
了解 WebAssembly 和 WebGPU 增强功能如何提升 Web 上机器学习的性能。



网络上的 AI 推理
我们都听过这样的故事:AI 正在改变我们的世界。网络也不例外。
今年,Chrome 新增了生成式 AI 功能,包括创建自定义主题,以及帮助您撰写初稿。但 AI 的功能远不止这些;AI 可以丰富 Web 应用本身。
网页可以嵌入智能组件,用于视觉(例如挑选人脸或识别手势)、音频分类或语言检测。在过去一年里,我们看到生成式 AI 的蓬勃发展,包括一些非常令人印象深刻的 Web 大语言模型演示。请务必查看面向 Web 开发者的实用设备端 AI。
目前,Web 上的 AI 推理可在大部分设备上使用,并且 AI 处理可以在网页本身中进行,利用用户设备上的硬件。
这非常有用,原因如下:
- 降低费用:在浏览器客户端上运行推理可以显著降低服务器费用,这对于 GenAI 查询尤其有用,因为 GenAI 查询的费用可能比常规查询高出几个数量级。
- 延迟时间:对于对延迟时间特别敏感的应用(例如音频或视频应用),将所有处理都放在设备上进行可缩短延迟时间。
- 隐私:在客户端上运行,还可能解锁需要增强隐私保护的新类应用,其中数据无法发送到服务器。
AI 工作负载目前在 Web 上运行的方式
目前,应用开发者和研究人员使用框架构建模型,模型使用 Tensorflow.js 或 ONNX Runtime Web 等运行时在浏览器中执行,而运行时则使用 Web API 进行执行。
所有这些运行时最终都会通过 JavaScript 或 WebAssembly 在 CPU 上运行,或者通过 WebGL 或 WebGPU 在 GPU 上运行。
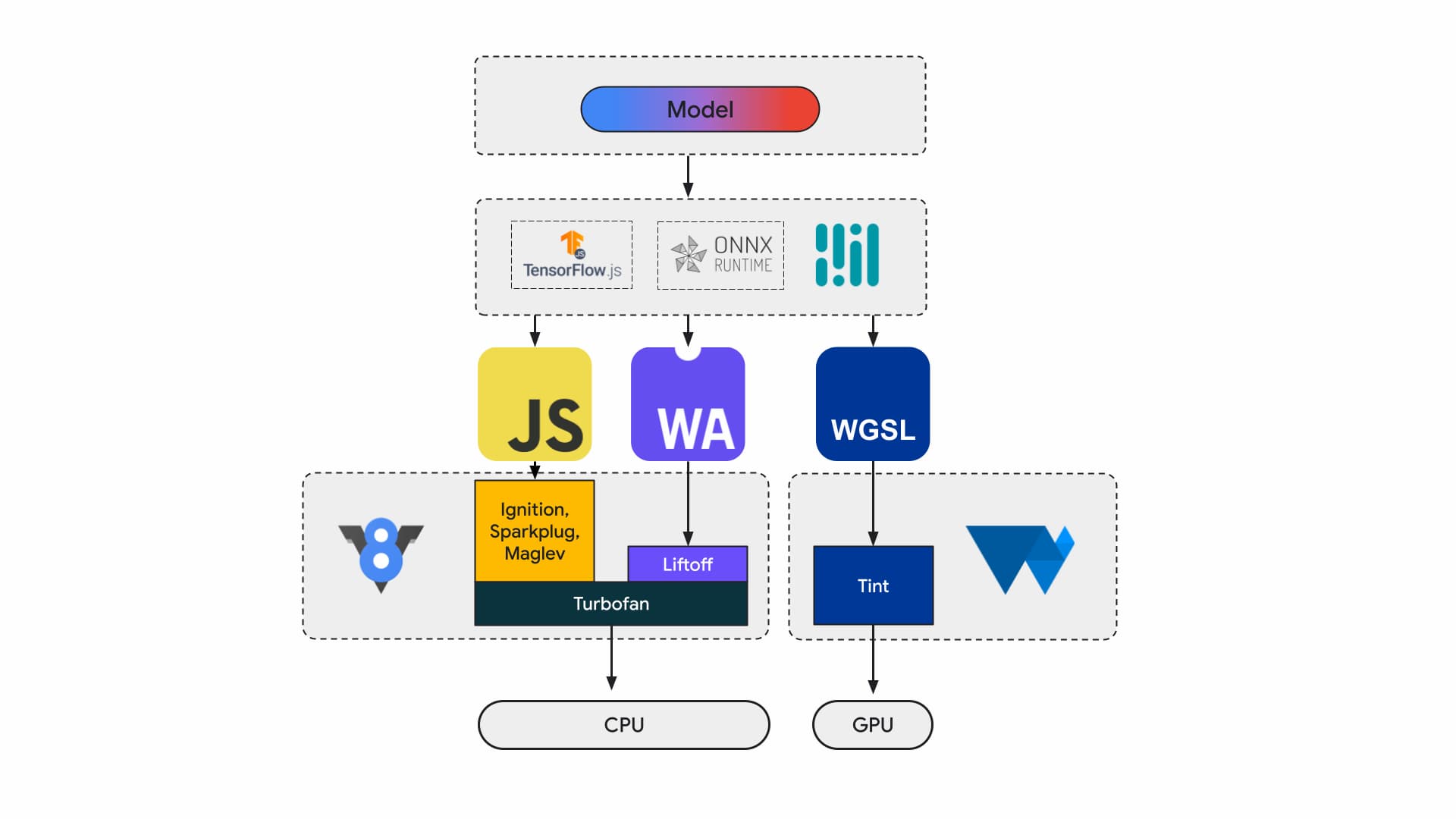
机器学习工作负载
机器学习 (ML) 工作负载会通过计算节点图推送张量。张量是这些节点的输入和输出,这些节点会对数据执行大量计算。
这一点很重要,因为:
- 张量是一种非常庞大的数据结构,可对可能具有数十亿个权重的模型执行计算
- 扩缩和推理可能会导致数据并行处理。这意味着,对张量中的所有元素执行相同的操作。
- 机器学习不需要精确性。您可能需要 64 位浮点数才能登月,但可能只需要 8 位数或更少的数字即可进行人脸识别。
幸运的是,芯片设计师添加了一些功能,让模型可以更快、更凉爽地运行,甚至可以正常运行。
与此同时,WebAssembly 和 WebGPU 团队正在努力向 Web 开发者提供这些新功能。如果您是 Web 应用开发者,则不太可能经常使用这些低级基元。我们预计您使用的工具链或框架将支持新功能和扩展程序,因此您只需对基础架构进行最少的更改,即可受益。不过,如果您想手动调整应用以提升性能,这些功能就与您的工作相关。
WebAssembly
WebAssembly (Wasm) 是一种紧凑、高效的字节码格式,运行时可以理解和执行。它旨在利用底层硬件功能,因此可以以接近原生速度执行。该代码会在内存安全的沙盒化环境中进行验证和执行。
Wasm 模块信息使用密集二进制编码表示。与基于文本的格式相比,这意味着解码速度更快、加载速度更快,并且内存用量更少。它是可移植的,这意味着它不会对现代架构中不常见的底层架构做出假设。
WebAssembly 规范是迭代性的,由开放的 W3C 社区群组负责制定。
二进制格式不会对主机环境做出任何假设,因此它也适用于非 Web 嵌入。
您的应用只需编译一次,即可在任何设备上运行:桌面设备、笔记本电脑、手机或任何其他内置浏览器的设备。如需详细了解,请参阅WebAssembly 终于实现了“一次编写,到处运行”。
大多数在 Web 上运行 AI 推理的生产应用都使用 WebAssembly,既用于 CPU 计算,也用于与专用计算接口。在原生应用中,您可以同时访问通用计算和专用计算,因为应用可以访问设备功能。
在 Web 上,为了实现可移植性和安全性,我们会仔细评估要公开的一组基元。这样可以平衡 Web 的易用性与硬件提供的最大性能。
WebAssembly 是 CPU 的可移植抽象,因此所有 Wasm 推理都在 CPU 上运行。虽然这不是性能最高的选择,但 CPU 广泛可用,可在大多数设备上处理大多数工作负载。
对于较小的工作负载(例如文本或音频工作负载),GPU 的费用会很高。以下是一些近期的示例,其中 Wasm 是正确的选择:
- Adobe 使用 Tensorflow.js 增强了 Photoshop Web。
- Google Meet 添加了背景虚化,这是网络上首批基于 Wasm 的视频效果之一。
- YouTube 提供多种增强现实效果。
- Google 相册支持在线编辑。
您还可以在开源演示中探索更多内容,例如 whisper-tiny、llama.cpp 和在浏览器中运行的 Gemma2B。
全面考虑应用
您应根据特定机器学习模型、应用基础架构以及为用户提供的整体预期应用体验来选择基元
例如,在 MediaPipe 的人脸地标检测中,CPU 推理和 GPU 推理相当(在 Apple M1 设备上运行),但有些模型的差异可能会明显更大。
对于机器学习工作负载,我们会从整体应用视角出发,同时倾听框架作者和应用合作伙伴的意见,以开发并发布最受欢迎的增强功能。这些问题大致可分为三类:
- 公开对性能至关重要的 CPU 扩展
- 支持运行更大的模型
- 支持与其他 Web API 无缝互操作
更快的计算
目前,WebAssembly 规范仅包含我们向 Web 公开的一组指令。但硬件会不断添加新指令,这会拉大原生代码和 WebAssembly 性能之间的差距。
请注意,机器学习模型并不总是需要高精度。放宽型 SIMD 是一种提案,旨在减少一些严格的不确定性要求,从而加快对一些性能热点矢量运算的代码生成速度。此外,放宽型 SIMD 还引入了新的点积和 FMA 指令,可将现有工作负载的速度提高 1.5 到 3 倍。此功能已在 Chrome 114 中发布。
半精度浮点格式使用 16 位 IEEE FP16,而不是使用 32 位单精度值。与单精度值相比,使用半精度值具有多项优势,包括降低内存要求,从而能够训练和部署更大的神经网络,以及降低内存带宽。降低精度可加快数据传输和数学运算速度。
更大的模型
指向 Wasm 线性内存的指针以 32 位整数表示。这会产生两个后果:堆大小限制为 4GB(当计算机的实际 RAM 远远大于此时),并且以 Wasm 为目标平台的应用代码必须与 32 位指针大小兼容。
尤其是对于目前的大型模型,将这些模型加载到 WebAssembly 中可能会受到限制。Memory64 提案通过使线性内存大于 4GB 且与原生平台的地址空间匹配来移除这些限制。
我们已在 Chrome 中实现了完整的功能,预计将于今年晚些时候发布。目前,您可以使用标志 chrome://flags/#enable-experimental-webassembly-features 运行实验,并向我们发送反馈。
更好的 Web 互操作性
WebAssembly 可以成为 Web 上专用计算的入口点。
WebAssembly 可用于将 GPU 应用引入到 Web 中。也就是说,只需进行少量修改,即可在设备上运行的同一 C++ 应用也可以在 Web 上运行。
Wasm 编译器工具链 Emscripten 已经有了 WebGPU 绑定。它是 Web 上 AI 推理的入口点,因此 Wasm 能够与 Web 平台的其余部分无缝互操作至关重要。我们正在研究几种不同的方案。
JavaScript promise 集成 (JSPI)
典型的 C 和 C++(以及许多其他语言)应用通常是针对同步 API 编写的。这意味着,在操作完成之前,应用将停止执行。与支持异步的应用相比,此类阻塞应用通常更易于编写。
当开销大的操作阻塞主线程时,它们可能会阻塞 I/O,并且用户会看到卡顿。原生应用的同步编程模型与 Web 的异步模型不匹配。对于需要耗费大量资源才能移植的旧版应用,这一点尤其重要。Emscripten 提供了一种使用 Asyncify 执行此操作的方法,但这并非始终是最佳选择,因为代码大小更大且效率较低。
以下示例使用 JavaScript Promise 进行加法来计算斐波那契数列。
long promiseFib(long x) {
if (x == 0)
return 0;
if (x == 1)
return 1;
return promiseAdd(promiseFib(x - 1), promiseFib(x - 2));
}
// promise an addition
EM_ASYNC_JS(long, promiseAdd, (long x, long y), {
return Promise.resolve(x+y);
});
emcc -O3 fib.c -o b.html -s ASYNCIFY=2
在此示例中,请注意以下事项:
EM_ASYNC_JS宏会生成所有必要的粘合代码,以便我们使用 JSPI 访问 promise 的结果,就像使用普通函数一样。- 特殊的命令行选项
-s ASYNCIFY=2。这会调用用于生成代码的选项,该代码使用 JSPI 与返回 Promise 的 JavaScript 导入进行接口通信。
如需详细了解 JSPI、其使用方法和优势,请参阅 Introducing the WebAssembly JavaScript Promise Integration API on v8.dev(介绍 v8.dev 上的 WebAssembly JavaScript Promise Integration API)。了解当前源代码试用版。
内存控制
开发者对 Wasm 内存的控制非常有限;模块拥有自己的内存。任何需要访问此内存的 API 都必须进行复制进出,而这种使用量可能会累积起来。例如,图形应用可能需要针对每个帧进行复制和复制操作。
内存控制提案旨在对 Wasm 线性内存提供更精细的控制,并减少应用流水线中的复制次数。此提案目前处于第 1 阶段,我们正在 Chrome 的 JavaScript 引擎 V8 中对其进行原型设计,以便为该标准的演变提供参考。
确定适合您的后端
虽然 CPU 无处不在,但并非始终是最佳选择。GPU 或加速器上的专用计算可以提供高出一个数量级的性能,尤其是对于较大的模型和高端设备。这对原生应用和 Web 应用都适用。
您选择哪种后端取决于应用、框架或工具链,以及影响性能的其他因素。尽管如此,我们仍会继续投资于各种提案,以便核心 Wasm 能够与 Web 平台的其余部分(尤其是 WebGPU)良好协作。