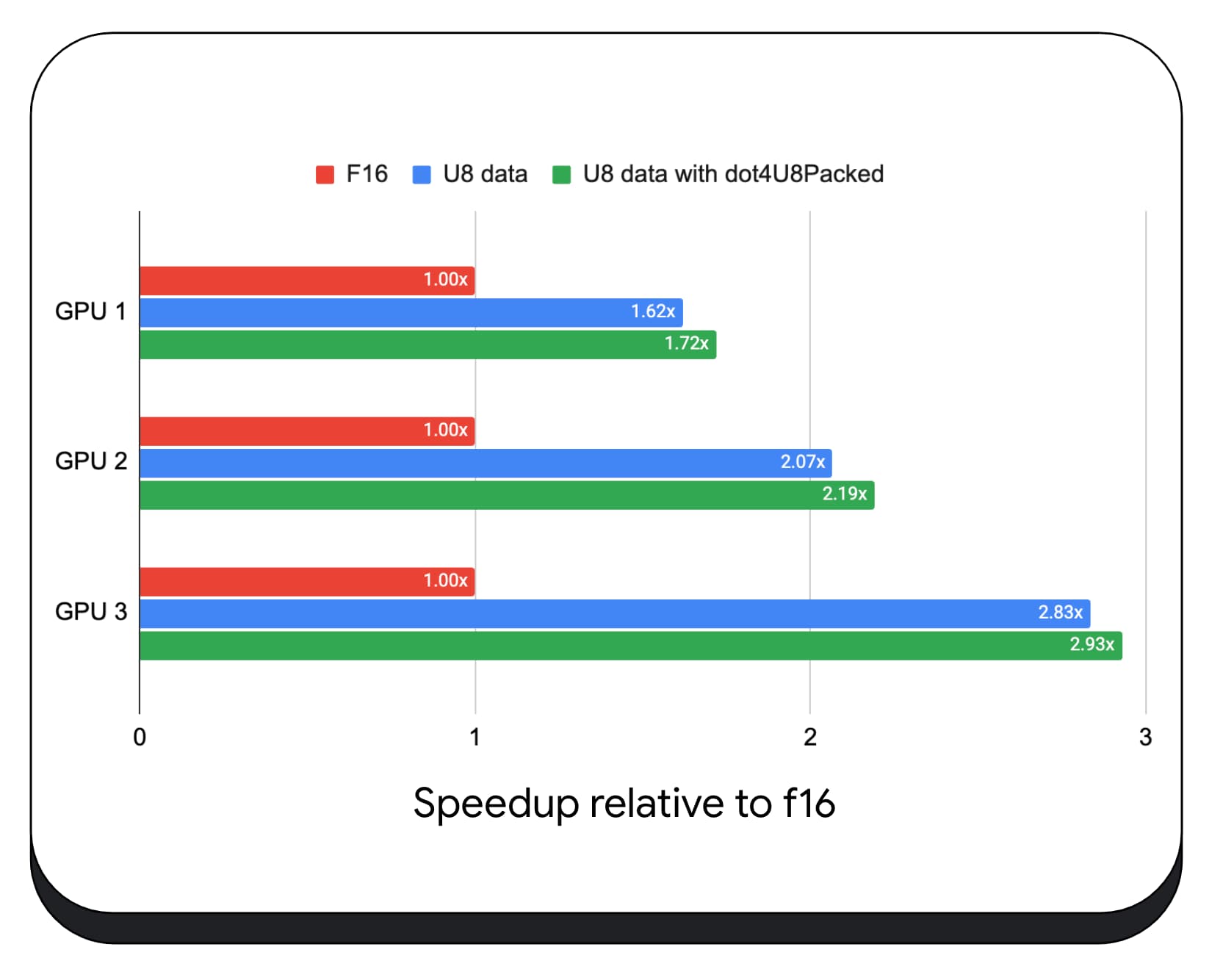
다양한 소비자 GPU에서 8비트 데이터를 사용한 패킹된 정수 내적을 테스트했습니다. 16비트 부동 소수점과 비교하면 8비트가 1.6~2.8배 더 빠릅니다. 패킹된 정수 내적을 추가로 사용하면 성능이 더욱 향상됩니다. 1.7~2.9배 더 빠릅니다.
wgslLanguageFeatures 속성으로 브라우저 지원을 확인합니다. GPU가 패킹된 내적을 기본적으로 지원하지 않는 경우 브라우저는 자체 구현을 polyfill합니다.
// main.js
if (navigator.gpu.wgslLanguageFeatures.has('packed_4x8_integer_dot_product')) {
// Use dot4U8Packed, dot4I8Packed builtin
// functions in the shaders.
}
다음 코드 스니펫 diff (차이)는 WebGPU 셰이더에서 패킹된 정수 곱을 사용하기 위해 필요한 변경사항을 강조 표시합니다.
이전: 부분 내적을 변수 `sum`에 누적하는 WebGPU 셰이더입니다. 루프가 끝나면 `sum` 은 벡터와 입력 행렬의 한 행 간의 전체 내적을 보유합니다.
// my-dot-product.wgsl @compute @workgroup_size(64) fn main(@builtin(global_invocation_id) gid : vec3u) { var sum : f16; let start = gid.x * uniforms.dim; for (var i = 0u; i < uniforms.dim; i++) { let v1 : vec4<f16> = vector.values[i]; let v2 : vec4<f16> = matrix.values[start + i]; sum += dot(v1, v2); } }
후: 패킹된 정수 내적을 사용하도록 작성된 WebGPU 셰이더입니다. 주요 차이점은 이 셰이더는 벡터와 행렬에서 4개의 부동 소수점 값을 로드하는 대신 단일 32비트 정수를 로드한다는 점입니다. 이 32비트 정수는 4개의 8비트 정수 값의 데이터를 보유합니다. 그런 다음 dot4U8Packed을 호출하여 두 값의 내적을 계산합니다.
// my-dot-product.wgsl
@compute @workgroup_size(64)
fn main(@builtin(global_invocation_id) gid : vec3u) {
var sum : f32;
let start = gid.x * uniforms.dim;
for (var i = 0u; i < uniforms.dim; i++) {
let v1 : u32 = vector.values[i];
let v2 : u32 = matrix.values[start + i];
sum += dot4U8Packed(v1, v2);
}
}
16비트 부동 소수점 및 패킹된 정수 내적은 모두 Chrome에 제공되는 AI 및 ML 가속 기능입니다. 16비트 부동 소수점은 하드웨어가 지원하는 경우 사용할 수 있으며 Chrome은 모든 기기에서 압축된 정수 내적을 구현합니다.
지금 Chrome 안정화 버전에서 이러한 기능을 사용하여 성능을 개선할 수 있습니다.
제안된 기능
향후 하위 그룹과 협력형 행렬 곱셈이라는 두 가지 기능을 추가로 살펴볼 예정입니다.
하위 그룹 기능을 사용하면 SIMD 수준의 병렬 처리가 16개가 넘는 숫자의 합계와 같은 집합 수학 연산을 통신하거나 실행할 수 있습니다. 이를 통해 교차 스레드 데이터를 효율적으로 공유할 수 있습니다. 하위 그룹은 최신 GPU API에서 다양한 이름과 약간 다른 형식으로 지원됩니다.
공통 세트를 WebGPU 표준화 그룹에 제출한 제안으로 정리했습니다. 또한 실험 플래그를 사용하여 Chrome에서 하위 그룹의 프로토타입을 제작하고 초기 결과를 논의에 반영했습니다. 주요 문제는 이식 가능한 동작을 보장하는 방법입니다.
협력형 행렬 곱셈은 최근에 GPU에 추가된 기능입니다. 대규모 행렬 곱셈은 여러 개의 작은 행렬 곱셈으로 분할할 수 있습니다. 협력형 행렬 곱셈은 단일 논리 단계에서 이러한 작은 고정 크기 블록에 곱셈을 실행합니다. 이 단계에서 스레드 그룹이 효율적으로 협력하여 결과를 계산합니다.
Google은 기본 GPU API의 지원을 조사했으며 WebGPU 표준화 그룹에 제안서를 제출할 계획입니다. 하위 그룹과 마찬가지로 대부분의 논의는 이식성에 관한 내용이 될 것으로 예상됩니다.
하위 그룹 작업의 성능을 평가하기 위해 실제 애플리케이션에서 하위 그룹에 대한 실험적 지원을 MediaPipe에 통합하고 하위 그룹 작업을 위한 Chrome의 프로토타입으로 테스트했습니다.
대규모 언어 모델의 미리 채우기 단계의 GPU 커널에서 하위 그룹을 사용했으므로 미리 채우기 단계의 속도 향상만 보고합니다. Intel GPU에서는 하위 그룹이 기준보다 2.5배 더 빠르게 실행됩니다. 그러나 이러한 개선사항은 GPU마다 일관되지 않습니다.
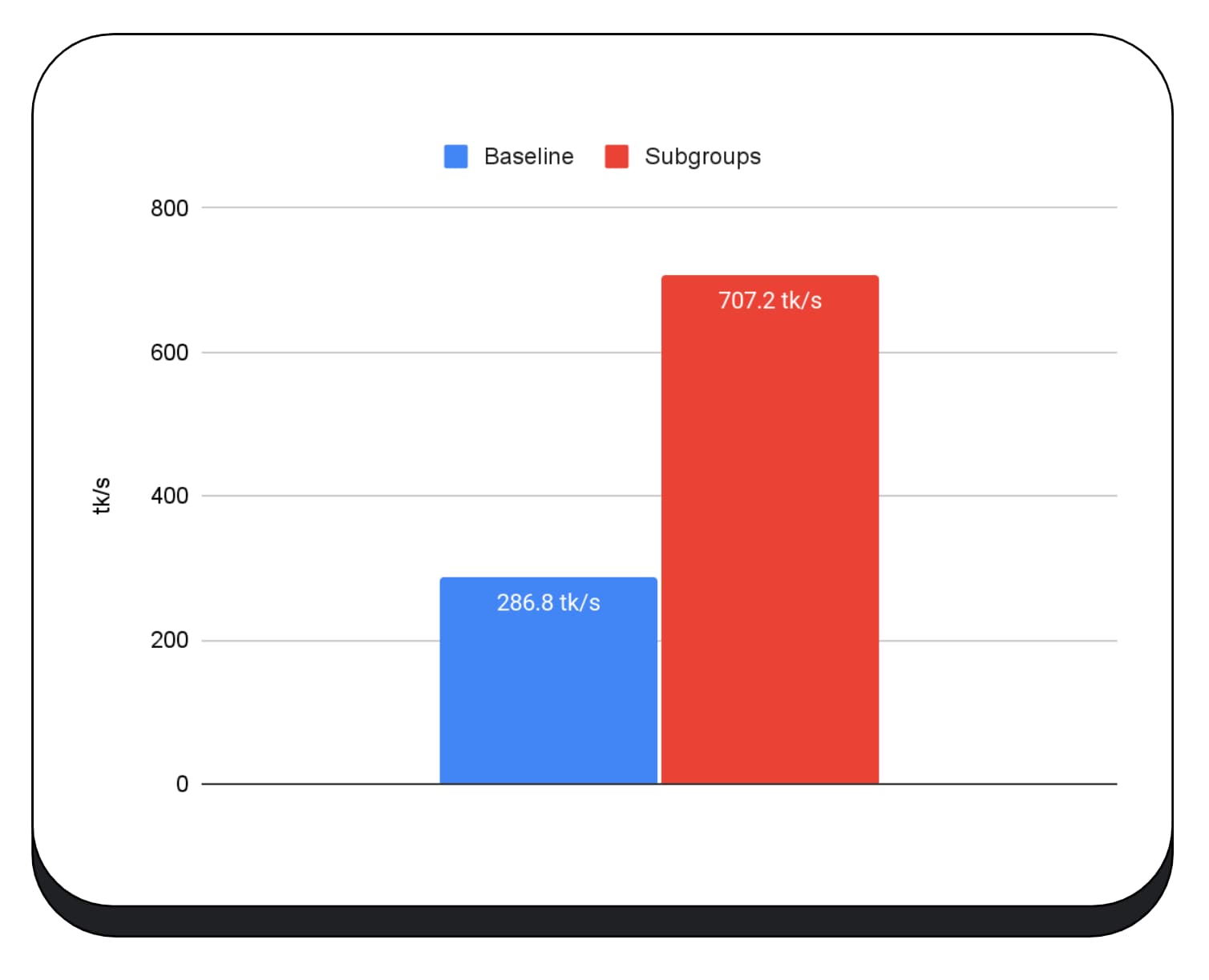
다음 차트는 여러 소비자 GPU에서 행렬 곱셈 마이크로벤치마크를 최적화하기 위해 하위 그룹을 적용한 결과를 보여줍니다. 행렬 곱셈은 대규모 언어 모델에서 가장 무거운 작업 중 하나입니다. 데이터에 따르면 많은 GPU에서 하위 그룹이 속도를 기준점의 2배, 5배, 심지어 13배까지 높여 줍니다. 하지만 첫 번째 GPU에서는 하위 그룹이 전혀 개선되지 않았습니다.
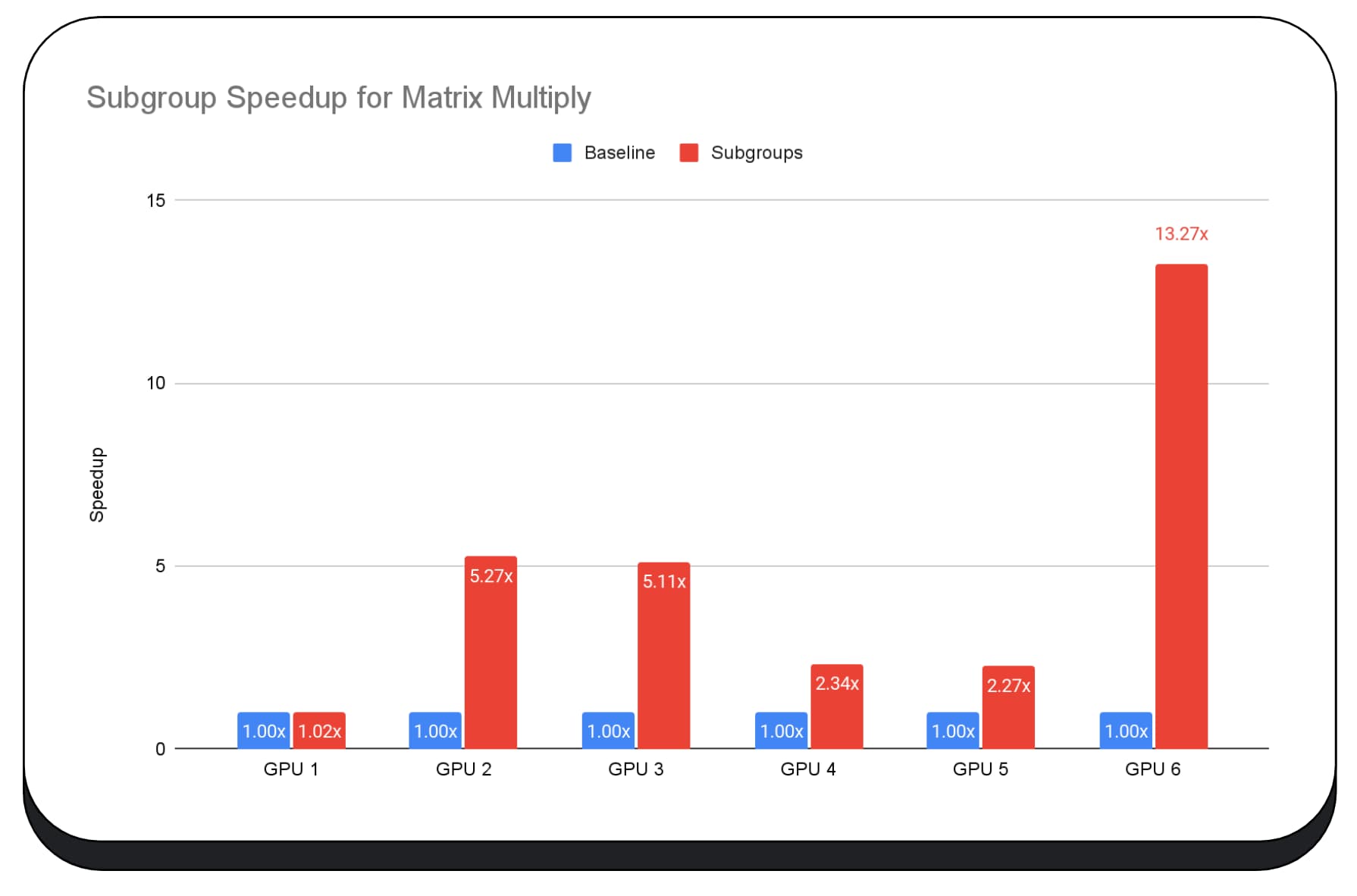
GPU 최적화가 어렵습니다.
궁극적으로 GPU를 최적화하는 가장 좋은 방법은 클라이언트가 제공하는 GPU에 따라 다릅니다. 멋진 새 GPU 기능을 사용한다고 해서 항상 기대한 만큼의 성과를 얻을 수 있는 것은 아닙니다. 여러 복잡한 요소가 작용할 수 있기 때문입니다. 한 GPU에서 최적의 최적화 전략이 다른 GPU에서는 최적의 전략이 아닐 수 있습니다.
GPU의 컴퓨팅 스레드를 최대한 활용하면서 메모리 대역폭을 최소화하려고 합니다.
메모리 액세스 패턴도 매우 중요할 수 있습니다. GPU는 컴퓨팅 스레드가 하드웨어에 최적화된 패턴으로 메모리에 액세스할 때 훨씬 더 우수한 성능을 발휘하는 경향이 있습니다. 중요: GPU 하드웨어에 따라 성능 특성이 다를 수 있습니다. GPU에 따라 다른 최적화를 실행해야 할 수 있습니다.
다음 차트에서는 동일한 행렬 곱셈 알고리즘을 사용했지만 다양한 최적화 전략의 영향과 다양한 GPU 간의 복잡도 및 변이를 더 잘 보여주기 위해 다른 측정기준을 추가했습니다. 여기에서 'Swizzle'라는 새로운 기법을 도입했습니다. Swizzle은 메모리 액세스 패턴을 하드웨어에 더 적합하도록 최적화합니다.
메모리 스위즐이 상당한 영향을 미치는 것을 볼 수 있습니다. 경우에 따라 하위 그룹보다 더 큰 영향을 미치기도 합니다. GPU 6에서는 스위즐이 12배의 속도 향상을 제공하는 반면 하위 그룹은 13배의 속도 향상을 제공합니다. 이를 합하면 놀라운 26배의 속도 향상을 얻을 수 있습니다. 다른 GPU의 경우 스위즐과 하위 그룹을 결합하면 둘 중 하나만 사용할 때보다 성능이 향상되는 경우가 있습니다. 다른 GPU에서는 스위즐만 사용하면 가장 좋은 성능을 얻을 수 있습니다.
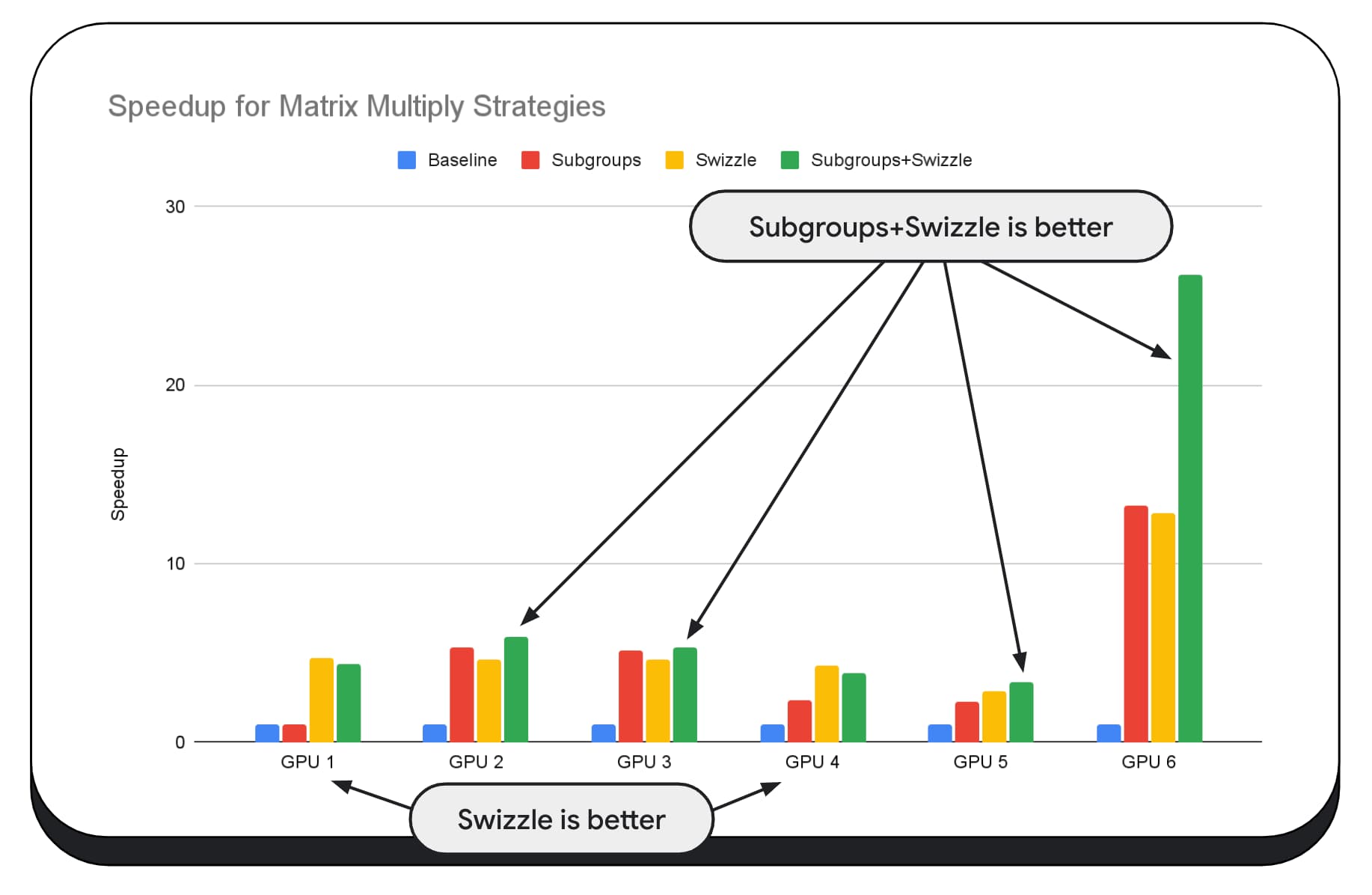
모든 하드웨어에서 잘 작동하도록 GPU 알고리즘을 조정하고 최적화하려면 상당한 전문 지식이 필요할 수 있습니다. 하지만 다행히 Mediapipe, Transformers.js, Apache TVM, ONNX Runtime Web 등 상위 수준의 라이브러리 프레임워크에 많은 재능이 투입되고 있습니다.
라이브러리와 프레임워크는 다양한 GPU 아키텍처를 관리하고 클라이언트에서 잘 실행되는 플랫폼별 코드를 생성하는 복잡성을 처리하는 데 적합합니다.
요약
Chrome팀은 머신러닝 워크로드를 위한 웹 플랫폼을 개선하기 위해 WebAssembly 및 WebGPU 표준을 지속적으로 발전시키고 있습니다. Google은 더 빠른 컴퓨팅 프리미티브, 웹 표준 간의 더 나은 상호 운용성, 크고 작은 모델이 여러 기기에서 효율적으로 실행될 수 있도록 하는 데 투자하고 있습니다.
Google의 목표는 웹의 장점인 도달범위, 사용성, 휴대성을 유지하면서 플랫폼의 기능을 극대화하는 것입니다. YouTube는 혼자가 아닙니다. Google은 W3C의 다른 브라우저 공급업체 및 여러 개발 파트너와 협력하고 있습니다.
WebAssembly 및 WebGPU를 사용할 때 다음 사항에 유의하시기 바랍니다.
- 이제 웹에서 여러 기기에서 AI 추론을 사용할 수 있습니다. 이렇게 하면 서버 비용 절감, 지연 시간 단축, 개인 정보 보호 강화 등 클라이언트 기기에서 실행할 때의 이점을 누릴 수 있습니다.
- 논의된 많은 기능은 주로 프레임워크 작성자와 관련이 있지만 애플리케이션에서도 큰 오버헤드 없이 이점을 얻을 수 있습니다.
- 웹 표준은 유동적이고 진화 중이며 Google은 항상 의견을 기다리고 있습니다. WebAssembly 및 WebGPU에 대한 의견을 공유해 주세요.
감사의 말씀
WebGPU f16 및 패킹된 정수 내적 기능을 추진하는 데 중요한 역할을 한 Intel 웹 그래픽팀에 감사드립니다. 다른 브라우저 공급업체를 포함하여 W3C의 WebAssembly 및 WebGPU 작업 그룹의 다른 회원에게 감사드립니다.
Google과 오픈소스 커뮤니티의 AI 및 ML팀에 감사드립니다. 그리고 이 모든 것을 가능하게 해준 모든 팀원들에게도 감사의 인사를 전합니다.