
Ontdek hoe WebAssembly- en WebGPU-verbeteringen de prestaties van machine learning op internet verbeteren.



AI-gevolgtrekking op internet
We hebben allemaal het verhaal gehoord: AI transformeert onze wereld. Het internet is daarop geen uitzondering.
Dit jaar heeft Chrome generatieve AI-functies toegevoegd, waaronder het maken van aangepaste thema's en/of het helpen bij het schrijven van een eerste concepttekst . Maar AI is veel meer dan dat; AI kan webapplicaties zelf verrijken.
Webpagina's kunnen intelligente componenten insluiten voor visie, zoals het uitkiezen van gezichten of het herkennen van gebaren, voor audioclassificatie of voor taaldetectie. Het afgelopen jaar hebben we generatieve AI een vlucht zien nemen, waaronder enkele werkelijk indrukwekkende demo's van grote taalmodellen op internet. Zorg ervoor dat u Praktische AI op het apparaat voor webontwikkelaars eens bekijkt.
AI-inferentie op internet is tegenwoordig beschikbaar op een groot aantal apparaten, en AI-verwerking kan plaatsvinden op de webpagina zelf, waarbij gebruik wordt gemaakt van de hardware op het apparaat van de gebruiker.
Dit is om verschillende redenen krachtig:
- Lagere kosten : het uitvoeren van inferentie op de browserclient verlaagt de serverkosten aanzienlijk, en dit kan vooral handig zijn voor GenAI-query's, die een orde van grootte duurder kunnen zijn dan gewone query's.
- Latentie : voor toepassingen die bijzonder gevoelig zijn voor latentie, zoals audio- of videotoepassingen, leidt het feit dat al uw verwerking op het apparaat plaatsvindt tot een verminderde latentie.
- Privacy : Draaien aan de clientzijde heeft ook het potentieel om een nieuwe klasse applicaties te ontsluiten die meer privacy vereisen, waarbij gegevens niet naar de server kunnen worden verzonden.
Hoe AI-workloads tegenwoordig op internet worden uitgevoerd
Tegenwoordig bouwen applicatieontwikkelaars en onderzoekers modellen met behulp van frameworks, worden modellen uitgevoerd in de browser met behulp van een runtime zoals Tensorflow.js of ONNX Runtime Web , en maken runtimes gebruik van web-API's voor uitvoering.
Al die runtimes komen uiteindelijk uit op draaien op de CPU via JavaScript of WebAssembly of op de GPU via WebGL of WebGPU.
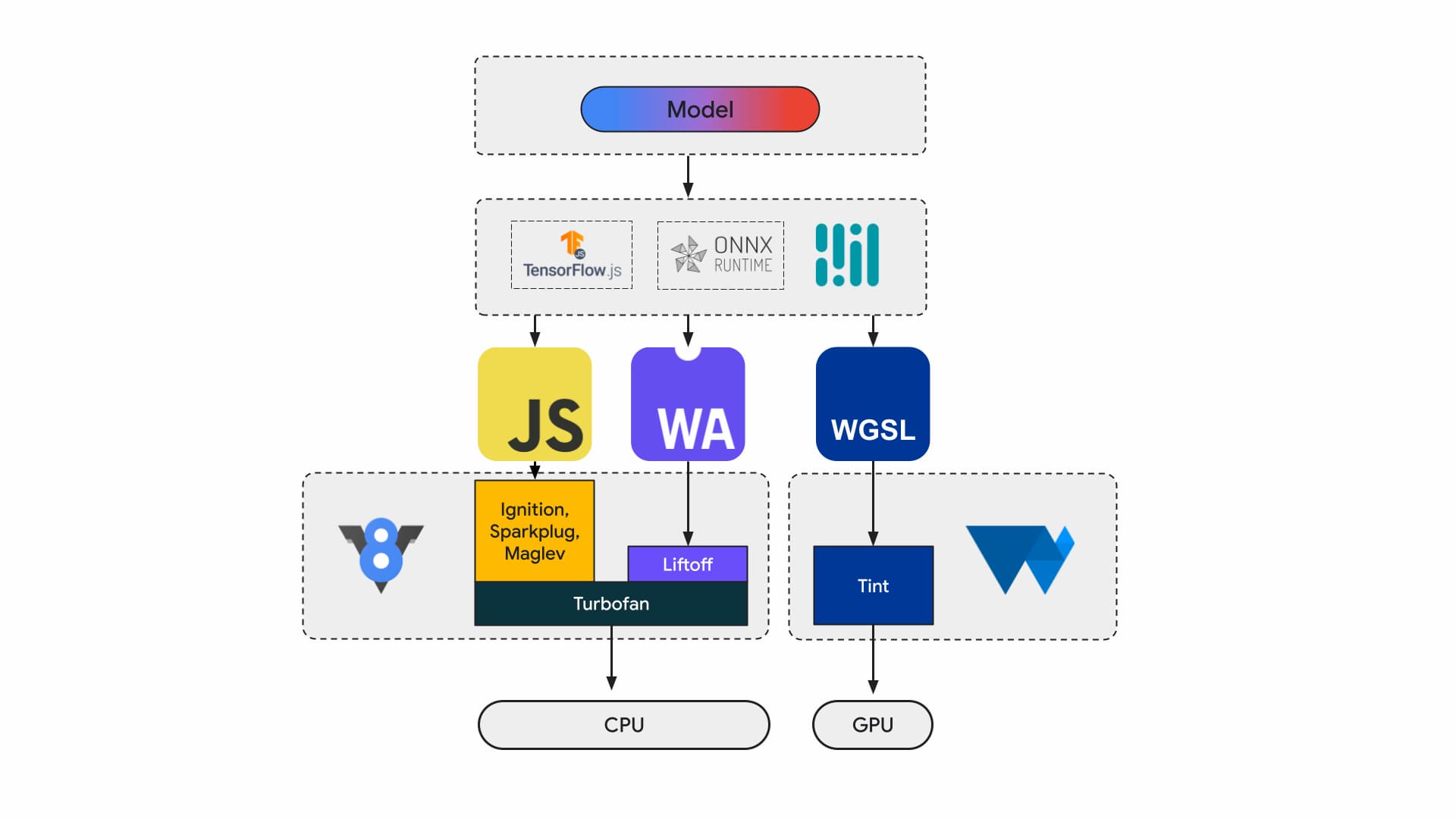
Machine learning-werklasten
Machine learning (ML)-workloads duwen tensoren door een grafiek van computationele knooppunten. Tensoren zijn de in- en uitgangen van deze knooppunten die een grote hoeveelheid berekeningen op de gegevens uitvoeren.
Dit is belangrijk omdat:
- Tensoren zijn zeer grote datastructuren, die berekeningen uitvoeren op modellen die miljarden gewichten kunnen hebben
- Schalen en gevolgtrekkingen kunnen leiden tot gegevensparallellisme . Dit betekent dat dezelfde bewerkingen worden uitgevoerd op alle elementen in de tensoren.
- ML vereist geen precisie. Mogelijk hebt u een 64-bits drijvende-kommagetal nodig om op de maan te landen, maar voor gezichtsherkenning heeft u mogelijk slechts een zee van 8-bits getallen of minder nodig.
Gelukkig hebben chipontwerpers functies toegevoegd om modellen sneller en koeler te laten werken, en het zelfs mogelijk te maken ze überhaupt te gebruiken.
Ondertussen werken we hier bij de WebAssembly- en WebGPU-teams eraan om deze nieuwe mogelijkheden toegankelijk te maken voor webontwikkelaars. Als u een ontwikkelaar van webapplicaties bent, is het onwaarschijnlijk dat u deze primitieven op laag niveau vaak zult gebruiken. We verwachten dat de toolchains of frameworks die u gebruikt nieuwe functies en uitbreidingen zullen ondersteunen, zodat u hiervan kunt profiteren met minimale wijzigingen aan uw infrastructuur. Maar als u de prestaties van uw applicaties handmatig wilt afstemmen, dan zijn deze functies relevant voor uw werk.
WebAssemblage
WebAssembly (Wasm) is een compact, efficiënt bytecodeformaat dat runtimes kunnen begrijpen en uitvoeren. Het is ontworpen om te profiteren van de onderliggende hardwaremogelijkheden, zodat het op vrijwel oorspronkelijke snelheden kan worden uitgevoerd. De code is gevalideerd en wordt uitgevoerd in een geheugenveilige sandbox-omgeving.
Wasm-module-informatie wordt weergegeven met een dichte binaire codering. In vergelijking met een op tekst gebaseerd formaat betekent dit snellere decodering, sneller laden en minder geheugengebruik. Het is draagbaar in de zin dat het geen aannames doet over de onderliggende architectuur die niet al gebruikelijk zijn in moderne architecturen.
De WebAssembly-specificatie is iteratief en er wordt aan gewerkt in een open W3C-gemeenschapsgroep .
Het binaire formaat maakt geen aannames over de hostomgeving en is dus ontworpen om ook goed te werken in niet-webinsluitingen.
Uw applicatie kan één keer worden samengesteld en overal worden uitgevoerd: een desktop, laptop, een telefoon of elk ander apparaat met een browser. Bekijk Write once, run anywhere, eindelijk gerealiseerd met WebAssembly, voor meer informatie hierover.
De meeste productietoepassingen die AI-inferentie op het web uitvoeren, maken gebruik van WebAssembly, zowel voor CPU-compute als voor de interface met speciale compute. Bij native applicaties hebt u toegang tot rekenkracht voor algemene en speciale doeleinden, aangezien de applicatie toegang heeft tot apparaatmogelijkheden.
Op internet evalueren we, met het oog op draagbaarheid en veiligheid, zorgvuldig welke reeks primitieven wordt blootgesteld. Dit brengt de toegankelijkheid van het web in evenwicht met maximale prestaties van de hardware.
WebAssembly is een draagbare abstractie van CPU's, dus alle Wasm-gevolgtrekkingen worden op de CPU uitgevoerd. Hoewel dit niet de meest performante keuze is, zijn CPU's overal verkrijgbaar en werken ze voor de meeste workloads en op de meeste apparaten.
Voor kleinere werklasten, zoals tekst- of audiowerklasten, zou GPU duur zijn. Er zijn een aantal recente voorbeelden waarbij Wasm de juiste keuze is:
- Adobe gebruikt Tensorflow.js om Photoshop voor het web te verbeteren .
- Google Meet heeft achtergrondvervaging toegevoegd , een van de eerste op Wasm gebaseerde video-effecten op internet.
- YouTube heeft verschillende augmented reality-effecten .
- Google Foto's maakt online bewerken mogelijk .
Je kunt nog meer ontdekken in open source-demo's, zoals: whistle-tiny , llama.cpp en Gemma2B die in de browser draaien .
Kies voor een holistische benadering van uw toepassingen
U moet primitieven kiezen op basis van het specifieke ML-model, de applicatie-infrastructuur en de algehele beoogde applicatie-ervaring voor gebruikers
Bij de gezichtsherkenningsdetectie van MediaPipe zijn CPU-inferentie en GPU-inferentie bijvoorbeeld vergelijkbaar (draait op een Apple M1-apparaat), maar er zijn modellen waarbij de variantie aanzienlijk groter zou kunnen zijn.
Als het gaat om ML-workloads, beschouwen we een holistische applicatievisie, terwijl we luisteren naar raamwerkauteurs en applicatiepartners, om de meest gevraagde verbeteringen te ontwikkelen en te leveren. Deze vallen grofweg in drie categorieën:
- Stel CPU-uitbreidingen bloot die cruciaal zijn voor de prestaties
- Schakel het gebruik van grotere modellen in
- Maak naadloze interoperabiliteit met andere web-API's mogelijk
Snellere rekenkracht
Zoals het er nu uitziet, bevat de WebAssembly-specificatie slechts een bepaalde reeks instructies die we op internet publiceren. Maar hardware blijft nieuwere instructies toevoegen die de kloof tussen native en WebAssembly-prestaties vergroten.
Houd er rekening mee dat ML-modellen niet altijd een hoog nauwkeurigheidsniveau vereisen. Relaxed SIMD is een voorstel dat enkele van de strikte, niet-deterministische vereisten vermindert, wat leidt tot snellere codegen voor sommige vectorbewerkingen die hotspots zijn voor de prestaties. Verder introduceert Relaxed SIMD een nieuw puntproduct en FMA-instructies die de bestaande werklast 1,5 tot 3 keer versnellen. Dit werd verzonden in Chrome 114.
Het drijvende-kommaformaat met halve precisie gebruikt 16 bits voor IEEE FP16 in plaats van de 32 bits die worden gebruikt voor waarden met enkele precisie. Vergeleken met waarden met enkele precisie zijn er verschillende voordelen bij het gebruik van waarden met halve precisie, verminderde geheugenvereisten, die training en implementatie van grotere neurale netwerken mogelijk maken, en verminderde geheugenbandbreedte. Verminderde precisie versnelt de gegevensoverdracht en wiskundige bewerkingen.
Grotere modellen
Pointers naar het lineaire Wasm-geheugen worden weergegeven als gehele getallen van 32 bits. Dit heeft twee gevolgen: de heapgrootte is beperkt tot 4 GB (wanneer computers veel meer fysiek RAM-geheugen hebben), en de applicatiecode die op Wasm is gericht, moet compatibel zijn met een 32-bits pointergrootte (die).
Vooral bij grote modellen zoals we die nu hebben, kan het laden van deze modellen in WebAssembly beperkend zijn. Het Memory64- voorstel heft deze beperkingen op door het lineaire geheugen groter te maken dan 4 GB en overeen te komen met de adresruimte van native platforms.
We hebben een volledig werkende implementatie in Chrome en zullen naar verwachting later dit jaar verschijnen. Voorlopig kunt u experimenten uitvoeren met de vlag chrome://flags/#enable-experimental-webassembly-features en ons feedback sturen.
Betere webinteroperabiliteit
WebAssembly zou het toegangspunt kunnen zijn voor computergebruik voor speciale doeleinden op internet.
WebAssembly kan worden gebruikt om GPU-applicaties naar het internet te brengen. Dat betekent dat dezelfde C++-applicatie die op het apparaat kan draaien, ook op internet kan draaien, met kleine aanpassingen.
Emscripten , de toolchain van de Wasm-compiler, heeft al bindingen voor WebGPU. Het is het startpunt voor AI-inferentie op internet, dus het is van cruciaal belang dat Wasm naadloos kan samenwerken met de rest van het webplatform. We werken op dit gebied aan een aantal verschillende voorstellen.
JavaScript-belofte-integratie (JSPI)
Typische C- en C++-toepassingen (evenals vele andere talen) worden gewoonlijk geschreven tegen een synchrone API. Dit betekent dat de toepassing de uitvoering stopt totdat de bewerking is voltooid. Dergelijke blokkerende applicaties zijn doorgaans intuïtiever te schrijven dan applicaties die async-bewust zijn.
Wanneer dure operaties de hoofdthread blokkeren, kunnen ze I/O blokkeren en is de jank zichtbaar voor gebruikers. Er is een discrepantie tussen een synchroon programmeermodel van native applicaties en het asynchrone model van het web. Dit is vooral problematisch voor oudere applicaties, die duur zouden zijn om over te zetten. Emscripten biedt een manier om dit te doen met Asyncify, maar dit is niet altijd de beste optie: grotere codegrootte en niet zo efficiënt.
In het volgende voorbeeld wordt fibonacci berekend, waarbij JavaScript-beloften voor optelling worden gebruikt.
long promiseFib(long x) {
if (x == 0)
return 0;
if (x == 1)
return 1;
return promiseAdd(promiseFib(x - 1), promiseFib(x - 2));
}
// promise an addition
EM_ASYNC_JS(long, promiseAdd, (long x, long y), {
return Promise.resolve(x+y);
});
emcc -O3 fib.c -o b.html -s ASYNCIFY=2
Let in dit voorbeeld op het volgende:
- De macro
EM_ASYNC_JSgenereert alle noodzakelijke lijmcode zodat we JSPI kunnen gebruiken om toegang te krijgen tot het resultaat van de belofte, net zoals dit zou gebeuren voor een normale functie. - De speciale opdrachtregeloptie
-s ASYNCIFY=2. Dit roept de optie op om code te genereren die JSPI gebruikt om te communiceren met JavaScript-imports die beloftes retourneren.
Voor meer informatie over JSPI, hoe u het kunt gebruiken en de voordelen ervan, leest u Introductie van de WebAssembly JavaScript Promise Integration API op v8.dev . Meer informatie over de huidige origin-proefperiode .
Geheugencontrole
Ontwikkelaars hebben zeer weinig controle over het Wasm-geheugen; de module bezit zijn eigen geheugen. Alle API's die toegang tot dit geheugen nodig hebben, moeten kopiëren of kopiëren, en dit gebruik kan behoorlijk oplopen. Een grafische toepassing moet bijvoorbeeld voor elk frame kopiëren en kopiëren.
Het voorstel voor geheugencontrole heeft tot doel een fijnere controle over het lineaire Wasm-geheugen te bieden en het aantal kopieën in de applicatiepijplijn te verminderen. Dit voorstel bevindt zich in fase 1. We maken er een prototype van in V8, de JavaScript-engine van Chrome, om de evolutie van de standaard te informeren.
Bepaal welke backend voor u geschikt is
Hoewel CPU alomtegenwoordig is, is dit niet altijd de beste optie. Compute voor speciale doeleinden op de GPU of versnellers kan prestaties bieden die ordes van grootte hoger zijn, vooral voor grotere modellen en op geavanceerde apparaten. Dit geldt voor zowel native applicaties als webapplicaties.
Welke backend u kiest, is afhankelijk van de applicatie, het framework of de toolchain, maar ook van andere factoren die de prestaties beïnvloeden. Dat gezegd hebbende, blijven we investeren in voorstellen die ervoor zorgen dat de kern van Wasm goed samenwerkt met de rest van het webplatform, en meer specifiek met WebGPU.