
Descubre cómo las mejoras de WebAssembly y WebGPU mejoran el rendimiento del aprendizaje automático en la Web.



Inferencia de IA en la Web
Todos hemos escuchado la historia: la IA está transformando nuestro mundo. La Web no es una excepción.
Este año, Chrome agregó funciones de IA generativa, como la creación de temas personalizados o ayudarte a escribir un primer borrador de texto. Pero la IA es mucho más que eso; puede enriquecer las aplicaciones web.
Las páginas web pueden incorporar componentes inteligentes para la visión, como detectar rostros o reconocer gestos, para la clasificación de audio o para la detección de idioma. En el último año, vimos el despegue de la IA generativa, incluidas algunas demostraciones realmente impresionantes de modelos de lenguaje extensos en la Web. Asegúrate de consultar IA integrada en el dispositivo práctica para desarrolladores web.
La inferencia de IA en la Web está disponible en la actualidad en una gran variedad de dispositivos, y el procesamiento de IA puede ocurrir en la página web en sí, aprovechando el hardware del dispositivo del usuario.
Esto es potente por varios motivos:
- Reducción de costos: Ejecutar la inferencia en el cliente del navegador reduce significativamente los costos del servidor, lo que puede ser especialmente útil para las consultas de IA generativa, que pueden ser órdenes de magnitud más costosas que las consultas normales.
- Latencia: En el caso de las aplicaciones que son particularmente sensibles a la latencia, como las aplicaciones de audio o video, si todo el procesamiento se realiza en el dispositivo, se reduce la latencia.
- Privacidad: El hecho de ejecutarse del lado del cliente también tiene el potencial de desbloquear una nueva clase de aplicaciones que requieren una mayor privacidad, en la que los datos no se pueden enviar al servidor.
Cómo se ejecutan las cargas de trabajo de IA en la Web en la actualidad
Actualmente, los desarrolladores y los investigadores de aplicaciones crean modelos con frameworks, que se ejecutan en el navegador con un entorno de ejecución como Tensorflow.js o ONNX Runtime Web, y los entornos de ejecución usan APIs web para la ejecución.
Todos esos tiempos de ejecución terminan ejecutándose en la CPU a través de JavaScript o WebAssembly, o en la GPU a través de WebGL o WebGPU.
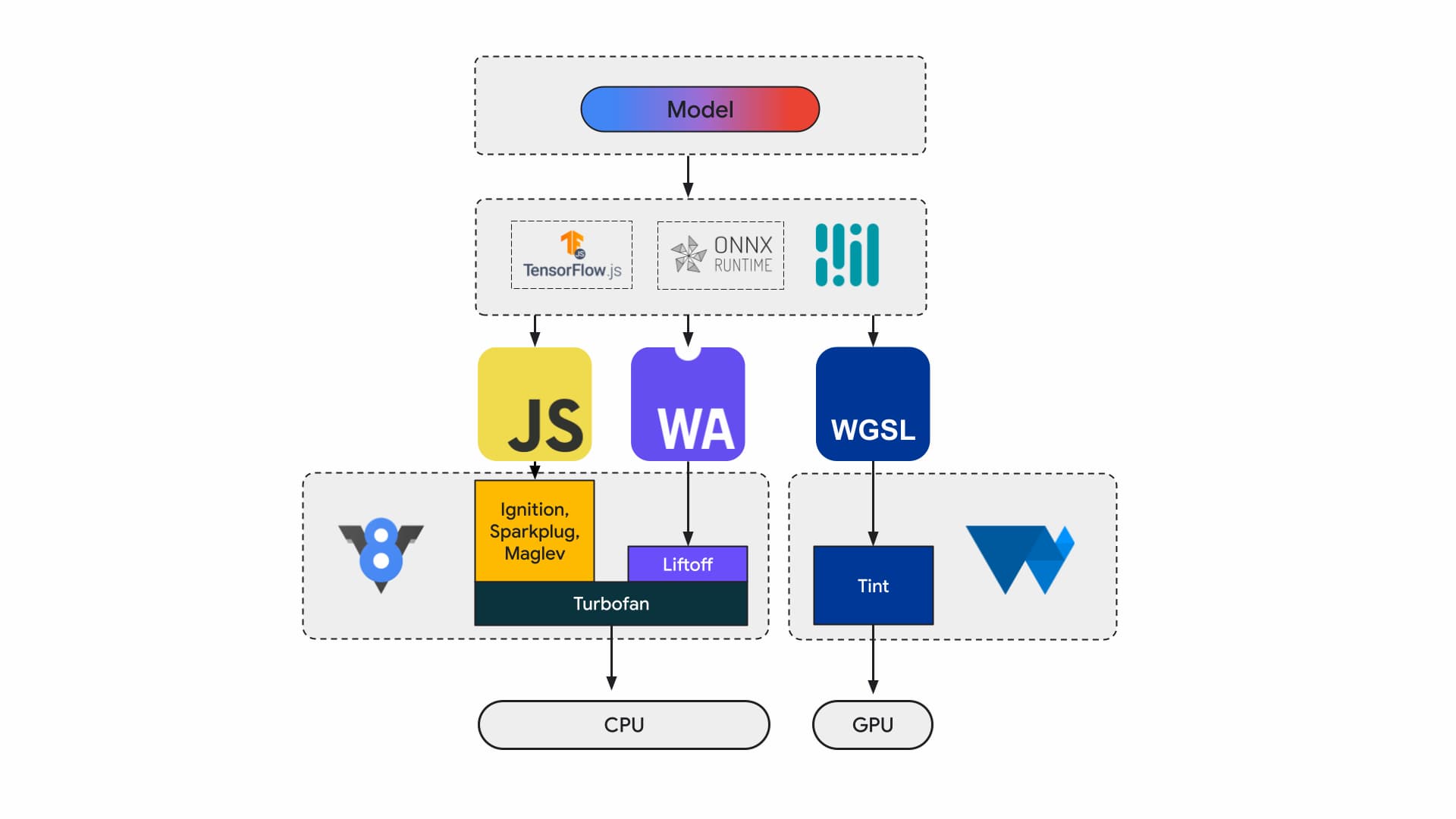
Cargas de trabajo de aprendizaje automático
Las cargas de trabajo de aprendizaje automático (AA) envían tensores a través de un gráfico de nodos computacionales. Los tensores son las entradas y salidas de estos nodos que realizan una gran cantidad de procesamiento en los datos.
Esto es importante por los siguientes motivos:
- Los tensores son estructuras de datos muy grandes que realizan cálculos en modelos que pueden tener miles de millones de pesos.
- La escalabilidad y la inferencia pueden generar paralelismo de datos. Esto significa que se realizan las mismas operaciones en todos los elementos de los tensores.
- El AA no requiere precisión. Es posible que necesites un número de punto flotante de 64 bits para llegar a la Luna, pero es posible que solo necesites un mar de números de 8 bits o menos para el reconocimiento facial.
Afortunadamente, los diseñadores de chips agregaron funciones para que los modelos funcionen más rápido, más fríos y, en algunos casos, incluso sea posible ejecutarlos.
Mientras tanto, en los equipos de WebAssembly y WebGPU, trabajamos para exponer esas nuevas funciones a los desarrolladores web. Si eres desarrollador de aplicaciones web, es poco probable que uses estas primitivas de bajo nivel con frecuencia. Esperamos que las cadenas de herramientas o los frameworks que usas admitan funciones y extensiones nuevas, de modo que puedas beneficiarte con cambios mínimos en tu infraestructura. Sin embargo, si te gusta ajustar manualmente tus aplicaciones para mejorar el rendimiento, estas funciones son relevantes para tu trabajo.
WebAssembly
WebAssembly (Wasm) es un formato de código de bytes compacto y eficiente que los entornos de ejecución pueden interpretar y ejecutar. Está diseñado para aprovechar las capacidades subyacentes del hardware, de modo que se pueda ejecutar a velocidades casi nativas. El código se valida y se ejecuta en un entorno de zona de pruebas seguro para la memoria.
La información del módulo Wasm se representa con una codificación binaria densa. En comparación con un formato basado en texto, esto significa una decodificación y carga más rápidas, y un uso reducido de la memoria. Es portátil en el sentido de que no hace suposiciones sobre la arquitectura subyacente que no sean comunes a las arquitecturas modernas.
La especificación de WebAssembly es iterativa y se trabaja en un grupo comunitario abierto del W3C.
El formato binario no hace suposiciones sobre el entorno del host, por lo que está diseñado para funcionar bien en incorporaciones que no sean web.
Tu aplicación se puede compilar una vez y ejecutar en cualquier lugar: una computadora de escritorio, una laptop, un teléfono o cualquier otro dispositivo con un navegador. Consulta Escribe una vez, ejecuta en cualquier lugar, finalmente, con WebAssembly para obtener más información sobre este tema.
La mayoría de las aplicaciones de producción que ejecutan inferencia de IA en la Web usan WebAssembly, tanto para el procesamiento de CPU como para la interconexión con el procesamiento de propósito especial. En las aplicaciones nativas, puedes acceder al procesamiento de uso general y de propósito especial, ya que la aplicación puede acceder a las capacidades del dispositivo.
En la Web, por motivos de portabilidad y seguridad, evaluamos cuidadosamente qué conjunto de primitivas se expone. Esto equilibra la accesibilidad de la Web con el máximo rendimiento que proporciona el hardware.
WebAssembly es una abstracción portátil de CPUs, por lo que toda la inferencia de Wasm se ejecuta en la CPU. Si bien no es la opción más eficiente, las CPUs están ampliamente disponibles y funcionan en la mayoría de las cargas de trabajo y en la mayoría de los dispositivos.
Para cargas de trabajo más pequeñas, como las de texto o audio, la GPU sería costosa. Existen varios ejemplos recientes en los que Wasm es la opción correcta:
- Adobe usa TensorFlow.js para mejorar Photoshop para la Web.
- Google Meet agregó el desenfoque del fondo, uno de los primeros efectos de video basados en Wasm en la Web.
- YouTube tiene varios efectos de realidad aumentada.
- Google Fotos permite la edición en línea.
Puedes descubrir aún más en las demostraciones de código abierto, como whisper-tiny, llama.cpp y Gemma2B que se ejecuta en el navegador.
Adopta un enfoque integral para tus aplicaciones
Debes elegir las primitivas en función del modelo de AA particular, la infraestructura de la aplicación y la experiencia general que se espera que tengan los usuarios.
Por ejemplo, en la detección de puntos de referencia de rostros de MediaPipe, la inferencia de la CPU y la inferencia de la GPU son comparables (se ejecutan en un dispositivo Apple M1), pero hay modelos en los que la variación podría ser significativamente mayor.
En el caso de las cargas de trabajo de AA, consideramos una vista integral de la aplicación y, al mismo tiempo, escuchamos a los autores de los frameworks y a los socios de aplicaciones para desarrollar y enviar las mejoras más solicitadas. En términos generales, se dividen en tres categorías:
- Exponer extensiones de CPU fundamentales para el rendimiento
- Habilita la ejecución de modelos más grandes
- Habilita la interoperabilidad perfecta con otras APIs web
Procesamiento más rápido
En la actualidad, la especificación de WebAssembly solo incluye un conjunto determinado de instrucciones que exponemos a la Web. Sin embargo, el hardware sigue agregando instrucciones más nuevas que aumentan la brecha entre el rendimiento nativo y el de WebAssembly.
Recuerda que los modelos de AA no siempre requieren altos niveles de precisión. SIMD relajado es una propuesta que reduce algunos de los requisitos estrictos de no determinismo, lo que genera una generación de código más rápida para algunas operaciones vectoriales que son puntos críticos de rendimiento. Además, el SIMD relajado presenta nuevas instrucciones de producto punto y FMA que aceleran las cargas de trabajo existentes de 1.5 a 3 veces. Se lanzó en Chrome 114.
El formato de punto flotante de precisión media usa 16 bits para el FP16 IEEE en lugar de los 32 bits que se usan para los valores de precisión simple. En comparación con los valores de precisión simple, existen varias ventajas en el uso de valores de precisión media, requisitos de memoria reducidos, que permiten el entrenamiento y la implementación de redes neuronales más grandes, y un ancho de banda de memoria reducido. La precisión reducida acelera la transferencia de datos y las operaciones matemáticas.
Modelos más grandes
Los punteros a la memoria lineal de Wasm se representan como números enteros de 32 bits. Esto tiene dos consecuencias: los tamaños del montón se limitan a 4 GB (cuando las computadoras tienen mucha más RAM física que eso) y el código de la aplicación que se orienta a Wasm debe ser compatible con un tamaño de puntero de 32 bits (que).
Especialmente con modelos grandes como los que tenemos hoy, cargar estos modelos en WebAssembly puede ser restrictivo. La propuesta de Memory64 quita estas restricciones de la memoria lineal para que sea superior a 4 GB y coincida con el espacio de direcciones de las plataformas nativas.
Tenemos una implementación completa y funcional en Chrome, y se espera que se envíe más adelante este año. Por ahora, puedes ejecutar experimentos con la marca chrome://flags/#enable-experimental-webassembly-features y enviarnos comentarios.
Mejor interoperabilidad web
WebAssembly podría ser el punto de entrada para el procesamiento de propósito especial en la Web.
WebAssembly se puede usar para llevar aplicaciones de GPU a la Web. Esto significa que la misma aplicación de C++ que se puede ejecutar en el dispositivo también se puede ejecutar en la Web, con pequeñas modificaciones.
Emscripten, la cadena de herramientas del compilador Wasm, ya tiene vinculaciones para WebGPU. Es el punto de entrada para la inferencia de IA en la Web, por lo que es fundamental que Wasm pueda interoperar sin problemas con el resto de la plataforma web. Estamos trabajando en un par de propuestas diferentes en este espacio.
Integración de promesas de JavaScript (JSPI)
Por lo general, las aplicaciones típicas de C y C++ (así como de muchos otros lenguajes) se escriben en una API síncrona. Esto significa que la aplicación detendría la ejecución hasta que se complete la operación. Por lo general, estas aplicaciones de bloqueo son más intuitivas de escribir que las aplicaciones que admiten operaciones asíncronas.
Cuando las operaciones costosas bloquean el subproceso principal, pueden bloquear la E/S, y los usuarios pueden ver el bloqueo. Hay una discrepancia entre un modelo de programación síncrona de aplicaciones nativas y el modelo asíncrono de la Web. Esto es especialmente problemático para las aplicaciones heredadas, cuyo portabilidad sería costosa. Emscripten proporciona una forma de hacerlo con Asyncify, pero esta no siempre es la mejor opción, ya que el tamaño del código es mayor y no es tan eficiente.
En el siguiente ejemplo, se calcula Fibonacci con promesas de JavaScript para la adición.
long promiseFib(long x) {
if (x == 0)
return 0;
if (x == 1)
return 1;
return promiseAdd(promiseFib(x - 1), promiseFib(x - 2));
}
// promise an addition
EM_ASYNC_JS(long, promiseAdd, (long x, long y), {
return Promise.resolve(x+y);
});
emcc -O3 fib.c -o b.html -s ASYNCIFY=2
En este ejemplo, presta atención a lo siguiente:
- La macro
EM_ASYNC_JSgenera todo el código de unión necesario para que podamos usar JSPI para acceder al resultado de la promesa, como lo haría para una función normal. - La opción de línea de comandos especial,
-s ASYNCIFY=2. Esto invoca la opción para generar código que usa JSPI para interactuar con importaciones de JavaScript que devuelven promesas.
Para obtener más información sobre JSPI, cómo usarlo y sus beneficios, consulta Presentamos la API de integración de promesas de JavaScript de WebAssembly en v8.dev. Obtén información sobre la prueba de origen actual.
Control de memoria
Los desarrolladores tienen muy poco control sobre la memoria de Wasm; el módulo es propietario de su propia memoria. Cualquier API que necesite acceder a esta memoria debe copiar o copiar, y este uso puede aumentar. Por ejemplo, es posible que una aplicación de gráficos deba copiar y copiar para cada fotograma.
El objetivo de la propuesta de control de memoria es proporcionar un control más detallado sobre la memoria lineal de Wasm y reducir la cantidad de copias en la canalización de la aplicación. Esta propuesta se encuentra en la Fase 1. Estamos creando prototipos en V8, el motor de JavaScript de Chrome, para informar la evolución del estándar.
Decide qué backend es el adecuado para ti
Si bien la CPU es omnipresente, no siempre es la mejor opción. El procesamiento de propósito especial en la GPU o los aceleradores puede ofrecer un rendimiento de órdenes de magnitud más alto, en especial para modelos más grandes y en dispositivos de alta gama. Esto es cierto tanto para las aplicaciones nativas como para las web.
El backend que elijas depende de la aplicación, el framework o la cadena de herramientas, así como de otros factores que influyen en el rendimiento. Dicho esto, seguimos invirtiendo en propuestas que permitan que Wasm principal funcione bien con el resto de la plataforma web y, más específicamente, con WebGPU.