
این سند ادامه پیشرفتهای WebAssembly و WebGPU برای هوش مصنوعی وب سریعتر، بخش 1 است. توصیه می کنیم قبل از ادامه این پست را بخوانید یا سخنرانی را در IO 24 تماشا کنید .



WebGPU
WebGPU به برنامه های کاربردی وب امکان دسترسی به سخت افزار GPU مشتری را برای انجام محاسبات کارآمد و بسیار موازی می دهد. از زمان راهاندازی WebGPU در کروم ، شاهد نمایشهای باورنکردنی هوش مصنوعی (AI) و یادگیری ماشینی (ML) در وب هستیم.
برای مثال، Web Stable Diffusion نشان داد که میتوان از هوش مصنوعی برای تولید تصاویر از متن، مستقیماً در مرورگر استفاده کرد. در اوایل سال جاری، تیم Mediapipe خود گوگل ، پشتیبانی آزمایشی را برای استنتاج مدل زبان بزرگ منتشر کرد.
انیمیشن زیر Gemma ، مدل زبان بزرگ منبع باز Google (LLM) را نشان می دهد که به طور کامل روی دستگاه در کروم اجرا می شود، در زمان واقعی.
نسخه نمایشی زیر از Hugging Face از Meta's Segment Anything Model ماسک های شی با کیفیت بالا را به طور کامل بر روی مشتری تولید می کند.
اینها تنها چند پروژه شگفت انگیز است که قدرت WebGPU را برای هوش مصنوعی و ML به نمایش می گذارد. WebGPU به این مدل ها و سایر مدل ها اجازه می دهد تا به طور قابل توجهی سریعتر از آنچه می توانند روی CPU اجرا شوند.
معیار WebGPU Hugging Face برای جاسازی متن، در مقایسه با یک CPU از همان مدل، سرعتهای فوقالعادهای را نشان میدهد. در لپتاپ Apple M1 Max، WebGPU بیش از 30 برابر سریعتر بود. برخی دیگر گزارش کرده اند که WebGPU این معیار را بیش از 120 برابر تسریع می کند.
بهبود ویژگی های WebGPU برای هوش مصنوعی و ML
WebGPU برای مدلهای هوش مصنوعی و ML که به لطف پشتیبانی از شیدرهای محاسباتی میتوانند میلیاردها پارامتر داشته باشند، عالی است. شیدرهای محاسباتی روی GPU اجرا می شوند و به اجرای عملیات آرایه موازی روی حجم زیادی از داده کمک می کنند.
در میان پیشرفتهای متعدد WebGPU در سال گذشته، ما به افزودن قابلیتهای بیشتری برای بهبود عملکرد ML و AI در وب ادامه دادهایم. اخیراً دو ویژگی جدید راه اندازی کردیم: ممیز شناور 16 بیتی و محصولات نقطه صحیح بسته بندی شده.
ممیز شناور 16 بیتی
به یاد داشته باشید، بارهای کاری ML نیازی به دقت ندارند . shader-f16 قابلیتی است که امکان استفاده از نوع f16 را در زبان سایه زنی WebGPU فراهم می کند. این نوع ممیز شناور به جای 32 بیت معمول، 16 بیت می گیرد. f16 برد کمتری دارد و دقت کمتری دارد، اما برای بسیاری از مدل های ML این کافی است.
این ویژگی به چند روش کارایی را افزایش می دهد:
کاهش حافظه : تانسورهای دارای عناصر f16 نیمی از فضا را اشغال میکنند که استفاده از حافظه را به نصف کاهش میدهد. محاسبات GPU اغلب در پهنای باند حافظه با تنگنا مواجه می شوند، بنابراین نیمی از حافظه اغلب به این معنی است که شیدرها دو برابر سریعتر اجرا می شوند. از نظر فنی، برای صرفه جویی در پهنای باند حافظه به f16 نیاز ندارید. این امکان وجود دارد که داده ها را در قالبی با دقت کم ذخیره کنید و سپس برای محاسبه آن را به f32 کامل در سایه زن گسترش دهید. اما، GPU قدرت محاسباتی بیشتری را برای بسته بندی و باز کردن داده ها صرف می کند.
کاهش تبدیل داده : f16 از محاسبات کمتری با به حداقل رساندن تبدیل داده استفاده می کند. داده های با دقت پایین را می توان ذخیره کرد و سپس مستقیماً بدون تبدیل استفاده کرد.
افزایش موازی کاری : GPUهای مدرن قادرند مقادیر بیشتری را به طور همزمان در واحدهای اجرایی GPU جای دهند و به آن اجازه می دهد تعداد بیشتری از محاسبات موازی را انجام دهد. به عنوان مثال، یک GPU که تا 5 تریلیون عملیات ممیز شناور f32 در ثانیه را پشتیبانی می کند، ممکن است از 10 تریلیون عملیات ممیز شناور f16 در هر ثانیه پشتیبانی کند.
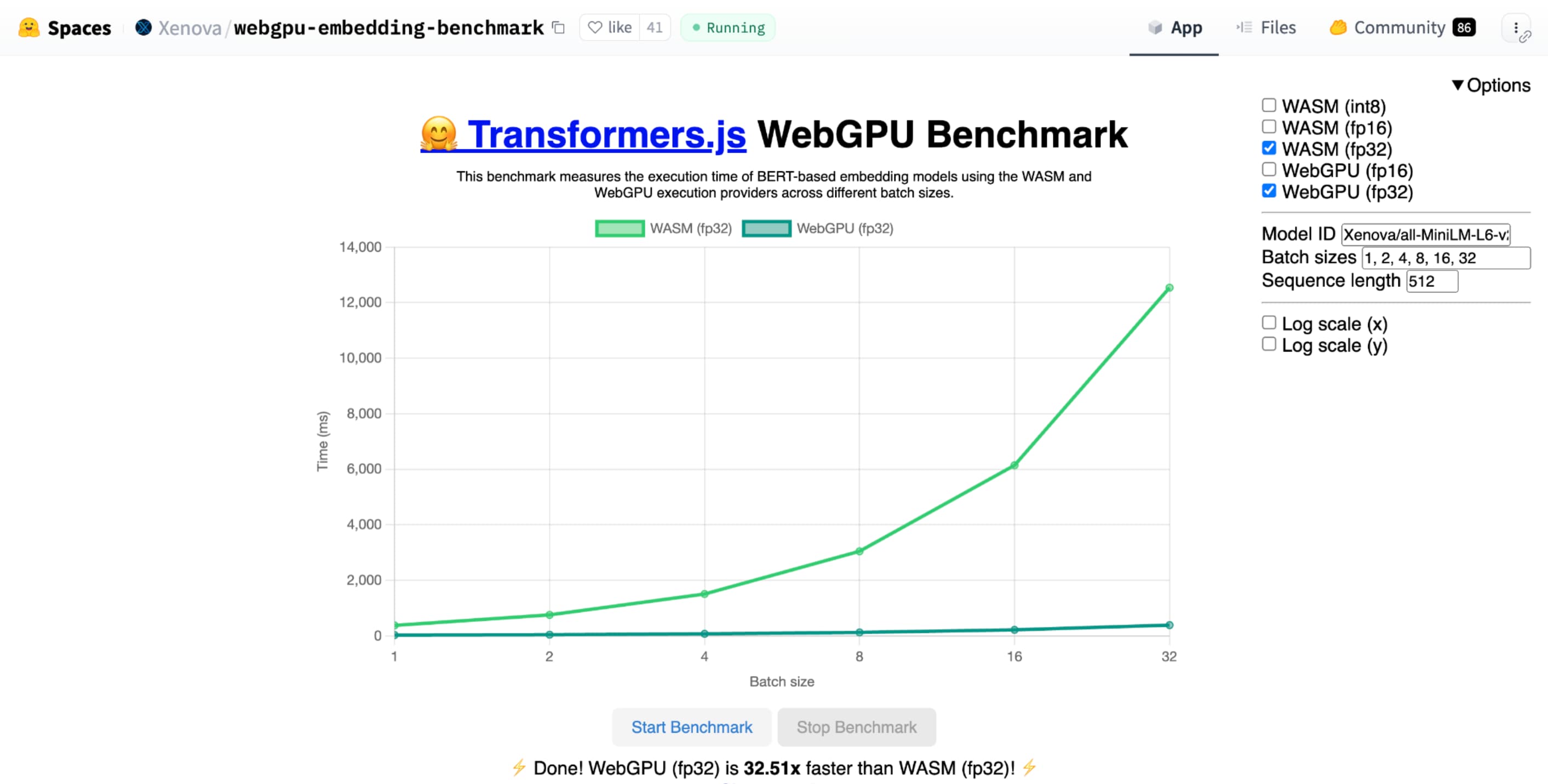
shader-f16 ، معیار WebGPU Hugging Face برای معیار جاسازی متن، این معیار را 3 برابر سریعتر از f32 در لپتاپ Apple M1 Max اجرا میکند.WebLLM پروژه ای است که می تواند چندین مدل زبان بزرگ را اجرا کند. از Apache TVM ، یک چارچوب کامپایلر یادگیری ماشین منبع باز استفاده می کند.
از WebLLM خواستم تا با استفاده از مدل پارامتر هشت میلیاردی Llama 3 برای سفر به پاریس برنامه ریزی کند. نتایج نشان می دهد که در مرحله پیش پر کردن مدل، f16 2.1 برابر سریعتر از f32 است. در مرحله رمزگشایی، بیش از 1.3 برابر سریعتر است.
برنامهها ابتدا باید تأیید کنند که آداپتور GPU از f16 پشتیبانی میکند و اگر در دسترس است، هنگام درخواست دستگاه GPU، آن را به صراحت فعال کنید. اگر f16 پشتیبانی نمیشود، نمیتوانید آن را در آرایه requiredFeatures درخواست کنید.
// main.js
const adapter = await navigator.gpu.requestAdapter();
const supportsF16 = adapter.features.has('shader-f16');
if (supportsF16) {
// Use f16.
const device = await adapter.requestDevice({
requiredFeatures: ['shader-f16'],
});
initApp(device);
}
سپس، در سایه زن های WebGPU خود، باید به صراحت f16 را در بالا فعال کنید. پس از آن، شما آزاد هستید که از آن در سایه زن مانند هر نوع داده شناور دیگری استفاده کنید.
// my-shader.wgsl
enable f16;
struct Data {
values : array<vec4<f16>>
}
@group(0) @binding(0) var<storage, read> data : Data;
@compute @workgroup_size(64) fn main(@builtin(global_invocation_id) gid : vec3u) {
let value : vec4<f16> = data.values[gid.x];
...
}
محصولات نقطه صحیح بسته بندی شده
بسیاری از مدلها هنوز با 8 بیت دقت (نیم f16) به خوبی کار میکنند. این در بین LLM ها و مدل های تصویر برای تقسیم بندی و تشخیص اشیا محبوب است. همانطور که گفته شد، کیفیت خروجی برای مدلها با دقت کمتری کاهش مییابد، بنابراین کوانتیزاسیون 8 بیتی برای هر کاربرد مناسب نیست.
تعداد نسبتا کمی از GPU ها به طور بومی از مقادیر 8 بیتی پشتیبانی می کنند. اینجاست که محصولات نقطه صحیح بسته بندی شده وارد می شوند. ما DP4a را در Chrome 123 ارسال کردیم.
پردازندههای گرافیکی مدرن دستورالعملهای خاصی برای گرفتن دو عدد صحیح 32 بیتی دارند، هر کدام را به عنوان 4 عدد صحیح 8 بیتی متوالی تفسیر میکنند و محصول نقطهای را بین اجزای آنها محاسبه میکنند.
این به ویژه برای هوش مصنوعی و یادگیری ماشین مفید است زیرا هسته های ضرب ماتریس از محصولات نقطه بسیار بسیار زیادی تشکیل شده اند.
برای مثال، بیایید یک ماتریس 4 در 8 را با یک بردار 8 x 1 ضرب کنیم. محاسبه این شامل گرفتن 4 محصول نقطه برای محاسبه هر یک از مقادیر در بردار خروجی است. الف، ب، ج و د.
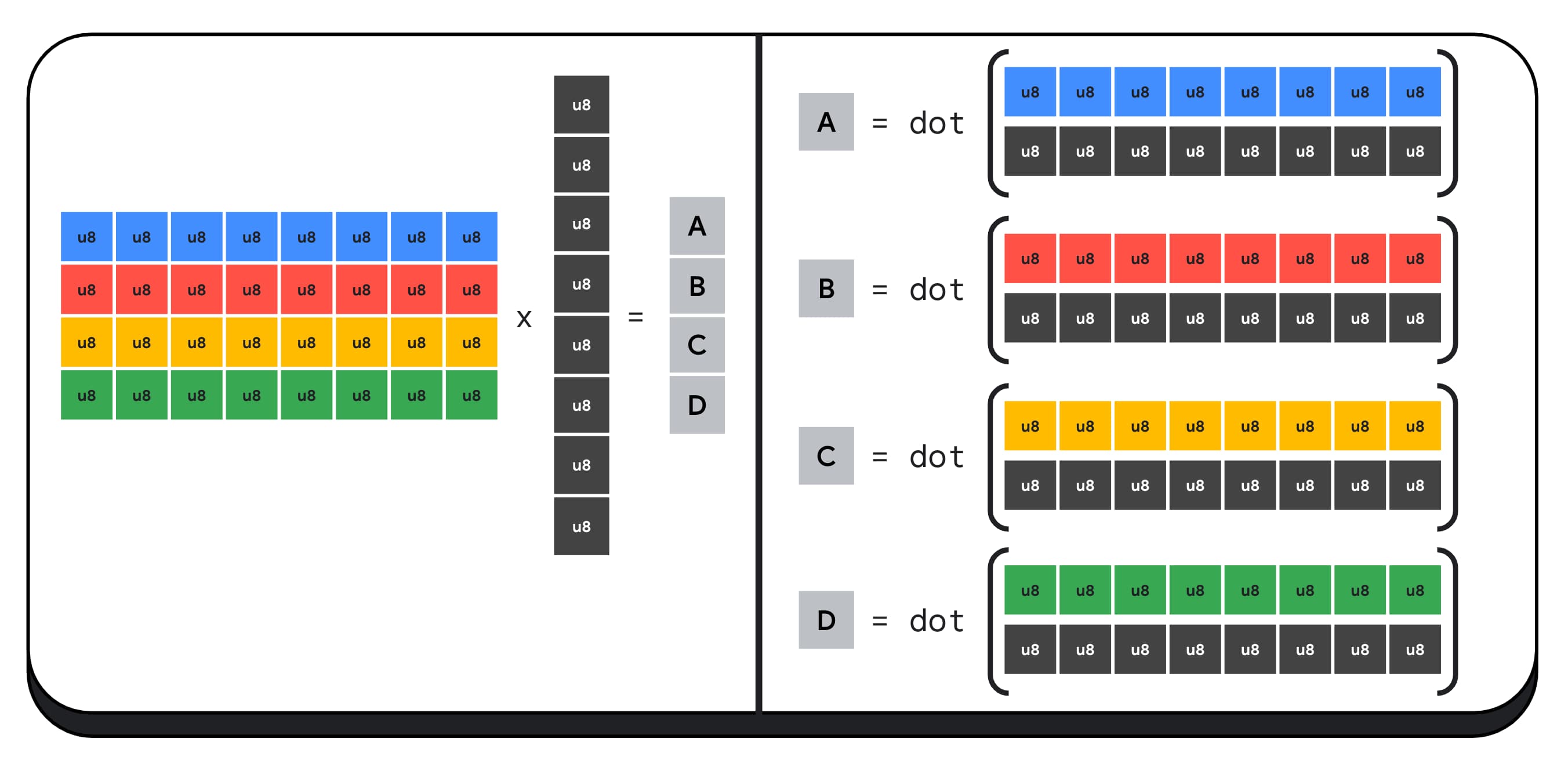
فرآیند محاسبه هر یک از این خروجی ها یکسان است. ما به مراحل مربوط به محاسبه یکی از آنها نگاه خواهیم کرد. قبل از هر محاسباتی، ابتدا باید داده های عدد صحیح 8 بیتی را به نوعی تبدیل کنیم که بتوانیم با آن محاسبات انجام دهیم، مانند f16. سپس، یک ضرب المان را اجرا می کنیم و در نهایت، همه محصولات را با هم جمع می کنیم. در مجموع، برای کل ضرب ماتریس-بردار، 40 تبدیل اعداد صحیح به شناور برای باز کردن داده ها، 32 ضرب شناور و 28 جمع شناور انجام می دهیم.
برای ماتریس های بزرگتر با عملیات بیشتر، محصولات نقطه صحیح بسته بندی شده می توانند به کاهش میزان کار کمک کنند.
برای هر یک از خروجیهای بردار نتیجه، دو عملیات محصول نقطههای بستهشده را با استفاده از WebGPU Shading Language داخلی dot4U8Packed انجام میدهیم و سپس نتایج را با هم اضافه میکنیم. در مجموع، برای کل ضرب ماتریس-بردار، هیچ تبدیل داده ای انجام نمی دهیم. ما 8 محصول نقطه بسته و 4 عدد صحیح اضافه می کنیم.
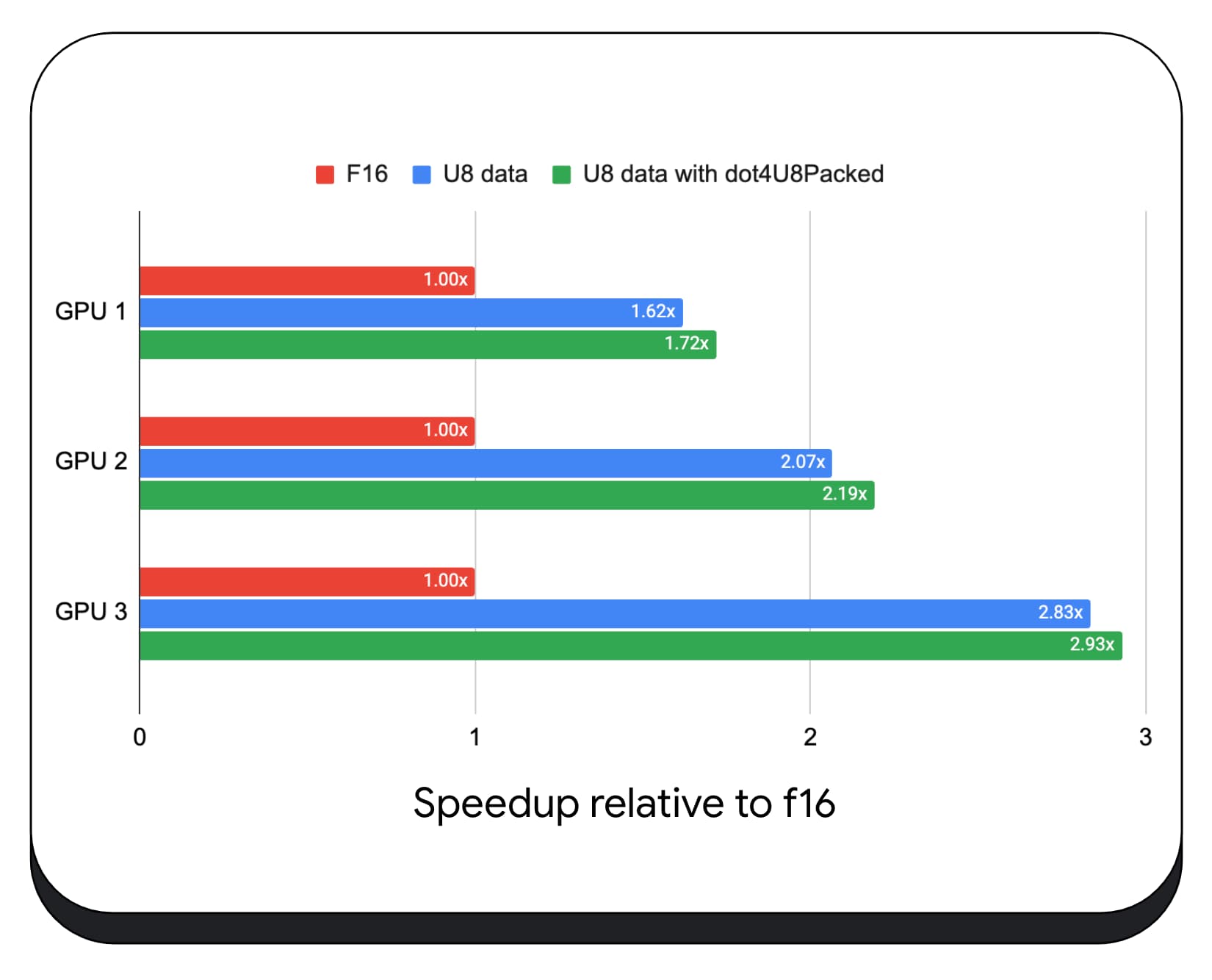
ما محصولات نقطه صحیح بسته بندی شده را با داده های 8 بیتی روی انواع پردازنده های گرافیکی مصرف کننده آزمایش کردیم. در مقایسه با ممیز شناور 16 بیتی، می بینیم که 8 بیت 1.6 تا 2.8 برابر سریعتر است. وقتی از محصولات نقطه صحیح بسته بندی شده نیز استفاده می کنیم، عملکرد حتی بهتر می شود. 1.7 تا 2.9 برابر سریعتر است.
پشتیبانی مرورگر را با ویژگی wgslLanguageFeatures بررسی کنید. اگر GPU به طور بومی از محصولات packed dot پشتیبانی نمیکند، مرورگر پیادهسازی خود را به صورت polyfill میکند.
// main.js
if (navigator.gpu.wgslLanguageFeatures.has('packed_4x8_integer_dot_product')) {
// Use dot4U8Packed, dot4I8Packed builtin
// functions in the shaders.
}
تفاوت قطعه کد زیر (تفاوت) تغییرات مورد نیاز برای استفاده از محصولات عدد صحیح بسته بندی شده در یک سایه زن WebGPU را برجسته می کند.
قبل - یک سایه زن WebGPU که محصولات نقطه جزئی را در متغیر "sum" جمع می کند. در انتهای حلقه، «sum» حاصل ضرب نقطه کامل را بین یک بردار و یک ردیف از ماتریس ورودی نگه میدارد.
// my-dot-product.wgsl @compute @workgroup_size(64) fn main(@builtin(global_invocation_id) gid : vec3u) { var sum : f16; let start = gid.x * uniforms.dim; for (var i = 0u; i < uniforms.dim; i++) { let v1 : vec4<f16> = vector.values[i]; let v2 : vec4<f16> = matrix.values[start + i]; sum += dot(v1, v2); } }
بعد - یک سایه زن WebGPU که برای استفاده از محصولات نقطه صحیح بسته بندی شده نوشته شده است. تفاوت اصلی این است که به جای بارگذاری 4 مقدار شناور خارج از بردار و ماتریس، این سایه زن یک عدد صحیح 32 بیتی را بارگذاری می کند. این عدد صحیح 32 بیتی داده های چهار مقدار صحیح 8 بیتی را در خود نگه می دارد. سپس، dot4U8Packed را فراخوانی می کنیم تا حاصل ضرب نقطه ای دو مقدار را محاسبه کنیم.
// my-dot-product.wgsl
@compute @workgroup_size(64)
fn main(@builtin(global_invocation_id) gid : vec3u) {
var sum : f32;
let start = gid.x * uniforms.dim;
for (var i = 0u; i < uniforms.dim; i++) {
let v1 : u32 = vector.values[i];
let v2 : u32 = matrix.values[start + i];
sum += dot4U8Packed(v1, v2);
}
}
هم محصولات ممیز شناور 16 بیتی و هم محصولات نقطه صحیح بسته بندی شده، ویژگی های ارسال شده در کروم هستند که هوش مصنوعی و ML را تسریع می کنند. ممیز شناور 16 بیتی زمانی در دسترس است که سختافزار از آن پشتیبانی کند، و Chrome محصولات نقطهصحیح بستهبندی شده را در همه دستگاهها پیادهسازی میکند.
امروز میتوانید از این ویژگیها در Chrome Stable برای دستیابی به عملکرد بهتر استفاده کنید.
ویژگی های پیشنهادی
به آینده، ما دو ویژگی دیگر را بررسی می کنیم: زیرگروه ها و ضرب ماتریس تعاونی.
ویژگی زیرگروهها موازیسازی سطح SIMD را برای برقراری ارتباط یا انجام عملیات ریاضی جمعی، مانند مجموع بیش از 16 عدد، قادر میسازد. این امکان به اشتراک گذاری داده های بین رشته ای کارآمد را فراهم می کند. زیرگروهها در APIهای GPUهای مدرن، با نامهای متفاوت و در اشکال کمی متفاوت پشتیبانی میشوند.
ما مجموعه مشترک را در یک پیشنهاد تقطیر کرده ایم که به گروه استانداردسازی WebGPU برده ایم. و، ما زیرگروههایی را در کروم در پشت پرچم آزمایشی نمونهسازی کردهایم و نتایج اولیه خود را وارد بحث کردهایم. مسئله اصلی نحوه اطمینان از رفتار قابل حمل است.
ضرب ماتریس تعاونی جدیدتر به GPU اضافه شده است. یک ضرب ماتریس بزرگ را می توان به چندین ضرب ماتریس کوچکتر تقسیم کرد. ضرب ماتریس تعاونی ضربات را روی این بلوک های کوچکتر با اندازه ثابت در یک مرحله منطقی انجام می دهد. در این مرحله، گروهی از نخ ها به طور موثر برای محاسبه نتیجه همکاری می کنند.
ما پشتیبانی در APIهای GPU اساسی را بررسی کردیم و قصد داریم پیشنهادی را به گروه استانداردسازی WebGPU ارائه کنیم. همانطور که در مورد زیر گروه ها، ما انتظار داریم که بیشتر بحث در مورد قابلیت حمل متمرکز شود.
برای ارزیابی عملکرد عملیات زیرگروه، در یک برنامه واقعی، ما پشتیبانی آزمایشی برای زیرگروه ها را در MediaPipe ادغام کردیم و آن را با نمونه اولیه Chrome برای عملیات زیرگروه آزمایش کردیم.
ما از زیرگروهها در هستههای GPU فاز پیشپرکردن مدل زبان بزرگ استفاده کردیم، بنابراین من فقط افزایش سرعت را برای مرحله پیشپر گزارش میدهم. در پردازندههای گرافیکی اینتل، میبینیم که زیرگروهها دو و نیم برابر سریعتر از پایه کار میکنند. با این حال، این پیشرفت ها در GPU های مختلف سازگار نیستند.
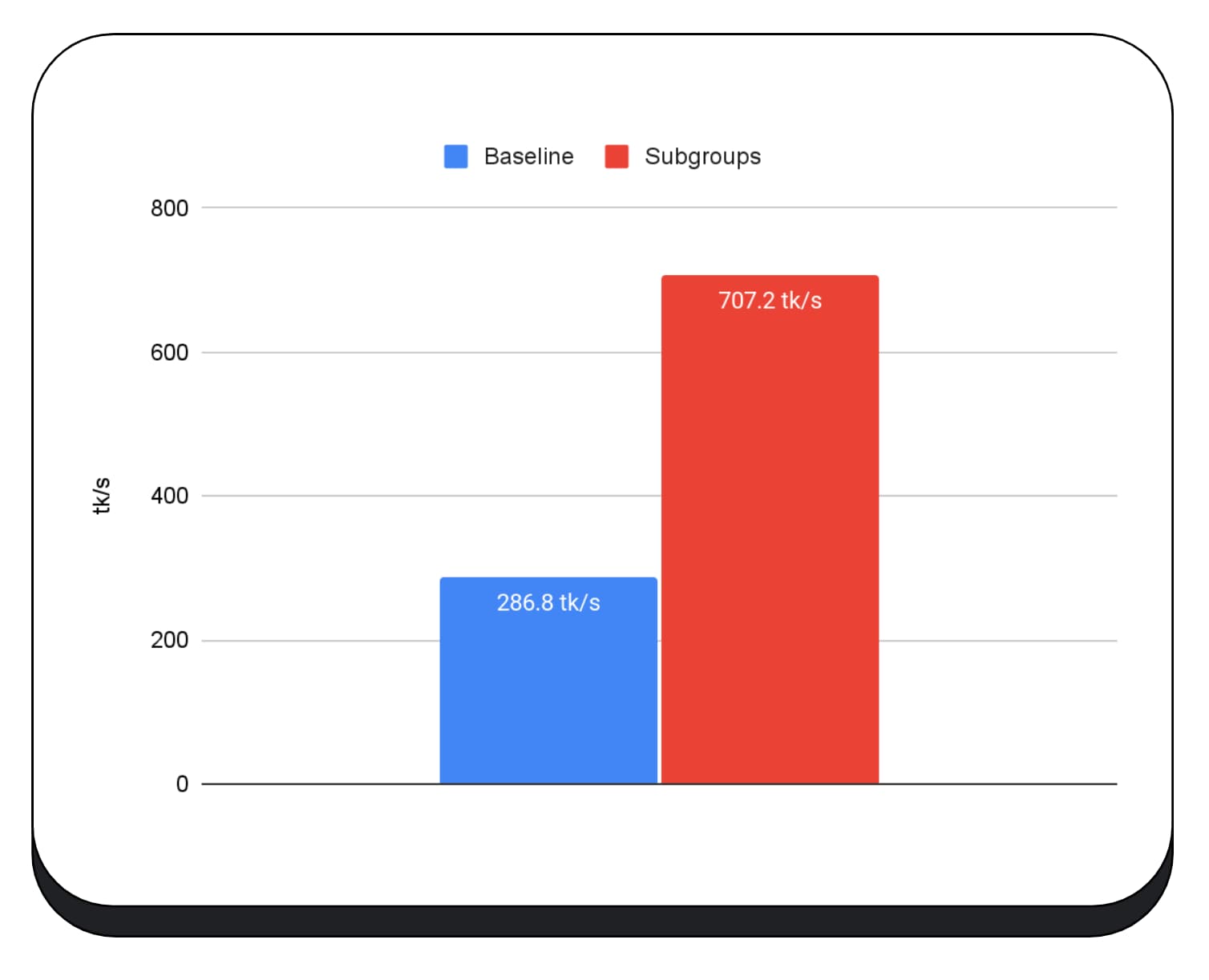
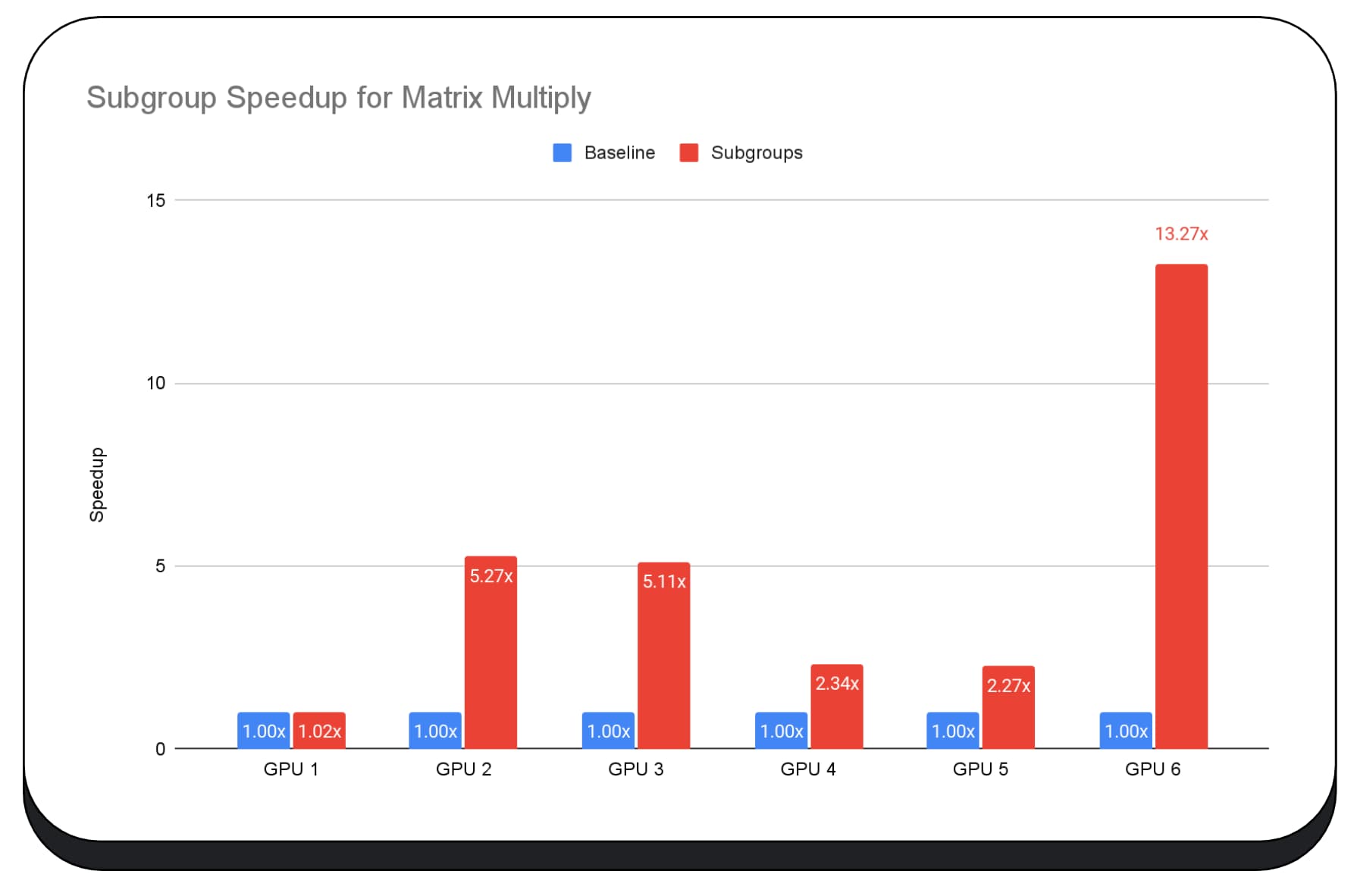
نمودار بعدی نتایج استفاده از زیرگروهها را برای بهینهسازی یک میکروبنچمارک ضرب ماتریسی در چندین پردازنده گرافیکی مصرفکننده نشان میدهد. ضرب ماتریس یکی از عملیات های سنگین تر در مدل های زبان بزرگ است. داده ها نشان می دهد که در بسیاری از پردازنده های گرافیکی، زیرگروه ها سرعت را دو، پنج و حتی سیزده برابر سطح پایه افزایش می دهند. با این حال، توجه داشته باشید که در اولین GPU، زیرگروه ها اصلاً بهتر نیستند.
بهینه سازی GPU مشکل است
در نهایت، بهترین راه برای بهینه سازی GPU بستگی به GPU ارائه شده توسط مشتری دارد. استفاده از ویژگیهای جدید GPU همیشه آنطور که انتظار دارید نتیجه نمیدهد، زیرا میتواند عوامل پیچیده زیادی در آن دخیل باشند. بهترین استراتژی بهینه سازی در یک GPU ممکن است بهترین استراتژی در GPU دیگر نباشد.
شما می خواهید پهنای باند حافظه را به حداقل برسانید، در حالی که به طور کامل از رشته های محاسباتی GPU استفاده می کنید.
الگوهای دسترسی به حافظه نیز می توانند بسیار مهم باشند. هنگامی که رشته های محاسباتی با الگوی بهینه برای سخت افزار به حافظه دسترسی پیدا می کنند، پردازنده های گرافیکی بسیار بهتر عمل می کنند. مهم: باید انتظار ویژگی های عملکرد متفاوتی را در سخت افزارهای مختلف GPU داشته باشید. ممکن است لازم باشد بسته به پردازنده گرافیکی، بهینه سازی های مختلفی را اجرا کنید.
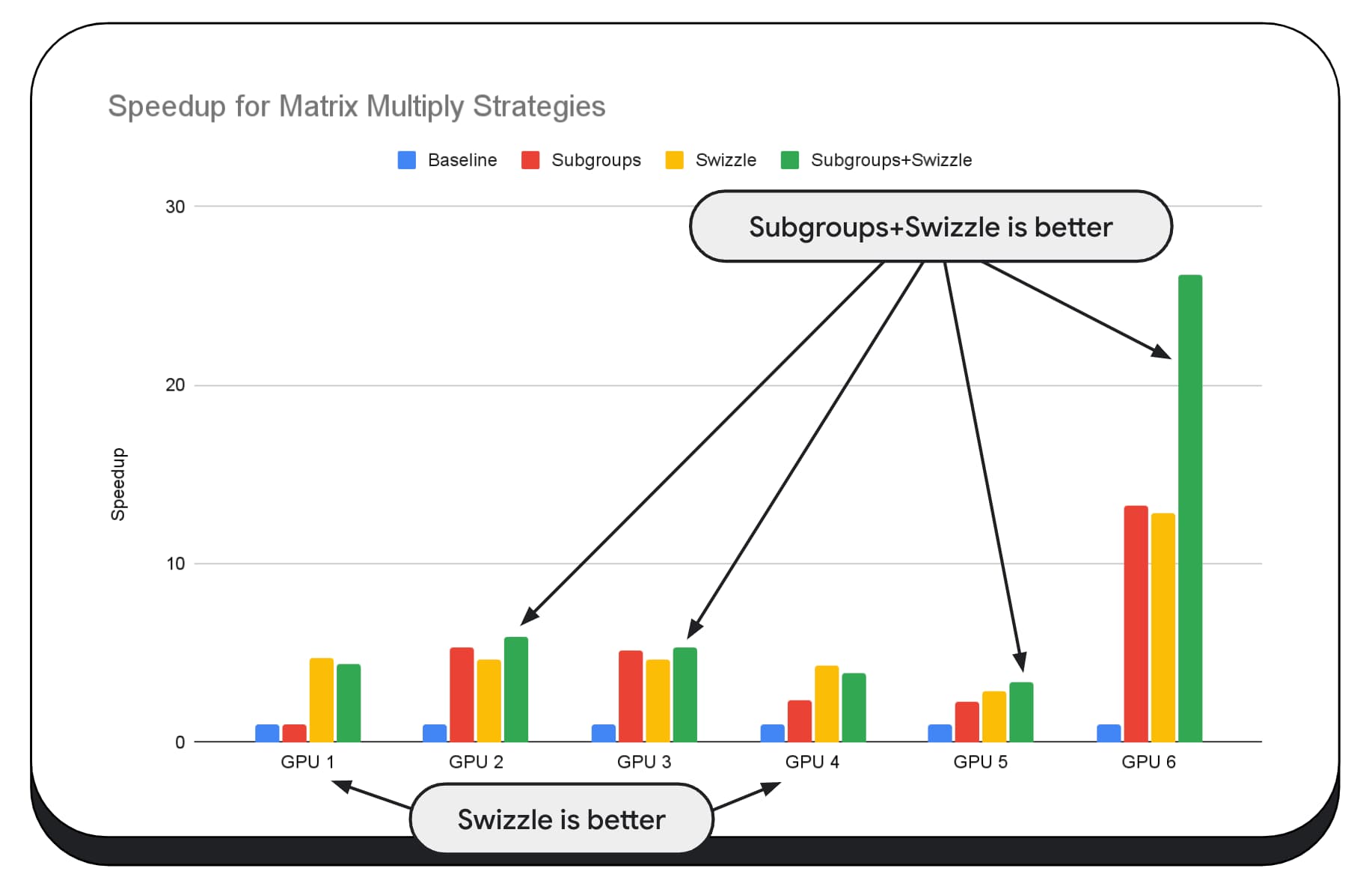
در نمودار زیر، الگوریتم ضرب ماتریس یکسانی را انتخاب کردهایم، اما بعد دیگری را برای نشان دادن بیشتر تأثیر استراتژیهای بهینهسازی مختلف، و پیچیدگی و واریانس در بین GPUهای مختلف، اضافه کردهایم. ما در اینجا یک تکنیک جدید را معرفی کرده ایم که آن را "Swizzle" می نامیم. Swizzle الگوهای دسترسی به حافظه را بهینه می کند تا برای سخت افزار بهینه تر باشد.
می توانید ببینید که چرخش حافظه تأثیر قابل توجهی دارد. گاهی اوقات حتی از زیرگروه ها تاثیرگذارتر است. در GPU 6، swizzle سرعت 12 برابر را ارائه می دهد، در حالی که زیرگروه ها سرعت 13 برابر را ارائه می دهند. در مجموع، سرعت فوق العاده 26 برابری دارند. برای سایر پردازندههای گرافیکی، گاهی اوقات swizzle و زیرگروهها با هم بهتر از هر یک به تنهایی عمل میکنند. و در سایر پردازندههای گرافیکی، استفاده انحصاری از Swizzle بهترین عملکرد را دارد.
تنظیم و بهینه سازی الگوریتم های GPU برای کارکرد خوب روی هر قطعه سخت افزاری، می تواند به تخصص زیادی نیاز داشته باشد. اما خوشبختانه تعداد زیادی کار با استعداد در چارچوبهای کتابخانههای سطح بالاتر، مانند Mediapipe ، Transformers.js ، Apache TVM ، ONNX Runtime Web و موارد دیگر وجود دارد.
کتابخانهها و فریمورکها برای مدیریت پیچیدگیهای مدیریت معماریهای مختلف GPU و تولید کدهای مخصوص پلتفرم که به خوبی روی کلاینت اجرا میشوند، موقعیت خوبی دارند.
غذای آماده
تیم Chrome همچنان به توسعه استانداردهای WebAssembly و WebGPU برای بهبود پلت فرم وب برای بارهای کاری یادگیری ماشین کمک می کند. ما روی محاسبات اولیه سریعتر، تعامل بهتر در استانداردهای وب سرمایهگذاری میکنیم و مطمئن میشویم که مدلهای بزرگ و کوچک قادر به اجرای کارآمد در دستگاهها هستند.
هدف ما به حداکثر رساندن قابلیتهای پلتفرم در عین حفظ بهترین وب است: دسترسی، قابلیت استفاده و قابلیت حمل. و ما این کار را به تنهایی انجام نمی دهیم. ما در حال همکاری با سایر فروشندگان مرورگر در W3C و بسیاری از شرکای توسعه هستیم.
امیدواریم هنگام کار با WebAssembly و WebGPU موارد زیر را به خاطر بسپارید:
- استنتاج هوش مصنوعی اکنون در وب، در همه دستگاهها در دسترس است. این مزیت اجرا بر روی دستگاه های سرویس گیرنده، مانند کاهش هزینه سرور، تاخیر کم و افزایش حریم خصوصی را به همراه دارد.
- در حالی که بسیاری از ویژگیهای مورد بحث عمدتاً به نویسندگان فریمورک مربوط میشوند، برنامههای شما میتوانند بدون هزینه زیاد سود ببرند.
- استانداردهای وب سیال و در حال تکامل هستند و ما همیشه به دنبال بازخورد هستیم. شما را برای WebAssembly و WebGPU به اشتراک بگذارید.
قدردانی
مایلیم از تیم گرافیک وب اینتل تشکر کنیم که در هدایت WebGPU f16 و ویژگیهای محصول اعداد صحیح مفید بودند. مایلیم از سایر اعضای گروه های کاری WebAssembly و WebGPU در W3C، از جمله سایر فروشندگان مرورگر، تشکر کنیم.
از تیمهای هوش مصنوعی و ML هم در Google و هم در جامعه منبع باز برای شرکای باورنکردنی تشکر میکنیم. و البته همه هم تیمی های ما که همه اینها را ممکن می کنند.
،این سند ادامه پیشرفتهای WebAssembly و WebGPU برای هوش مصنوعی وب سریعتر، بخش 1 است. توصیه می کنیم قبل از ادامه این پست را بخوانید یا سخنرانی را در IO 24 تماشا کنید .
WebGPU
WebGPU به برنامه های کاربردی وب امکان دسترسی به سخت افزار GPU مشتری را برای انجام محاسبات کارآمد و بسیار موازی می دهد. از زمان راهاندازی WebGPU در کروم ، شاهد نمایشهای باورنکردنی هوش مصنوعی (AI) و یادگیری ماشینی (ML) در وب هستیم.
برای مثال، Web Stable Diffusion نشان داد که میتوان از هوش مصنوعی برای تولید تصاویر از متن، مستقیماً در مرورگر استفاده کرد. در اوایل سال جاری، تیم Mediapipe خود گوگل ، پشتیبانی آزمایشی را برای استنتاج مدل زبان بزرگ منتشر کرد.
انیمیشن زیر Gemma ، مدل زبان بزرگ منبع باز Google (LLM) را نشان می دهد که به طور کامل روی دستگاه در کروم اجرا می شود، در زمان واقعی.
نسخه نمایشی زیر از Hugging Face از Meta's Segment Anything Model ماسک های شی با کیفیت بالا را به طور کامل بر روی مشتری تولید می کند.
اینها تنها چند پروژه شگفت انگیز است که قدرت WebGPU را برای هوش مصنوعی و ML به نمایش می گذارد. WebGPU به این مدل ها و سایر مدل ها اجازه می دهد تا به طور قابل توجهی سریعتر از آنچه می توانند روی CPU اجرا شوند.
معیار WebGPU Hugging Face برای جاسازی متن، در مقایسه با یک CPU از همان مدل، سرعتهای فوقالعادهای را نشان میدهد. در لپتاپ Apple M1 Max، WebGPU بیش از 30 برابر سریعتر بود. برخی دیگر گزارش کرده اند که WebGPU این معیار را بیش از 120 برابر تسریع می کند.
بهبود ویژگی های WebGPU برای هوش مصنوعی و ML
WebGPU برای مدلهای هوش مصنوعی و ML که به لطف پشتیبانی از شیدرهای محاسباتی میتوانند میلیاردها پارامتر داشته باشند، عالی است. شیدرهای محاسباتی روی GPU اجرا می شوند و به اجرای عملیات آرایه موازی روی حجم زیادی از داده کمک می کنند.
در میان پیشرفتهای متعدد WebGPU در سال گذشته، ما به افزودن قابلیتهای بیشتری برای بهبود عملکرد ML و AI در وب ادامه دادهایم. اخیراً دو ویژگی جدید راه اندازی کردیم: ممیز شناور 16 بیتی و محصولات نقطه صحیح بسته بندی شده.
ممیز شناور 16 بیتی
به یاد داشته باشید، بارهای کاری ML نیازی به دقت ندارند . shader-f16 قابلیتی است که امکان استفاده از نوع f16 را در زبان سایه زنی WebGPU فراهم می کند. این نوع ممیز شناور به جای 32 بیت معمول، 16 بیت می گیرد. f16 برد کمتری دارد و دقت کمتری دارد، اما برای بسیاری از مدل های ML این کافی است.
این ویژگی به چند روش کارایی را افزایش می دهد:
کاهش حافظه : تانسورهای دارای عناصر f16 نیمی از فضا را اشغال میکنند که استفاده از حافظه را به نصف کاهش میدهد. محاسبات GPU اغلب در پهنای باند حافظه با تنگنا مواجه می شوند، بنابراین نیمی از حافظه اغلب به این معنی است که شیدرها دو برابر سریعتر اجرا می شوند. از نظر فنی، برای صرفه جویی در پهنای باند حافظه به f16 نیاز ندارید. این امکان وجود دارد که داده ها را در قالبی با دقت کم ذخیره کنید و سپس برای محاسبه آن را به f32 کامل در سایه زن گسترش دهید. اما، GPU قدرت محاسباتی بیشتری را برای بسته بندی و باز کردن داده ها صرف می کند.
کاهش تبدیل داده : f16 از محاسبات کمتری با به حداقل رساندن تبدیل داده استفاده می کند. داده های با دقت پایین را می توان ذخیره کرد و سپس مستقیماً بدون تبدیل استفاده کرد.
افزایش موازی کاری : GPUهای مدرن قادرند مقادیر بیشتری را به طور همزمان در واحدهای اجرایی GPU جای دهند و به آن اجازه می دهد تعداد بیشتری از محاسبات موازی را انجام دهد. به عنوان مثال، یک GPU که تا 5 تریلیون عملیات ممیز شناور f32 در ثانیه را پشتیبانی می کند، ممکن است از 10 تریلیون عملیات ممیز شناور f16 در هر ثانیه پشتیبانی کند.
shader-f16 ، معیار WebGPU Hugging Face برای معیار جاسازی متن، این معیار را 3 برابر سریعتر از f32 در لپتاپ Apple M1 Max اجرا میکند.WebLLM پروژه ای است که می تواند چندین مدل زبان بزرگ را اجرا کند. از Apache TVM ، یک چارچوب کامپایلر یادگیری ماشین منبع باز استفاده می کند.
از WebLLM خواستم تا با استفاده از مدل پارامتر هشت میلیاردی Llama 3 برای سفر به پاریس برنامه ریزی کند. نتایج نشان می دهد که در مرحله پیش پر کردن مدل، f16 2.1 برابر سریعتر از f32 است. در مرحله رمزگشایی، بیش از 1.3 برابر سریعتر است.
برنامهها ابتدا باید تأیید کنند که آداپتور GPU از f16 پشتیبانی میکند و اگر در دسترس است، هنگام درخواست دستگاه GPU، آن را به صراحت فعال کنید. اگر f16 پشتیبانی نمیشود، نمیتوانید آن را در آرایه requiredFeatures درخواست کنید.
// main.js
const adapter = await navigator.gpu.requestAdapter();
const supportsF16 = adapter.features.has('shader-f16');
if (supportsF16) {
// Use f16.
const device = await adapter.requestDevice({
requiredFeatures: ['shader-f16'],
});
initApp(device);
}
سپس، در سایه زن های WebGPU خود، باید به صراحت f16 را در بالا فعال کنید. پس از آن، شما آزاد هستید که از آن در سایه زن مانند هر نوع داده شناور دیگری استفاده کنید.
// my-shader.wgsl
enable f16;
struct Data {
values : array<vec4<f16>>
}
@group(0) @binding(0) var<storage, read> data : Data;
@compute @workgroup_size(64) fn main(@builtin(global_invocation_id) gid : vec3u) {
let value : vec4<f16> = data.values[gid.x];
...
}
محصولات نقطه صحیح بسته بندی شده
بسیاری از مدلها هنوز با 8 بیت دقت (نیم f16) به خوبی کار میکنند. این در بین LLM ها و مدل های تصویر برای تقسیم بندی و تشخیص اشیا محبوب است. همانطور که گفته شد، کیفیت خروجی برای مدلها با دقت کمتری کاهش مییابد، بنابراین کوانتیزاسیون 8 بیتی برای هر کاربرد مناسب نیست.
تعداد نسبتا کمی از GPU ها به طور بومی از مقادیر 8 بیتی پشتیبانی می کنند. اینجاست که محصولات نقطه صحیح بسته بندی شده وارد می شوند. ما DP4a را در Chrome 123 ارسال کردیم.
پردازندههای گرافیکی مدرن دستورالعملهای خاصی برای گرفتن دو عدد صحیح 32 بیتی دارند، هر کدام را به عنوان 4 عدد صحیح 8 بیتی متوالی تفسیر میکنند و محصول نقطهای را بین اجزای آنها محاسبه میکنند.
این به ویژه برای هوش مصنوعی و یادگیری ماشین مفید است زیرا هسته های ضرب ماتریس از محصولات نقطه بسیار بسیار زیادی تشکیل شده اند.
برای مثال، بیایید یک ماتریس 4 در 8 را با یک بردار 8 x 1 ضرب کنیم. محاسبه این شامل گرفتن 4 محصول نقطه برای محاسبه هر یک از مقادیر در بردار خروجی است. الف، ب، ج و د.
فرآیند محاسبه هر یک از این خروجی ها یکسان است. ما به مراحل مربوط به محاسبه یکی از آنها نگاه خواهیم کرد. قبل از هر محاسباتی، ابتدا باید داده های عدد صحیح 8 بیتی را به نوعی تبدیل کنیم که بتوانیم با آن محاسبات انجام دهیم، مانند f16. سپس، یک ضرب المان را اجرا می کنیم و در نهایت، همه محصولات را با هم جمع می کنیم. در مجموع، برای کل ضرب ماتریس-بردار، 40 تبدیل اعداد صحیح به شناور برای باز کردن داده ها، 32 ضرب شناور و 28 جمع شناور انجام می دهیم.
برای ماتریس های بزرگتر با عملیات بیشتر، محصولات نقطه صحیح بسته بندی شده می توانند به کاهش میزان کار کمک کنند.
برای هر یک از خروجیهای بردار نتیجه، دو عملیات محصول نقطههای بستهشده را با استفاده از WebGPU Shading Language داخلی dot4U8Packed انجام میدهیم و سپس نتایج را با هم اضافه میکنیم. در مجموع، برای کل ضرب ماتریس-بردار، هیچ تبدیل داده ای انجام نمی دهیم. ما 8 محصول نقطه بسته و 4 عدد صحیح اضافه می کنیم.
ما محصولات نقطه صحیح بسته بندی شده را با داده های 8 بیتی روی انواع پردازنده های گرافیکی مصرف کننده آزمایش کردیم. در مقایسه با ممیز شناور 16 بیتی، می بینیم که 8 بیت 1.6 تا 2.8 برابر سریعتر است. وقتی از محصولات نقطه صحیح بسته بندی شده نیز استفاده می کنیم، عملکرد حتی بهتر می شود. 1.7 تا 2.9 برابر سریعتر است.
پشتیبانی مرورگر را با ویژگی wgslLanguageFeatures بررسی کنید. اگر GPU به طور بومی از محصولات packed dot پشتیبانی نمیکند، مرورگر پیادهسازی خود را به صورت polyfill میکند.
// main.js
if (navigator.gpu.wgslLanguageFeatures.has('packed_4x8_integer_dot_product')) {
// Use dot4U8Packed, dot4I8Packed builtin
// functions in the shaders.
}
تفاوت قطعه کد زیر (تفاوت) تغییرات مورد نیاز برای استفاده از محصولات عدد صحیح بسته بندی شده در یک سایه زن WebGPU را برجسته می کند.
قبل - یک سایه زن WebGPU که محصولات نقطه جزئی را در متغیر "sum" جمع می کند. در انتهای حلقه، «sum» حاصل ضرب نقطه کامل را بین یک بردار و یک ردیف از ماتریس ورودی نگه میدارد.
// my-dot-product.wgsl @compute @workgroup_size(64) fn main(@builtin(global_invocation_id) gid : vec3u) { var sum : f16; let start = gid.x * uniforms.dim; for (var i = 0u; i < uniforms.dim; i++) { let v1 : vec4<f16> = vector.values[i]; let v2 : vec4<f16> = matrix.values[start + i]; sum += dot(v1, v2); } }
بعد - یک سایه زن WebGPU که برای استفاده از محصولات نقطه صحیح بسته بندی شده نوشته شده است. تفاوت اصلی این است که به جای بارگذاری 4 مقدار شناور خارج از بردار و ماتریس، این سایه زن یک عدد صحیح 32 بیتی را بارگذاری می کند. این عدد صحیح 32 بیتی داده های چهار مقدار صحیح 8 بیتی را در خود نگه می دارد. سپس، dot4U8Packed را فراخوانی می کنیم تا حاصل ضرب نقطه ای دو مقدار را محاسبه کنیم.
// my-dot-product.wgsl
@compute @workgroup_size(64)
fn main(@builtin(global_invocation_id) gid : vec3u) {
var sum : f32;
let start = gid.x * uniforms.dim;
for (var i = 0u; i < uniforms.dim; i++) {
let v1 : u32 = vector.values[i];
let v2 : u32 = matrix.values[start + i];
sum += dot4U8Packed(v1, v2);
}
}
هم محصولات ممیز شناور 16 بیتی و هم محصولات نقطه صحیح بسته بندی شده، ویژگی های ارسال شده در کروم هستند که هوش مصنوعی و ML را تسریع می کنند. ممیز شناور 16 بیتی زمانی در دسترس است که سختافزار از آن پشتیبانی کند، و Chrome محصولات نقطهصحیح بستهبندی شده را در همه دستگاهها پیادهسازی میکند.
امروز میتوانید از این ویژگیها در Chrome Stable برای دستیابی به عملکرد بهتر استفاده کنید.
ویژگی های پیشنهادی
به آینده، ما دو ویژگی دیگر را بررسی می کنیم: زیرگروه ها و ضرب ماتریس تعاونی.
ویژگی زیرگروهها موازیسازی سطح SIMD را برای برقراری ارتباط یا انجام عملیات ریاضی جمعی، مانند مجموع بیش از 16 عدد، قادر میسازد. این امکان به اشتراک گذاری داده های بین رشته ای کارآمد را فراهم می کند. زیرگروهها در APIهای GPUهای مدرن، با نامهای متفاوت و در اشکال کمی متفاوت پشتیبانی میشوند.
ما مجموعه مشترک را در یک پیشنهاد تقطیر کرده ایم که به گروه استانداردسازی WebGPU برده ایم. و، ما زیرگروههایی را در کروم در پشت پرچم آزمایشی نمونهسازی کردهایم و نتایج اولیه خود را وارد بحث کردهایم. مسئله اصلی نحوه اطمینان از رفتار قابل حمل است.
ضرب ماتریس تعاونی جدیدتر به GPU اضافه شده است. یک ضرب ماتریس بزرگ را می توان به چندین ضرب ماتریس کوچکتر تقسیم کرد. ضرب ماتریس تعاونی ضربات را روی این بلوک های کوچکتر با اندازه ثابت در یک مرحله منطقی انجام می دهد. در این مرحله، گروهی از نخ ها به طور موثر برای محاسبه نتیجه همکاری می کنند.
ما پشتیبانی در APIهای GPU اساسی را بررسی کردیم و قصد داریم پیشنهادی را به گروه استانداردسازی WebGPU ارائه کنیم. همانطور که در مورد زیر گروه ها، ما انتظار داریم که بیشتر بحث در مورد قابلیت حمل متمرکز شود.
برای ارزیابی عملکرد عملیات زیرگروه، در یک برنامه واقعی، ما پشتیبانی آزمایشی برای زیرگروه ها را در MediaPipe ادغام کردیم و آن را با نمونه اولیه Chrome برای عملیات زیرگروه آزمایش کردیم.
ما از زیرگروهها در هستههای GPU فاز پیشپرکردن مدل زبان بزرگ استفاده کردیم، بنابراین من فقط افزایش سرعت را برای مرحله پیشپر گزارش میدهم. در پردازندههای گرافیکی اینتل، میبینیم که زیرگروهها دو و نیم برابر سریعتر از پایه کار میکنند. با این حال، این پیشرفت ها در GPU های مختلف سازگار نیستند.
نمودار بعدی نتایج استفاده از زیرگروهها را برای بهینهسازی یک میکروبنچمارک ضرب ماتریسی در چندین پردازنده گرافیکی مصرفکننده نشان میدهد. ضرب ماتریس یکی از عملیات های سنگین تر در مدل های زبان بزرگ است. داده ها نشان می دهد که در بسیاری از پردازنده های گرافیکی، زیرگروه ها سرعت را دو، پنج و حتی سیزده برابر سطح پایه افزایش می دهند. با این حال، توجه داشته باشید که در اولین GPU، زیرگروه ها اصلاً بهتر نیستند.
بهینه سازی GPU مشکل است
در نهایت، بهترین راه برای بهینه سازی GPU بستگی به GPU ارائه شده توسط مشتری دارد. استفاده از ویژگیهای جدید GPU همیشه آنطور که انتظار دارید نتیجه نمیدهد، زیرا میتواند عوامل پیچیده زیادی در آن دخیل باشند. بهترین استراتژی بهینه سازی در یک GPU ممکن است بهترین استراتژی در GPU دیگر نباشد.
شما می خواهید پهنای باند حافظه را به حداقل برسانید، در حالی که به طور کامل از رشته های محاسباتی GPU استفاده می کنید.
الگوهای دسترسی به حافظه نیز می توانند بسیار مهم باشند. هنگامی که رشته های محاسباتی با الگوی بهینه برای سخت افزار به حافظه دسترسی پیدا می کنند، پردازنده های گرافیکی بسیار بهتر عمل می کنند. مهم: باید انتظار ویژگی های عملکرد متفاوتی را در سخت افزارهای مختلف GPU داشته باشید. ممکن است لازم باشد بسته به پردازنده گرافیکی، بهینه سازی های مختلفی را اجرا کنید.
در نمودار زیر، الگوریتم ضرب ماتریس یکسانی را انتخاب کردهایم، اما بعد دیگری را برای نشان دادن بیشتر تأثیر استراتژیهای بهینهسازی مختلف، و پیچیدگی و واریانس در بین GPUهای مختلف، اضافه کردهایم. ما در اینجا یک تکنیک جدید را معرفی کرده ایم که آن را "Swizzle" می نامیم. Swizzle الگوهای دسترسی به حافظه را بهینه می کند تا برای سخت افزار بهینه تر باشد.
می توانید ببینید که چرخش حافظه تأثیر قابل توجهی دارد. گاهی اوقات حتی از زیرگروه ها تاثیرگذارتر است. در GPU 6، swizzle سرعت 12 برابر را ارائه می دهد، در حالی که زیرگروه ها سرعت 13 برابر را ارائه می دهند. در مجموع، سرعت فوق العاده 26 برابری دارند. برای سایر پردازندههای گرافیکی، گاهی اوقات swizzle و زیرگروهها با هم بهتر از هر یک به تنهایی عمل میکنند. و در سایر پردازندههای گرافیکی، استفاده انحصاری از Swizzle بهترین عملکرد را دارد.
تنظیم و بهینه سازی الگوریتم های GPU برای کارکرد خوب روی هر قطعه سخت افزاری، می تواند به تخصص زیادی نیاز داشته باشد. اما خوشبختانه تعداد زیادی کار با استعداد در چارچوبهای کتابخانههای سطح بالاتر، مانند Mediapipe ، Transformers.js ، Apache TVM ، ONNX Runtime Web و موارد دیگر وجود دارد.
کتابخانهها و فریمورکها برای مدیریت پیچیدگیهای مدیریت معماریهای مختلف GPU و تولید کدهای مخصوص پلتفرم که به خوبی روی کلاینت اجرا میشوند، موقعیت خوبی دارند.
غذای آماده
تیم Chrome همچنان به توسعه استانداردهای WebAssembly و WebGPU برای بهبود پلت فرم وب برای بارهای کاری یادگیری ماشین کمک می کند. ما روی محاسبات اولیه سریعتر، تعامل بهتر در استانداردهای وب سرمایهگذاری میکنیم و مطمئن میشویم که مدلهای بزرگ و کوچک قادر به اجرای کارآمد در دستگاهها هستند.
هدف ما به حداکثر رساندن قابلیتهای پلتفرم در عین حفظ بهترین وب است: دسترسی، قابلیت استفاده و قابلیت حمل. و ما این کار را به تنهایی انجام نمی دهیم. ما در حال همکاری با سایر فروشندگان مرورگر در W3C و بسیاری از شرکای توسعه هستیم.
امیدواریم هنگام کار با WebAssembly و WebGPU موارد زیر را به خاطر بسپارید:
- استنتاج هوش مصنوعی اکنون در وب، در همه دستگاهها در دسترس است. این مزیت اجرا بر روی دستگاه های سرویس گیرنده، مانند کاهش هزینه سرور، تاخیر کم و افزایش حریم خصوصی را به همراه دارد.
- در حالی که بسیاری از ویژگیهای مورد بحث عمدتاً به نویسندگان فریمورک مربوط میشوند، برنامههای شما میتوانند بدون هزینه زیاد سود ببرند.
- استانداردهای وب سیال و در حال تکامل هستند و ما همیشه به دنبال بازخورد هستیم. شما را برای WebAssembly و WebGPU به اشتراک بگذارید.
قدردانی
مایلیم از تیم گرافیک وب اینتل تشکر کنیم که در هدایت WebGPU f16 و ویژگیهای محصول اعداد صحیح مفید بودند. مایلیم از سایر اعضای گروه های کاری WebAssembly و WebGPU در W3C، از جمله سایر فروشندگان مرورگر، تشکر کنیم.
از تیمهای هوش مصنوعی و ML هم در Google و هم در جامعه منبع باز برای شرکای باورنکردنی تشکر میکنیم. و البته همه هم تیمی های ما که همه اینها را ممکن می کنند.
،این سند ادامه پیشرفتهای WebAssembly و WebGPU برای هوش مصنوعی وب سریعتر، بخش 1 است. توصیه می کنیم قبل از ادامه این پست را بخوانید یا سخنرانی را در IO 24 تماشا کنید .
WebGPU
WebGPU به برنامه های کاربردی وب امکان دسترسی به سخت افزار GPU مشتری را برای انجام محاسبات کارآمد و بسیار موازی می دهد. از زمان راهاندازی WebGPU در کروم ، شاهد نمایشهای باورنکردنی هوش مصنوعی (AI) و یادگیری ماشینی (ML) در وب هستیم.
برای مثال، Web Stable Diffusion نشان داد که میتوان از هوش مصنوعی برای تولید تصاویر از متن، مستقیماً در مرورگر استفاده کرد. در اوایل سال جاری، تیم Mediapipe خود گوگل ، پشتیبانی آزمایشی را برای استنتاج مدل زبان بزرگ منتشر کرد.
انیمیشن زیر Gemma ، مدل زبان بزرگ منبع باز Google (LLM) را نشان می دهد که به طور کامل روی دستگاه در کروم اجرا می شود، در زمان واقعی.
نسخه نمایشی زیر از Hugging Face از Meta's Segment Anything Model ماسک های شی با کیفیت بالا را به طور کامل بر روی مشتری تولید می کند.
اینها تنها چند پروژه شگفت انگیز است که قدرت WebGPU را برای هوش مصنوعی و ML به نمایش می گذارد. WebGPU به این مدل ها و سایر مدل ها اجازه می دهد تا به طور قابل توجهی سریعتر از آنچه می توانند روی CPU اجرا شوند.
معیار WebGPU Hugging Face برای جاسازی متن، در مقایسه با یک CPU از همان مدل، سرعتهای فوقالعادهای را نشان میدهد. در لپتاپ Apple M1 Max، WebGPU بیش از 30 برابر سریعتر بود. برخی دیگر گزارش کرده اند که WebGPU این معیار را بیش از 120 برابر تسریع می کند.
بهبود ویژگی های WebGPU برای هوش مصنوعی و ML
WebGPU برای مدلهای هوش مصنوعی و ML که به لطف پشتیبانی از شیدرهای محاسباتی میتوانند میلیاردها پارامتر داشته باشند، عالی است. شیدرهای محاسباتی روی GPU اجرا می شوند و به اجرای عملیات آرایه موازی روی حجم زیادی از داده کمک می کنند.
در میان پیشرفتهای متعدد WebGPU در سال گذشته، ما به افزودن قابلیتهای بیشتری برای بهبود عملکرد ML و AI در وب ادامه دادهایم. اخیراً دو ویژگی جدید راه اندازی کردیم: ممیز شناور 16 بیتی و محصولات نقطه صحیح بسته بندی شده.
ممیز شناور 16 بیتی
به یاد داشته باشید، بارهای کاری ML نیازی به دقت ندارند . shader-f16 قابلیتی است که امکان استفاده از نوع f16 را در زبان سایه زنی WebGPU فراهم می کند. این نوع ممیز شناور به جای 32 بیت معمول، 16 بیت می گیرد. f16 برد کمتری دارد و دقت کمتری دارد، اما برای بسیاری از مدل های ML این کافی است.
این ویژگی به چند روش کارایی را افزایش می دهد:
کاهش حافظه : تانسورهای دارای عناصر f16 نیمی از فضا را اشغال میکنند که استفاده از حافظه را به نصف کاهش میدهد. محاسبات GPU اغلب در پهنای باند حافظه با تنگنا مواجه می شوند، بنابراین نیمی از حافظه اغلب به این معنی است که شیدرها دو برابر سریعتر اجرا می شوند. از نظر فنی، برای صرفه جویی در پهنای باند حافظه به f16 نیاز ندارید. این امکان وجود دارد که داده ها را در قالبی با دقت کم ذخیره کنید و سپس برای محاسبه آن را به f32 کامل در سایه زن گسترش دهید. اما، GPU قدرت محاسباتی بیشتری را برای بسته بندی و باز کردن داده ها صرف می کند.
کاهش تبدیل داده : f16 از محاسبات کمتری با به حداقل رساندن تبدیل داده استفاده می کند. داده های با دقت پایین را می توان ذخیره کرد و سپس مستقیماً بدون تبدیل استفاده کرد.
افزایش موازی کاری : GPUهای مدرن قادرند مقادیر بیشتری را به طور همزمان در واحدهای اجرایی GPU جای دهند و به آن اجازه می دهد تعداد بیشتری از محاسبات موازی را انجام دهد. به عنوان مثال، یک GPU که تا 5 تریلیون عملیات ممیز شناور f32 در ثانیه را پشتیبانی می کند، ممکن است از 10 تریلیون عملیات ممیز شناور f16 در هر ثانیه پشتیبانی کند.
shader-f16 ، در آغوش گرفتن معیار WebGPU Face برای متن تعبیه شده ، معیار را 3 بار سریعتر از F32 در لپ تاپ Apple M1 Max اجرا می کند.Webllm یک پروژه است که می تواند چندین مدل بزرگ زبان را اجرا کند. از Apache TVM ، یک چارچوب کامپایلر یادگیری ماشین منبع باز استفاده می کند.
من از Webllm خواستم تا با استفاده از مدل پارامتر هشت میلیارد Llama 3 ، سفر به پاریس را برنامه ریزی کند. نتایج نشان می دهد که در مرحله مقدماتی مدل ، F16 2.1 برابر سریعتر از F32 است. در مرحله رمزگشایی ، بیش از 1.3 برابر سریعتر است.
برنامه های کاربردی ابتدا باید تأیید کنند که آداپتور GPU از F16 پشتیبانی می کند و در صورت وجود ، صریحاً هنگام درخواست دستگاه GPU آن را فعال کنید. اگر F16 پشتیبانی نمی شود ، شما نمی توانید آن را در آرایه requiredFeatures درخواست کنید.
// main.js
const adapter = await navigator.gpu.requestAdapter();
const supportsF16 = adapter.features.has('shader-f16');
if (supportsF16) {
// Use f16.
const device = await adapter.requestDevice({
requiredFeatures: ['shader-f16'],
});
initApp(device);
}
سپس ، در سایه های WebGPU خود ، باید صریحاً F16 را در بالا فعال کنید. پس از آن ، شما می توانید مانند هر نوع داده دیگر شناور از آن در سایه بان استفاده کنید.
// my-shader.wgsl
enable f16;
struct Data {
values : array<vec4<f16>>
}
@group(0) @binding(0) var<storage, read> data : Data;
@compute @workgroup_size(64) fn main(@builtin(global_invocation_id) gid : vec3u) {
let value : vec4<f16> = data.values[gid.x];
...
}
محصولات نقطه عدد صحیح بسته بندی شده
بسیاری از مدل ها هنوز هم با 8 بیت دقت (نیمی از F16) خوب کار می کنند. این در بین LLM ها و مدل های تصویر برای تقسیم بندی و تشخیص شی محبوب است. گفته می شود ، کیفیت خروجی برای مدل ها با دقت کمتری تخریب می شود ، بنابراین کمیت 8 بیتی برای هر برنامه مناسب نیست.
نسبتاً معدود GPU های بومی از مقادیر 8 بیتی پشتیبانی می کنند. این جایی است که محصولات نقطه عدد صحیح بسته بندی شده وارد می شوند. ما DP4A را در Chrome 123 حمل کردیم.
GPU های مدرن دستورالعمل های ویژه ای برای گرفتن دو عدد صحیح 32 بیتی دارند ، هر کدام را به عنوان 4 عدد صحیح 8 بیتی بسته بندی شده متوالی تفسیر می کنند و محصول DOT را بین اجزای خود محاسبه می کنند.
این امر به ویژه برای AI و یادگیری ماشین مفید است زیرا هسته های ضرب ماتریس از بسیاری از محصولات DOT تشکیل شده اند.
به عنوان مثال ، بیایید یک ماتریس 4 x 8 را با یک بردار 8 x 1 ضرب کنیم. محاسبه این امر شامل مصرف 4 محصول برای محاسبه هر یک از مقادیر موجود در بردار خروجی است. A ، B ، C و D.
فرآیند محاسبه هر یک از این خروجی ها یکسان است ؛ ما به مراحل مربوط به محاسبه یکی از آنها نگاه خواهیم کرد. قبل از هر محاسبه ، ما ابتدا باید داده های عدد صحیح 8 بیتی را به نوعی تبدیل کنیم که می توانیم حسابی را با آن انجام دهیم ، مانند F16. سپس ، ما یک ضرب عناصر را اجرا می کنیم و در آخر ، تمام محصولات را با هم اضافه می کنیم. در کل ، برای کل ضرب ماتریس بردار ، ما 40 عدد صحیح را برای تبدیل شناورها برای باز کردن داده ها ، 32 ضرب شناور و 28 مورد اضافی شناور انجام می دهیم.
برای ماتریس های بزرگتر با عملیات بیشتر ، محصولات نقطه عدد صحیح بسته بندی شده می توانند به کاهش میزان کار کمک کنند.
برای هر یک از خروجی ها در وکتور نتیجه ، ما دو عملیات محصول بسته بندی شده DOT را با استفاده از زبان سایه زنی WebGPU داخلی dot4U8Packed انجام می دهیم و سپس نتایج را به هم اضافه می کنیم. در کل ، برای کل ضرب ماتریس بردار ، ما هیچ تبدیل داده ای را انجام نمی دهیم. ما 8 محصول نقطه بسته بندی شده و 4 عدد عدد صحیح را اجرا می کنیم.
ما محصولات نقطه عدد صحیح بسته بندی شده را با داده های 8 بیتی در انواع GPU های مصرف کننده آزمایش کردیم. در مقایسه با نقطه شناور 16 بیتی ، می بینیم که 8 بیتی 1.6 تا 2.8 برابر سریعتر است. هنگامی که ما علاوه بر این از محصولات عدد عدد صحیح بسته بندی شده استفاده می کنیم ، عملکرد حتی بهتر است. 1.7 تا 2.9 برابر سریعتر است.
پشتیبانی از مرورگر را با ویژگی wgslLanguageFeatures بررسی کنید. اگر GPU به طور بومی از محصولات DOT بسته بندی شده پشتیبانی نمی کند ، مرورگر پیاده سازی خود را به صورت خاص انجام می دهد.
// main.js
if (navigator.gpu.wgslLanguageFeatures.has('packed_4x8_integer_dot_product')) {
// Use dot4U8Packed, dot4I8Packed builtin
// functions in the shaders.
}
قطعه کد زیر متفاوت است (تفاوت) برجسته تغییرات مورد نیاز برای استفاده از محصولات عدد صحیح بسته بندی شده در یک سایه بان WebGPU.
قبل از آن - یک سایه بان WebGPU که محصولات DOT جزئی را به متغیر "جمع" جمع می کند. در انتهای حلقه ، "Sum" محصول کامل DOT را بین یک بردار و یک ردیف ماتریس ورودی نگه می دارد.
// my-dot-product.wgsl @compute @workgroup_size(64) fn main(@builtin(global_invocation_id) gid : vec3u) { var sum : f16; let start = gid.x * uniforms.dim; for (var i = 0u; i < uniforms.dim; i++) { let v1 : vec4<f16> = vector.values[i]; let v2 : vec4<f16> = matrix.values[start + i]; sum += dot(v1, v2); } }
پس از - یک سایه بان WebGPU که برای استفاده از محصولات عدد عدد صحیح بسته بندی شده نوشته شده است. تفاوت اصلی این است که به جای بارگیری 4 مقادیر شناور از بردار و ماتریس ، این سایه بان یک عدد صحیح 32 بیتی را بارگیری می کند. این عدد صحیح 32 بیتی داده های چهار مقدار عدد صحیح 8 بیتی را در اختیار دارد. سپس ، ما برای محاسبه محصول نقطه ای از دو مقدار dot4U8Packed تماس می گیریم.
// my-dot-product.wgsl
@compute @workgroup_size(64)
fn main(@builtin(global_invocation_id) gid : vec3u) {
var sum : f32;
let start = gid.x * uniforms.dim;
for (var i = 0u; i < uniforms.dim; i++) {
let v1 : u32 = vector.values[i];
let v2 : u32 = matrix.values[start + i];
sum += dot4U8Packed(v1, v2);
}
}
هر دو نقطه شناور 16 بیتی و محصولات نقطه عدد صحیح بسته بندی شده از ویژگی های حمل شده در Chrome هستند که AI و ML را تسریع می کنند. هنگامی که سخت افزار از آن پشتیبانی می کند ، نقطه شناور 16 بیتی در دسترس است و Chrome محصولات عدد عدد صحیح بسته بندی شده را در همه دستگاه ها پیاده سازی می کند.
امروز می توانید از این ویژگی ها در Chrome Stable برای دستیابی به عملکرد بهتر استفاده کنید.
ویژگی های پیشنهادی
با نگاه به جلو ، ما در حال بررسی دو ویژگی دیگر هستیم: زیر گروه ها و ماتریس تعاونی را ضرب می کنیم.
ویژگی زیر گروه ها موازی با سطح SIMD را قادر می سازد تا ارتباطات یا انجام عملیات ریاضی جمعی مانند مبلغی را برای بیش از 16 شماره انجام دهند. این امکان به اشتراک گذاری داده های متقاطع کارآمد را فراهم می کند. زیر گروه ها در API های GPU های مدرن ، با نام های مختلف و به اشکال کمی متفاوت پشتیبانی می شوند.
ما مجموعه مشترک را به پیشنهادی که به گروه استاندارد سازی WebGPU گرفته ایم ، تقطیر کرده ایم. و ، ما زیر گروه های اولیه را در Chrome در پشت پرچم آزمایشی نمونه برداری کرده ایم و نتایج اولیه خود را در بحث قرار داده ایم. مسئله اصلی نحوه اطمینان از رفتار قابل حمل است.
ماتریس تعاونی Multiply علاوه بر جدیدترین GPU ها است. یک ماتریس بزرگ ضرب می تواند به ضرب ماتریس چندگانه کوچکتر تقسیم شود. ماتریس تعاونی ضرب در این بلوک های کوچکتر در یک مرحله منطقی واحد ضرب می کند. در آن مرحله ، گروهی از موضوعات برای محاسبه نتیجه به طور مؤثر همکاری می کنند.
ما پشتیبانی را در API های GPU اساسی مورد بررسی قرار دادیم و قصد داریم پیشنهادی را به گروه استاندارد سازی WebGPU ارائه دهیم. مانند زیر گروه ها ، ما انتظار داریم که بخش اعظم بحث در مورد قابلیت حمل باشد.
برای ارزیابی عملکرد عملیات زیر گروه ، در یک برنامه واقعی ، ما پشتیبانی آزمایشی برای زیر گروه ها را به MediaPipe یکپارچه کردیم و آن را با نمونه اولیه Chrome برای عملیات زیر گروه آزمایش کردیم.
ما از زیر گروه ها در هسته های پردازنده گرافیکی فاز مقدمه مدل زبان بزرگ استفاده کردیم ، بنابراین من فقط گزارش سرعت را برای مرحله مقدماتی گزارش می دهم. در یک GPU اینتل ، می بینیم که زیر گروه ها دو و نیم بار سریعتر از پایه انجام می دهند. با این حال ، این پیشرفت ها در بین GPU های مختلف سازگار نیستند.
نمودار بعدی نتایج استفاده از زیر گروه ها را برای بهینه سازی یک ماتریس ضرب میکروب مارک در چندین GPU های مصرف کننده نشان می دهد. ضرب ماتریس یکی از عملیات سنگین تر در مدلهای بزرگ زبان است. داده ها نشان می دهد که در بسیاری از GPU ها ، زیر گروه ها سرعت دو ، پنج و حتی سیزده بار پایه را افزایش می دهند. با این حال ، توجه کنید که در اولین GPU ، زیر گروه ها به هیچ وجه بهتر نیستند.
بهینه سازی GPU دشوار است
در نهایت ، بهترین راه برای بهینه سازی GPU شما به آنچه GPU مشتری ارائه می دهد بستگی دارد. استفاده از ویژگی های جدید GPU فانتزی همیشه به شکلی که انتظار دارید پرداخت نمی کند ، زیرا می توان عوامل پیچیده زیادی را درگیر کرد. بهترین استراتژی بهینه سازی در یک GPU ممکن است بهترین استراتژی در GPU دیگر نباشد.
شما می خواهید پهنای باند حافظه را به حداقل برسانید ، در حالی که به طور کامل از موضوعات محاسباتی GPU استفاده می کنید.
الگوهای دسترسی به حافظه نیز می تواند بسیار مهم باشد. GPU ها هنگامی که موضوعات محاسباتی به حافظه دسترسی پیدا می کنند در الگویی که برای سخت افزار بهینه است ، بسیار بهتر عمل می کنند. نکته مهم: شما باید از ویژگی های مختلف عملکرد در سخت افزار مختلف GPU انتظار داشته باشید. بسته به GPU ممکن است نیاز به بهینه سازی های مختلف داشته باشید.
در نمودار زیر ، ما همان الگوریتم ضرب ماتریس را در نظر گرفته ایم ، اما ابعاد دیگری را برای نشان دادن تأثیر استراتژی های مختلف بهینه سازی و پیچیدگی و واریانس در GPU های مختلف اضافه کرده ایم. ما یک تکنیک جدید را در اینجا معرفی کرده ایم که آن را "Swizzle" می نامیم. Swizzle الگوهای دسترسی به حافظه را بهینه تر می کند تا برای سخت افزار بهینه تر باشد.
می بینید که Swizzle حافظه تأثیر قابل توجهی دارد. این گاهی اوقات حتی بیشتر از زیر گروه ها تأثیرگذار است. در GPU 6 ، Swizzle سرعت 12 برابر را فراهم می کند ، در حالی که زیر گروه ها سرعت 13 برابر را ارائه می دهند. ترکیبی ، آنها یک سرعت فوق العاده 26 برابر باورنکردنی دارند. برای سایر GPU ها ، گاهی اوقات swizzle و زیر گروه ها ترکیب بهتر از هر یک به تنهایی هستند. و در سایر GPU ها ، منحصراً استفاده از Swizzle بهترین عملکرد را انجام می دهد.
تنظیم و بهینه سازی الگوریتم های GPU برای کار به خوبی در هر قطعه سخت افزار ، می تواند به تخصص زیادی نیاز داشته باشد. اما خوشبختانه کار فوق العاده ای از کار با استعداد در چارچوب های کتابخانه های سطح بالاتر وجود دارد ، مانند MediaPipe ، Transformers.js ، Apache TVM ، ONNX Runtime Web و موارد دیگر.
کتابخانه ها و چارچوب ها برای رسیدگی به پیچیدگی مدیریت معماری های متنوع GPU و تولید کد خاص پلت فرم که به خوبی روی مشتری اجرا می شود ، از موقعیت خوبی برخوردار هستند.
غذای آماده
تیم Chrome همچنان به تکامل استانداردهای WebAssembly و WebGPU برای بهبود بستر وب برای بارهای یادگیری ماشین کمک می کند. ما در حال سرمایه گذاری در ابتدایی های محاسباتی سریعتر ، بهتر از استانداردهای وب هستیم و اطمینان حاصل می کنیم که مدل های بزرگ و کوچک قادر به اجرای کارآمد در دستگاه ها هستند.
هدف ما این است که ضمن حفظ بهترین های وب ، به حداکثر رساندن قابلیت های این سکو بمانیم: این دسترسی ، قابلیت استفاده و قابلیت حمل است. و ما این کار را به تنهایی انجام نمی دهیم. ما با همکاری سایر فروشندگان مرورگر در W3C و بسیاری از شرکای توسعه کار می کنیم.
ما امیدواریم که موارد زیر را به خاطر بسپارید ، همانطور که با WebAssembly و WebGPU کار می کنید:
- استنباط هوش مصنوعی هم اکنون در وب ، در سراسر دستگاه ها در دسترس است. این مزیت اجرای دستگاه های مشتری ، مانند کاهش هزینه سرور ، تأخیر کم و افزایش حریم خصوصی را به همراه دارد.
- در حالی که بسیاری از ویژگی های مورد بحث در درجه اول مربوط به نویسندگان چارچوب است ، برنامه های شما می توانند بدون سربار زیاد سود ببرند.
- استانداردهای وب روان و در حال تحول است و ما همیشه به دنبال بازخورد هستیم. خود را برای WebAssembly و WebGPU به اشتراک بگذارید.
قدردانی
ما می خواهیم از تیم گرافیک وب اینتل ، که در رانندگی WebGPU F16 و ویژگی های بسته بندی شده محصول Integer Dot مؤثر بودند ، تشکر کنیم. ما می خواهیم از سایر اعضای گروه کاری WebAssembly و WebGPU در W3C ، از جمله سایر فروشندگان مرورگر تشکر کنیم.
از تیم های هوش مصنوعی و ML هم در Google و هم در جامعه منبع باز بخاطر شرکای باورنکردنی تشکر می کنم. و البته ، همه هم تیمی های ما که همه اینها را ممکن می سازند.
،این سند ادامه WebAssembly و پیشرفتهای WebGPU برای وب AI سریعتر ، قسمت 1 است. توصیه می کنیم قبل از ادامه این پست را بخوانید یا صحبت را در IO 24 تماشا کنید .
WebGPU
WebGPU به برنامه های وب امکان دسترسی به سخت افزار GPU مشتری را برای انجام محاسبات کارآمد و بسیار موازی می دهد. از زمان راه اندازی WebGPU در Chrome ، ما نمایشی های باورنکردنی از هوش مصنوعی (AI) و یادگیری ماشین (ML) را در وب مشاهده کرده ایم.
به عنوان مثال ، انتشار پایدار وب نشان داد که استفاده از AI برای تولید تصاویر از متن ، مستقیماً در مرورگر امکان پذیر است. در اوایل سال جاری ، تیم MediaPipe خود Google پشتیبانی آزمایشی را برای استنباط مدل زبان بزرگ منتشر کرد.
انیمیشن زیر نشان می دهد Gemma ، مدل زبان بزرگ منبع باز گوگل (LLM) ، که کاملاً در حال کار در کروم است ، در زمان واقعی.
نسخه ی نمایشی در آغوش گرفتن چهره از بخش متا هر چیزی ، ماسک های شیء با کیفیت بالا را کاملاً بر روی مشتری تولید می کند.
اینها فقط چند پروژه شگفت انگیز هستند که قدرت WebGPU را برای AI و ML نشان می دهند. WebGPU به این مدل ها و سایر موارد اجازه می دهد تا به طور قابل توجهی سریعتر از آنچه در CPU می توانند اجرا کنند.
بغل کردن معیار WebGPU Face Face برای تعبیه متن ، سرعت فوق العاده ای را در مقایسه با اجرای CPU از همان مدل نشان می دهد. در لپ تاپ Apple M1 Max ، WebGPU بیش از 30 برابر سریعتر بود. برخی دیگر گزارش داده اند که WebGPU بیش از 120 بار معیار را تسریع می کند.
بهبود ویژگی های WebGPU برای AI و ML
WebGPU برای مدل های AI و ML بسیار عالی است ، که به لطف پشتیبانی از سایه بان های محاسباتی ، می توانند میلیاردها پارامتر داشته باشند. سایه بان های محاسباتی روی GPU اجرا می شوند و به انجام عملیات آرایه موازی بر روی حجم زیادی از داده ها کمک می کنند.
در میان پیشرفت های بیشمار WebGPU در سال گذشته ، ما همچنان به قابلیت های بیشتری برای بهبود عملکرد ML و AI در وب اضافه کرده ایم. به تازگی ، ما دو ویژگی جدید را راه اندازی کردیم: نقطه شناور 16 بیتی و محصولات عدد عدد صحیح بسته بندی شده.
نقطه شناور 16 بیتی
به یاد داشته باشید ، بارهای کاری ML به دقت احتیاج ندارند . shader-f16 ویژگی ای است که امکان استفاده از نوع F16 در زبان سایه زنی WebGPU را فراهم می کند. این نوع نقطه شناور به جای 32 بیت معمول ، 16 بیت را به خود اختصاص می دهد. F16 دامنه کمتری دارد و دقیق تر است ، اما برای بسیاری از مدل های ML ، این کافی است.
این ویژگی از چند طریق بهره وری را افزایش می دهد:
کاهش حافظه : تانسور با عناصر F16 نیمی از فضا را به خود اختصاص می دهد ، که استفاده از حافظه را به نصف کاهش می دهد. محاسبات GPU اغلب در پهنای باند حافظه تنگنا می شوند ، بنابراین نیمی از حافظه اغلب می تواند به معنای سایه بان دو برابر سریع باشد. از نظر فنی ، برای ذخیره در پهنای باند حافظه به F16 احتیاج ندارید. می توان داده ها را با فرمت با دقت پایین ذخیره کرد و سپس آن را به Flile F32 در سایه بان برای محاسبه گسترش داد. اما ، GPU انرژی محاسباتی اضافی را برای بسته بندی و باز کردن داده ها صرف می کند.
کاهش تبدیل داده ها : F16 با به حداقل رساندن تبدیل داده ها از محاسبه کمتری استفاده می کند. داده های با دقت پایین را می توان ذخیره کرد و سپس مستقیماً بدون تبدیل استفاده کرد.
افزایش موازی : GPU های مدرن قادر به قرار دادن مقادیر بیشتر به طور همزمان در واحدهای اجرای GPU هستند و به آن امکان می دهد تعداد بیشتری از محاسبات موازی را انجام دهد. به عنوان مثال ، یک GPU که حداکثر 5 تریلیون عملیات F32 را در هر ثانیه پشتیبانی می کند ممکن است از 10 تریلیون عملیات F16 Floating-Point در ثانیه پشتیبانی کند.
shader-f16 ، در آغوش گرفتن معیار WebGPU Face برای متن تعبیه شده ، معیار را 3 بار سریعتر از F32 در لپ تاپ Apple M1 Max اجرا می کند.Webllm یک پروژه است که می تواند چندین مدل بزرگ زبان را اجرا کند. از Apache TVM ، یک چارچوب کامپایلر یادگیری ماشین منبع باز استفاده می کند.
من از Webllm خواستم تا با استفاده از مدل پارامتر هشت میلیارد Llama 3 ، سفر به پاریس را برنامه ریزی کند. نتایج نشان می دهد که در مرحله مقدماتی مدل ، F16 2.1 برابر سریعتر از F32 است. در مرحله رمزگشایی ، بیش از 1.3 برابر سریعتر است.
برنامه های کاربردی ابتدا باید تأیید کنند که آداپتور GPU از F16 پشتیبانی می کند و در صورت وجود ، صریحاً هنگام درخواست دستگاه GPU آن را فعال کنید. اگر F16 پشتیبانی نمی شود ، شما نمی توانید آن را در آرایه requiredFeatures درخواست کنید.
// main.js
const adapter = await navigator.gpu.requestAdapter();
const supportsF16 = adapter.features.has('shader-f16');
if (supportsF16) {
// Use f16.
const device = await adapter.requestDevice({
requiredFeatures: ['shader-f16'],
});
initApp(device);
}
سپس ، در سایه های WebGPU خود ، باید صریحاً F16 را در بالا فعال کنید. پس از آن ، شما می توانید مانند هر نوع داده دیگر شناور از آن در سایه بان استفاده کنید.
// my-shader.wgsl
enable f16;
struct Data {
values : array<vec4<f16>>
}
@group(0) @binding(0) var<storage, read> data : Data;
@compute @workgroup_size(64) fn main(@builtin(global_invocation_id) gid : vec3u) {
let value : vec4<f16> = data.values[gid.x];
...
}
محصولات نقطه عدد صحیح بسته بندی شده
بسیاری از مدل ها هنوز هم با 8 بیت دقت (نیمی از F16) خوب کار می کنند. این در بین LLM ها و مدل های تصویر برای تقسیم بندی و تشخیص شی محبوب است. گفته می شود ، کیفیت خروجی برای مدل ها با دقت کمتری تخریب می شود ، بنابراین کمیت 8 بیتی برای هر برنامه مناسب نیست.
نسبتاً معدود GPU های بومی از مقادیر 8 بیتی پشتیبانی می کنند. این جایی است که محصولات نقطه عدد صحیح بسته بندی شده وارد می شوند. ما DP4A را در Chrome 123 حمل کردیم.
GPU های مدرن دستورالعمل های ویژه ای برای گرفتن دو عدد صحیح 32 بیتی دارند ، هر کدام را به عنوان 4 عدد صحیح 8 بیتی بسته بندی شده متوالی تفسیر می کنند و محصول DOT را بین اجزای خود محاسبه می کنند.
این امر به ویژه برای AI و یادگیری ماشین مفید است زیرا هسته های ضرب ماتریس از بسیاری از محصولات DOT تشکیل شده اند.
به عنوان مثال ، بیایید یک ماتریس 4 x 8 را با یک بردار 8 x 1 ضرب کنیم. محاسبه این امر شامل مصرف 4 محصول برای محاسبه هر یک از مقادیر موجود در بردار خروجی است. A ، B ، C و D.
فرآیند محاسبه هر یک از این خروجی ها یکسان است ؛ ما به مراحل مربوط به محاسبه یکی از آنها نگاه خواهیم کرد. قبل از هر محاسبه ، ما ابتدا باید داده های عدد صحیح 8 بیتی را به نوعی تبدیل کنیم که می توانیم حسابی را با آن انجام دهیم ، مانند F16. سپس ، ما یک ضرب عناصر را اجرا می کنیم و در آخر ، تمام محصولات را با هم اضافه می کنیم. در کل ، برای کل ضرب ماتریس بردار ، ما 40 عدد صحیح را برای تبدیل شناورها برای باز کردن داده ها ، 32 ضرب شناور و 28 مورد اضافی شناور انجام می دهیم.
برای ماتریس های بزرگتر با عملیات بیشتر ، محصولات نقطه عدد صحیح بسته بندی شده می توانند به کاهش میزان کار کمک کنند.
برای هر یک از خروجی ها در وکتور نتیجه ، ما دو عملیات محصول بسته بندی شده DOT را با استفاده از زبان سایه زنی WebGPU داخلی dot4U8Packed انجام می دهیم و سپس نتایج را به هم اضافه می کنیم. در کل ، برای کل ضرب ماتریس بردار ، ما هیچ تبدیل داده ای را انجام نمی دهیم. ما 8 محصول نقطه بسته بندی شده و 4 عدد عدد صحیح را اجرا می کنیم.
ما محصولات نقطه عدد صحیح بسته بندی شده را با داده های 8 بیتی در انواع GPU های مصرف کننده آزمایش کردیم. در مقایسه با نقطه شناور 16 بیتی ، می بینیم که 8 بیتی 1.6 تا 2.8 برابر سریعتر است. هنگامی که ما علاوه بر این از محصولات عدد عدد صحیح بسته بندی شده استفاده می کنیم ، عملکرد حتی بهتر است. 1.7 تا 2.9 برابر سریعتر است.
پشتیبانی از مرورگر را با ویژگی wgslLanguageFeatures بررسی کنید. اگر GPU به طور بومی از محصولات DOT بسته بندی شده پشتیبانی نمی کند ، مرورگر پیاده سازی خود را به صورت خاص انجام می دهد.
// main.js
if (navigator.gpu.wgslLanguageFeatures.has('packed_4x8_integer_dot_product')) {
// Use dot4U8Packed, dot4I8Packed builtin
// functions in the shaders.
}
قطعه کد زیر متفاوت است (تفاوت) برجسته تغییرات مورد نیاز برای استفاده از محصولات عدد صحیح بسته بندی شده در یک سایه بان WebGPU.
قبل از آن - یک سایه بان WebGPU که محصولات DOT جزئی را به متغیر "جمع" جمع می کند. در انتهای حلقه ، "Sum" محصول کامل DOT را بین یک بردار و یک ردیف ماتریس ورودی نگه می دارد.
// my-dot-product.wgsl @compute @workgroup_size(64) fn main(@builtin(global_invocation_id) gid : vec3u) { var sum : f16; let start = gid.x * uniforms.dim; for (var i = 0u; i < uniforms.dim; i++) { let v1 : vec4<f16> = vector.values[i]; let v2 : vec4<f16> = matrix.values[start + i]; sum += dot(v1, v2); } }
پس از - یک سایه بان WebGPU که برای استفاده از محصولات عدد عدد صحیح بسته بندی شده نوشته شده است. تفاوت اصلی این است که به جای بارگیری 4 مقادیر شناور از بردار و ماتریس ، این سایه بان یک عدد صحیح 32 بیتی را بارگیری می کند. این عدد صحیح 32 بیتی داده های چهار مقدار عدد صحیح 8 بیتی را در اختیار دارد. سپس ، ما برای محاسبه محصول نقطه ای از دو مقدار dot4U8Packed تماس می گیریم.
// my-dot-product.wgsl
@compute @workgroup_size(64)
fn main(@builtin(global_invocation_id) gid : vec3u) {
var sum : f32;
let start = gid.x * uniforms.dim;
for (var i = 0u; i < uniforms.dim; i++) {
let v1 : u32 = vector.values[i];
let v2 : u32 = matrix.values[start + i];
sum += dot4U8Packed(v1, v2);
}
}
هر دو نقطه شناور 16 بیتی و محصولات نقطه عدد صحیح بسته بندی شده از ویژگی های حمل شده در Chrome هستند که AI و ML را تسریع می کنند. هنگامی که سخت افزار از آن پشتیبانی می کند ، نقطه شناور 16 بیتی در دسترس است و Chrome محصولات عدد عدد صحیح بسته بندی شده را در همه دستگاه ها پیاده سازی می کند.
امروز می توانید از این ویژگی ها در Chrome Stable برای دستیابی به عملکرد بهتر استفاده کنید.
ویژگی های پیشنهادی
با نگاه به جلو ، ما در حال بررسی دو ویژگی دیگر هستیم: زیر گروه ها و ماتریس تعاونی را ضرب می کنیم.
ویژگی زیر گروه ها موازی با سطح SIMD را قادر می سازد تا ارتباطات یا انجام عملیات ریاضی جمعی مانند مبلغی را برای بیش از 16 شماره انجام دهند. این امکان به اشتراک گذاری داده های متقاطع کارآمد را فراهم می کند. زیر گروه ها در API های GPU های مدرن ، با نام های مختلف و به اشکال کمی متفاوت پشتیبانی می شوند.
ما مجموعه مشترک را به پیشنهادی که به گروه استاندارد سازی WebGPU گرفته ایم ، تقطیر کرده ایم. و ، ما زیر گروه های اولیه را در Chrome در پشت پرچم آزمایشی نمونه برداری کرده ایم و نتایج اولیه خود را در بحث قرار داده ایم. مسئله اصلی نحوه اطمینان از رفتار قابل حمل است.
ماتریس تعاونی Multiply علاوه بر جدیدترین GPU ها است. یک ماتریس بزرگ ضرب می تواند به ضرب ماتریس چندگانه کوچکتر تقسیم شود. ماتریس تعاونی ضرب در این بلوک های کوچکتر در یک مرحله منطقی واحد ضرب می کند. در آن مرحله ، گروهی از موضوعات برای محاسبه نتیجه به طور مؤثر همکاری می کنند.
ما پشتیبانی را در API های GPU اساسی مورد بررسی قرار دادیم و قصد داریم پیشنهادی را به گروه استاندارد سازی WebGPU ارائه دهیم. مانند زیر گروه ها ، ما انتظار داریم که بخش اعظم بحث در مورد قابلیت حمل باشد.
برای ارزیابی عملکرد عملیات زیر گروه ، در یک برنامه واقعی ، ما پشتیبانی آزمایشی برای زیر گروه ها را به MediaPipe یکپارچه کردیم و آن را با نمونه اولیه Chrome برای عملیات زیر گروه آزمایش کردیم.
ما از زیر گروه ها در هسته های پردازنده گرافیکی فاز مقدمه مدل زبان بزرگ استفاده کردیم ، بنابراین من فقط گزارش سرعت را برای مرحله مقدماتی گزارش می دهم. در یک GPU اینتل ، می بینیم که زیر گروه ها دو و نیم بار سریعتر از پایه انجام می دهند. با این حال ، این پیشرفت ها در بین GPU های مختلف سازگار نیستند.
نمودار بعدی نتایج استفاده از زیر گروه ها را برای بهینه سازی یک ماتریس ضرب میکروب مارک در چندین GPU های مصرف کننده نشان می دهد. ضرب ماتریس یکی از عملیات سنگین تر در مدلهای بزرگ زبان است. داده ها نشان می دهد که در بسیاری از GPU ها ، زیر گروه ها سرعت دو ، پنج و حتی سیزده بار پایه را افزایش می دهند. با این حال ، توجه کنید که در اولین GPU ، زیر گروه ها به هیچ وجه بهتر نیستند.
بهینه سازی GPU دشوار است
در نهایت ، بهترین راه برای بهینه سازی GPU شما به آنچه GPU مشتری ارائه می دهد بستگی دارد. استفاده از ویژگی های جدید GPU فانتزی همیشه به شکلی که انتظار دارید پرداخت نمی کند ، زیرا می توان عوامل پیچیده زیادی را درگیر کرد. بهترین استراتژی بهینه سازی در یک GPU ممکن است بهترین استراتژی در GPU دیگر نباشد.
شما می خواهید پهنای باند حافظه را به حداقل برسانید ، در حالی که به طور کامل از موضوعات محاسباتی GPU استفاده می کنید.
الگوهای دسترسی به حافظه نیز می تواند بسیار مهم باشد. GPU ها هنگامی که موضوعات محاسباتی به حافظه دسترسی پیدا می کنند در الگویی که برای سخت افزار بهینه است ، بسیار بهتر عمل می کنند. نکته مهم: شما باید از ویژگی های مختلف عملکرد در سخت افزار مختلف GPU انتظار داشته باشید. بسته به GPU ممکن است نیاز به بهینه سازی های مختلف داشته باشید.
در نمودار زیر ، ما همان الگوریتم ضرب ماتریس را در نظر گرفته ایم ، اما ابعاد دیگری را برای نشان دادن تأثیر استراتژی های مختلف بهینه سازی و پیچیدگی و واریانس در GPU های مختلف اضافه کرده ایم. ما یک تکنیک جدید را در اینجا معرفی کرده ایم که آن را "Swizzle" می نامیم. Swizzle الگوهای دسترسی به حافظه را بهینه تر می کند تا برای سخت افزار بهینه تر باشد.
می بینید که Swizzle حافظه تأثیر قابل توجهی دارد. این گاهی اوقات حتی بیشتر از زیر گروه ها تأثیرگذار است. در GPU 6 ، Swizzle سرعت 12 برابر را فراهم می کند ، در حالی که زیر گروه ها سرعت 13 برابر را ارائه می دهند. ترکیبی ، آنها یک سرعت فوق العاده 26 برابر باورنکردنی دارند. برای سایر GPU ها ، گاهی اوقات swizzle و زیر گروه ها ترکیب بهتر از هر یک به تنهایی هستند. و در سایر GPU ها ، منحصراً استفاده از Swizzle بهترین عملکرد را انجام می دهد.
تنظیم و بهینه سازی الگوریتم های GPU برای کار به خوبی در هر قطعه سخت افزار ، می تواند به تخصص زیادی نیاز داشته باشد. اما خوشبختانه کار فوق العاده ای از کار با استعداد در چارچوب های کتابخانه های سطح بالاتر وجود دارد ، مانند MediaPipe ، Transformers.js ، Apache TVM ، ONNX Runtime Web و موارد دیگر.
کتابخانه ها و چارچوب ها برای رسیدگی به پیچیدگی مدیریت معماری های متنوع GPU و تولید کد خاص پلت فرم که به خوبی روی مشتری اجرا می شود ، از موقعیت خوبی برخوردار هستند.
غذای آماده
تیم Chrome همچنان به تکامل استانداردهای WebAssembly و WebGPU برای بهبود بستر وب برای بارهای یادگیری ماشین کمک می کند. ما در حال سرمایه گذاری در ابتدایی های محاسباتی سریعتر ، بهتر از استانداردهای وب هستیم و اطمینان حاصل می کنیم که مدل های بزرگ و کوچک قادر به اجرای کارآمد در دستگاه ها هستند.
هدف ما این است که ضمن حفظ بهترین های وب ، به حداکثر رساندن قابلیت های این سکو بمانیم: این دسترسی ، قابلیت استفاده و قابلیت حمل است. و ما این کار را به تنهایی انجام نمی دهیم. ما با همکاری سایر فروشندگان مرورگر در W3C و بسیاری از شرکای توسعه کار می کنیم.
ما امیدواریم که موارد زیر را به خاطر بسپارید ، همانطور که با WebAssembly و WebGPU کار می کنید:
- استنباط هوش مصنوعی هم اکنون در وب ، در سراسر دستگاه ها در دسترس است. این مزیت اجرای دستگاه های مشتری ، مانند کاهش هزینه سرور ، تأخیر کم و افزایش حریم خصوصی را به همراه دارد.
- در حالی که بسیاری از ویژگی های مورد بحث در درجه اول مربوط به نویسندگان چارچوب است ، برنامه های شما می توانند بدون سربار زیاد سود ببرند.
- استانداردهای وب روان و در حال تحول است و ما همیشه به دنبال بازخورد هستیم. خود را برای WebAssembly و WebGPU به اشتراک بگذارید.
قدردانی
ما می خواهیم از تیم گرافیک وب اینتل ، که در رانندگی WebGPU F16 و ویژگی های بسته بندی شده محصول Integer Dot مؤثر بودند ، تشکر کنیم. ما می خواهیم از سایر اعضای گروه کاری WebAssembly و WebGPU در W3C ، از جمله سایر فروشندگان مرورگر تشکر کنیم.
از تیم های هوش مصنوعی و ML هم در Google و هم در جامعه منبع باز بخاطر شرکای باورنکردنی تشکر می کنم. و البته ، همه هم تیمی های ما که همه اینها را ممکن می سازند.