
Dowiedz się, jak ulepszenia WebAssembly i WebGPU zwiększają wydajność systemów uczących się w internecie.



Przetwarzanie danych za pomocą AI w internecie
Wszyscy słyszeliśmy, że sztuczna inteligencja zmienia nasz świat. Internet nie jest wyjątkiem.
W tym roku dodaliśmy do Chrome funkcje generatywnej AI, w tym tworzenie niestandardowych motywów i pomoc w pisaniu pierwszej wersji tekstu. Ale AI to znacznie więcej. Może ona wzbogacać same aplikacje internetowe.
Strony internetowe mogą zawierać elementy inteligentne do obsługi widzenia, takie jak rozpoznawanie twarzy czy gestów, do klasyfikacji dźwięku lub wykrywania języka. W ostatnim roku odnotowaliśmy rozwój generatywnej AI, w tym naprawdę imponujące prezentacje dużych modeli językowych w internecie. Zapoznaj się ze szkoleniem Praktyczne zastosowania AI na urządzeniu dla programistów stron internetowych.
Wnioskowanie AI w internecie jest obecnie dostępne na wielu urządzeniach, a przetwarzanie AI może odbywać się na stronie internetowej, wykorzystując sprzęt na urządzeniu użytkownika.
Jest to skuteczne z kilku powodów:
- Zmniejszenie kosztów: wykonywanie wnioskowania na kliencie przeglądarki znacznie zmniejsza koszty serwera. Może to być szczególnie przydatne w przypadku zapytań do generatywnej AI, które mogą być wielokrotnie droższe niż zwykłe zapytania.
- Czas oczekiwania: w przypadku aplikacji, które są szczególnie wrażliwe na opóźnienia, takich jak aplikacje do obsługi dźwięku lub wideo, przetwarzanie wszystkich danych na urządzeniu pozwala skrócić czas oczekiwania.
- Prywatność: uruchamianie na kliencie może też prowadzić do uruchomienia nowej klasy aplikacji, które wymagają zwiększonej ochrony prywatności, gdzie dane nie mogą być wysyłane na serwer.
Jak obecnie działają zadania AI w internecie
Obecnie deweloperzy aplikacji i badacze tworzą modele za pomocą frameworków, a modele są wykonywane w przeglądarce przy użyciu środowiska wykonawczego, takiego jak Tensorflow.js lub ONNX Runtime Web. Środowiska wykonawcze korzystają z interfejsów API sieci Web do wykonywania.
Wszystkie te środowisko uruchomieniowe ostatecznie uruchamiają się na procesorze za pomocą JavaScript lub WebAssembly albo na procesorze graficznym za pomocą WebGL lub WebGPU.
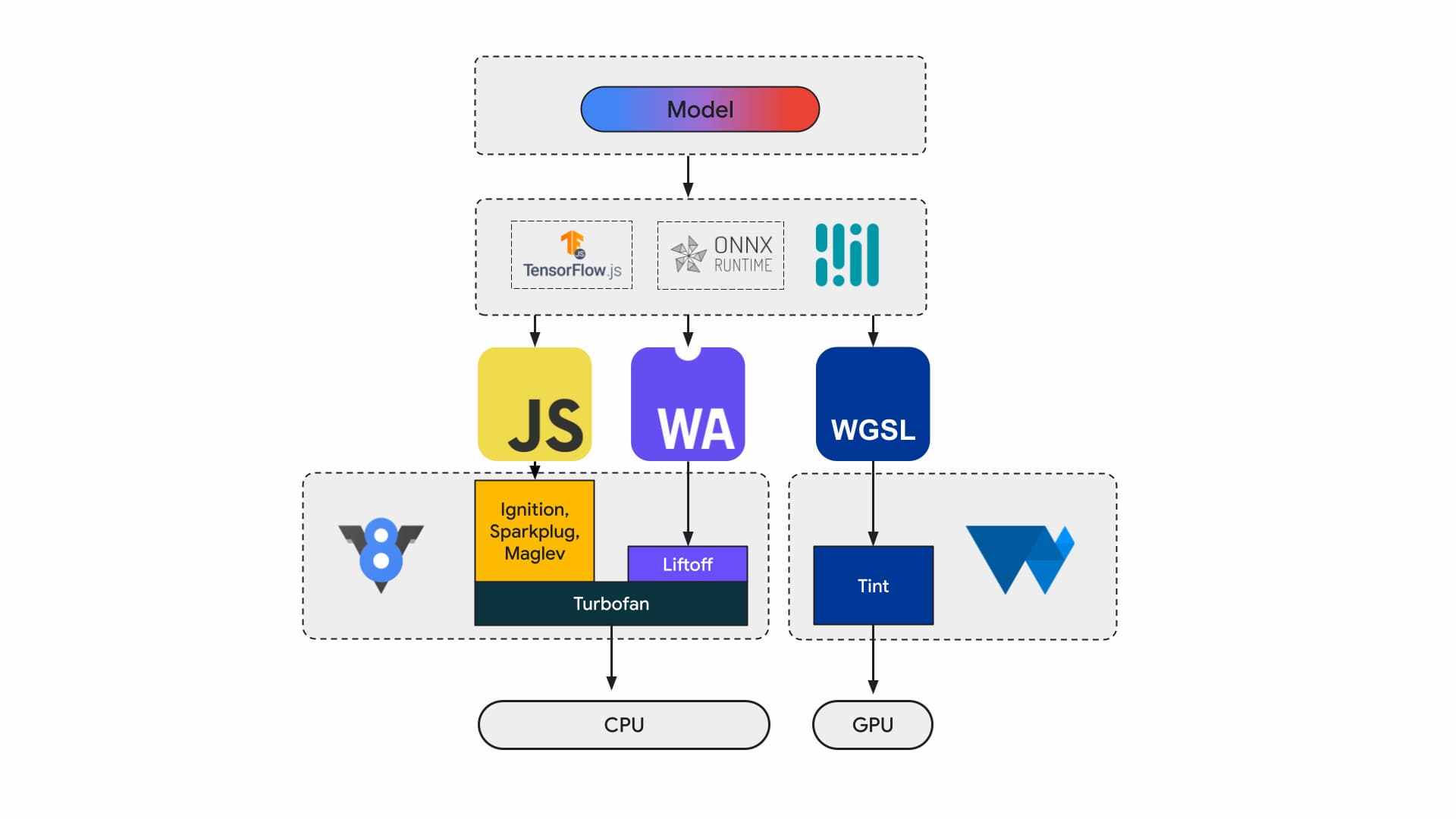
zadania związane z systemami uczącymi się,
Zadania uczenia maszynowego przesyłają tensory przez graf węzłów obliczeniowych. Tensory to dane wejściowe i wyjściowe tych węzłów, które wykonują dużą ilość obliczeń na danych.
Jest to ważne, ponieważ:
- Tensory to bardzo duże struktury danych, które wykonują obliczenia na modelach mogących mieć miliardy wag.
- Skalowanie i wywnioskowanie mogą prowadzić do równoległości danych. Oznacza to, że na wszystkich elementach tensora wykonywane są te same operacje.
- Sztuczne uczenie nie wymaga precyzji. Aby wylądować na Księżycu, może być potrzebna 64-bitowa liczba zmiennoprzecinkową, ale do rozpoznawania twarzy wystarczy 8-bitowa liczba.
Na szczęście projektanci układów dodali funkcje, które sprawiają, że modele działają szybciej, chłodniej i w ogóle mogą działać.
Tymczasem my, członkowie zespołów WebAssembly i WebGPU, pracujemy nad udostępnieniem tych nowych funkcji programistom. Jeśli jesteś deweloperem aplikacji internetowych, prawdopodobnie nie będziesz często używać tych prymitywów niskiego poziomu. Oczekujemy, że używane przez Ciebie zestawy narzędzi lub frameworki będą obsługiwać nowe funkcje i rozszerzenia, dzięki czemu będziesz mieć możliwość wprowadzenia minimalnych zmian w swojej infrastrukturze. Jeśli jednak wolisz ręcznie dostosowywać wydajność aplikacji, te funkcje mogą Ci się przydać.
WebAssembly
WebAssembly (Wasm) to zwarty, wydajny format kodu bajtowego, który środowisko uruchomieniowe może interpretować i wykonywać. Jest ona zaprojektowana tak, aby korzystać z podstawowych możliwości sprzętowych, dzięki czemu może działać z prędkością zbliżoną do natywnej. Kod jest weryfikowany i wykonuje się w bezpiecznym środowisku piaskownicy.
Informacje o module Wasm są reprezentowane za pomocą gęstego kodowania binarnego. W porównaniu z formatem tekstowym oznacza to szybsze dekodowanie, szybsze wczytywanie i mniejsze zużycie pamięci. Jest przenośna w tym sensie, że nie zakłada niczego na temat architektury docelowej, co nie jest już powszechne w przypadku nowoczesnych architektur.
Specyfikacja WebAssembly jest iteracyjna i jest opracowywana w otwartej grupie społeczności W3C.
Format binarny nie zakłada niczego na temat środowiska hosta, więc został zaprojektowany tak, aby działać także w przypadku elementów osadzonych poza internetem.
Aplikację można skompilować raz i uruchamiać wszędzie: na komputerze, laptopie, telefonie lub innym urządzeniu z przeglądarką. Aby dowiedzieć się więcej, przeczytaj artykuł Write once, run anywhere finally realized with WebAssembly (ang. „Write once, run anywhere finally realized with WebAssembly”).
Większość aplikacji produkcyjnych, które korzystają z inferencji AI w internecie, używa WebAssembly zarówno do obliczeń na procesorze, jak i do interfejsu z procesorem do zastosowań specjalnych. W przypadku aplikacji natywnych możesz korzystać z przetwarzania ogólnego i specjalnego, ponieważ aplikacja może korzystać z funkcji urządzenia.
W internecie, ze względu na przenośność i bezpieczeństwo, starannie analizujemy, jakie zestawy prymitywów są udostępniane. Dzięki temu można zachować równowagę między dostępnością stron internetowych a maksymalną wydajnością sprzętu.
WebAssembly to przenośna abstrakcja procesorów, więc wszystkie wnioskowania Wasm są wykonywane na procesorze. Chociaż nie jest to rozwiązanie o najwyższej wydajności, procesory są powszechnie dostępne i działają na większości urządzeń w przypadku większości zadań.
W przypadku mniejszych obciążeń, takich jak obciążenia tekstowe lub audio, korzystanie z GPU jest drogie. Oto kilka przykładów, w których Wasm jest odpowiednim rozwiązaniem:
- Adobe używa Tensorflow.js do ulepszania Photoshopa na potrzeby internetu.
- Google Meet dodało rozmycie tła, jeden z pierwszych efektów wideo opartych na Wasm w internecie.
- YouTube oferuje kilka efektów rzeczywistości rozszerzonej.
- Zdjęcia Google umożliwiają edycję online.
Jeszcze więcej możliwości znajdziesz w wersjach demonstracyjnych open source, takich jak whisper-tiny, llama.cpp i Gemma2B działająca w przeglądarce.
Podejście holistyczne do aplikacji
Wybierz prymitywy na podstawie konkretnego modelu ML, infrastruktury aplikacji i ogólnego zamierzonego działania aplikacji dla użytkowników.
Na przykład w funkcja wykrywania punktów orientacyjnych twarzy w MediaPipe wnioskowanie na procesorze i na GPU jest porównywalne (na urządzeniu z procesorem Apple M1), ale w przypadku niektórych modeli różnice mogą być znacznie większe.
W przypadku zadań związanych z ML bierzemy pod uwagę całościowy widok aplikacji, a także opinie autorów frameworków i partnerów aplikacji, aby opracowywać i wdrażać najbardziej oczekiwane ulepszenia. Można je podzielić na 3 kategorie:
- Wyświetl rozszerzenia procesora, które mają kluczowe znaczenie dla wydajności
- Włączanie większych modeli
- Umożliwianie płynnej współpracy z innymi interfejsami API w internecie
Szybsze przetwarzanie
W obecnej specyfikacji WebAssembly uwzględniono tylko pewien zestaw instrukcji, które udostępniamy w internecie. Jednak sprzęt nadal obsługuje nowsze instrukcje, które pogłębiają różnicę między wydajnością natywnych i WebAssembly.
Pamiętaj, że modele ML nie zawsze wymagają wysokiego poziomu dokładności. Zrelaksowany SIMD to propozycja, która ogranicza niektóre rygorystyczne wymagania dotyczące niedeterminizmu, co prowadzi do szybszego generowania kodu dla niektórych operacji wektorowych, które są newralgicznymi punktami pod względem wydajności. Ponadto Relaxed SIMD wprowadza nowe instrukcje dot product i FMA, które przyspieszają istniejące obciążenia robocze 1,5–3 razy. Ta funkcja została wprowadzona w Chrome 114.
Format zmiennoprzecinkowy o połówkowej precyzji używa 16-bitów dla IEEE FP16 zamiast 32-bitów używanych dla wartości o pojedynczej precyzji. W porównaniu z wartościami o pojedynczej precyzji, wartości o połowach precyzji mają kilka zalet, m.in. zmniejszone wymagania dotyczące pamięci, co umożliwia trenowanie i wdrażanie większych sieci neuronowych oraz zmniejszenie przepustowości pamięci. Zmniejszenie dokładności przyspiesza przesyłanie danych i operacje matematyczne.
Większe modele
Wskaźniki do liniowej pamięci Wasm są reprezentowane jako 32-bitowe liczby całkowite. Ma to 2 konsekwencje: rozmiary stosu są ograniczone do 4 GB (podczas gdy komputery mają znacznie więcej fizycznej pamięci RAM), a kod aplikacji przeznaczony dla Wasm musi być zgodny z rozmiarem wskaźnika 32-bitowego (który
Ładowanie takich modeli do WebAssembly może być ograniczone, zwłaszcza w przypadku dużych modeli. Propozycja Memory64 usuwa te ograniczenia, ponieważ pamięć liniowa jest większa niż 4 GB i pasuje do przestrzeni adresowej platform natywnych.
W Chrome mamy już wdrożenie, które działa w pełni. Przewidujemy, że zostanie ono udostępnione jeszcze w tym roku. Obecnie możesz przeprowadzać eksperymenty z flagą chrome://flags/#enable-experimental-webassembly-features i przesyłać nam opinie.
Lepsza interoperacyjność w internecie
WebAssembly może być punktem wejścia do obliczeń o specjalnym przeznaczeniu w internecie.
Standardu WebAssembly można używać do tworzenia aplikacji GPU na potrzeby internetu. Oznacza to, że ta sama aplikacja w C++, która może działać na urządzeniu, może też działać w internecie (z niewielkimi modyfikacjami).
Narzędzie Emscripten, czyli zestaw narzędzi kompilatora Wasm, zawiera już linki do WebGPU. Jest to punkt wejścia do wnioskowania AI w internecie, dlatego ważne jest, aby usługa ta mogła płynnie współpracować z resztą platformy internetowej. Pracujemy nad kilkoma propozycjami w tej dziedzinie.
Integracja obietnic JavaScript (JSPI)
Typowe aplikacje w językach C i C++ (oraz w wielu innych językach) są zwykle tworzone z użyciem synchronicznego interfejsu API. Oznacza to, że aplikacja przestanie się wykonywać do czasu zakończenia operacji. Takie aplikacje blokujące są zazwyczaj łatwiejsze do napisania niż aplikacje obsługujące asynchroniczność.
Gdy kosztowne operacje blokują wątek główny, mogą blokować operacje wejścia-wyjścia, co powoduje widoczne dla użytkowników zakłócenia. Występuje niezgodność między modelem programowania synchronicznego aplikacji natywnych a modelem asynchronicznym w internecie. Jest to szczególnie problematyczne w przypadku starszych aplikacji, których przeportowanie byłoby kosztowne. Emscripten umożliwia to za pomocą Asyncify, ale nie zawsze jest to najlepsza opcja, ponieważ kod jest wtedy większy i nie tak wydajny.
W tym przykładzie obliczamy liczby Fibonacciego, używając obietnic JavaScript do dodawania.
long promiseFib(long x) {
if (x == 0)
return 0;
if (x == 1)
return 1;
return promiseAdd(promiseFib(x - 1), promiseFib(x - 2));
}
// promise an addition
EM_ASYNC_JS(long, promiseAdd, (long x, long y), {
return Promise.resolve(x+y);
});
emcc -O3 fib.c -o b.html -s ASYNCIFY=2
W tym przykładzie zwróć uwagę na te kwestie:
- Makro
EM_ASYNC_JSgeneruje cały niezbędny kod łączący, dzięki czemu możemy użyć JSPI do uzyskania dostępu do wyniku obietnicy, tak jak w przypadku zwykłej funkcji. - Specjalna opcja wiersza poleceń,
-s ASYNCIFY=2. Wywoła to opcję generowania kodu, który używa JSPI do interfejsu z importami JavaScript zwracającymi obietnice.
Więcej informacji o interfejsie JSPI, o tym, jak go używać, i o jego zaletach znajdziesz w artykule [v8.dev] Wprowadzenie interfejsu WebAssembly JavaScript Promise Integration API. Dowiedz się więcej o obecnych testach wersji źródłowej.
Zarządzanie pamięcią
Deweloperzy mają bardzo ograniczoną kontrolę nad pamięcią Wasm, ponieważ moduł ma własną pamięć. Wszystkie interfejsy API, które muszą mieć dostęp do tej pamięci, muszą skopiować dane do niej lub z niej, a takie operacje mogą prowadzić do znacznego wzrostu wykorzystania pamięci. Na przykład aplikacja graficzna może potrzebować kopii danych z każdej klatki.
Propozycja Kontrola pamięci ma na celu zapewnienie bardziej szczegółowej kontroli nad liniową pamięcią w Twojej aplikacji oraz zmniejszenie liczby kopii w przepływie danych aplikacji. Ta propozycja jest na etapie 1. Tworzymy prototyp w V8, czyli mechanizmie JavaScriptu w Chrome, aby umożliwić ewolucję standardu.
Wybór odpowiedniego backendu
Procesor jest wszechobecny, ale nie zawsze jest najlepszym rozwiązaniem. Obliczenia specjalne na procesorze graficznym lub akceleratorach mogą zapewniać wydajność wyższą o wiele rzędów wielkości, zwłaszcza w przypadku większych modeli i urządzeń wysokiej klasy. Dotyczy to zarówno natywnych aplikacji, jak i aplikacji internetowych.
Wybór backendu zależy od aplikacji, frameworku lub zestawu narzędzi, a także innych czynników wpływających na wydajność. Nadal jednak inwestujemy w rozwiązania, które umożliwiają prawidłowe działanie podstawowego Wasm w połączeniu z resztą platformy internetowej, a w szczególności z WebGPU.