
WebAssembly 및 WebGPU 개선사항이 웹에서 머신러닝 성능을 개선하는 방법을 알아보세요.



웹에서의 AI 추론
AI가 세상을 변화시키고 있다는 이야기는 누구나 한 번쯤 들어봤을 것입니다. 웹도 예외는 아닙니다.
올해 Chrome에는 맞춤 테마 만들기, 텍스트 초안 작성 지원 등 생성형 AI 기능이 추가되었습니다. 하지만 AI는 그 이상입니다. AI는 웹 애플리케이션 자체를 보강할 수 있습니다.
웹페이지는 얼굴을 선택하거나 동작을 인식하는 것과 같은 시각, 오디오 분류 또는 언어 감지를 위한 지능형 구성요소를 삽입할 수 있습니다. 작년에는 웹에서 대규모 언어 모델을 보여주는 인상적인 데모를 비롯해 생성형 AI가 급성장했습니다. 웹 개발자를 위한 실용적인 기기 내 AI를 확인하세요.
현재 웹에서의 AI 추론은 많은 기기에서 사용할 수 있으며, 사용자 기기의 하드웨어를 활용하여 웹페이지 자체에서 AI 처리가 이루어질 수 있습니다.
이는 다음과 같은 이유로 강력합니다.
- 비용 절감: 브라우저 클라이언트에서 추론을 실행하면 서버 비용이 크게 절감됩니다. 이는 일반 쿼리보다 비용이 훨씬 더 많이 들 수 있는 생성형 AI 쿼리에 특히 유용합니다.
- 지연 시간: 오디오 또는 동영상 애플리케이션과 같이 지연 시간에 특히 민감한 애플리케이션의 경우 모든 처리가 기기에서 이루어지면 지연 시간이 줄어듭니다.
- 개인 정보 보호: 클라이언트 측에서 실행하면 데이터를 서버로 전송할 수 없는 강화된 개인 정보 보호가 필요한 새로운 클래스의 애플리케이션을 잠금 해제할 수도 있습니다.
오늘날 웹에서 AI 워크로드가 실행되는 방식
현재 애플리케이션 개발자와 연구원은 프레임워크를 사용하여 모델을 빌드하고, 모델은 Tensorflow.js 또는 ONNX Runtime Web과 같은 런타임을 사용하여 브라우저에서 실행되며, 런타임은 실행을 위해 Web API를 사용합니다.
이러한 모든 런타임은 결국 JavaScript 또는 WebAssembly를 통해 CPU에서 실행되거나 WebGL 또는 WebGPU를 통해 GPU에서 실행됩니다.
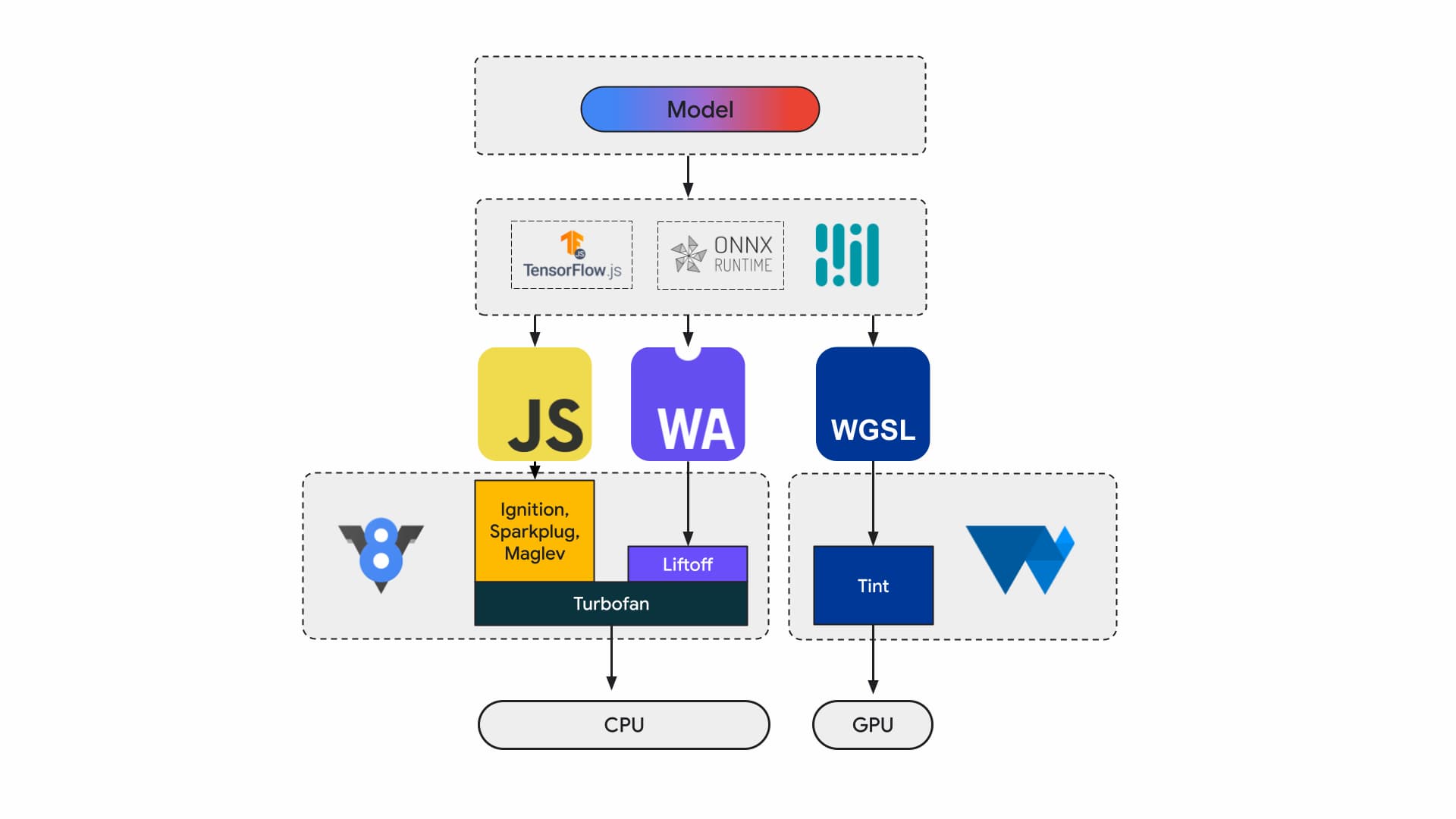
머신러닝 워크로드
머신러닝 (ML) 워크로드는 계산 노드의 그래프를 통해 텐서를 푸시합니다. 텐서는 데이터에 대해 대량의 계산을 실행하는 이러한 노드의 입력과 출력입니다.
이는 다음과 같은 이유로 중요합니다.
- 텐서는 수십억 개의 가중치가 있을 수 있는 모델에서 계산을 실행하는 매우 큰 데이터 구조입니다.
- 확장 및 추론으로 인해 데이터 병렬 처리가 발생할 수 있습니다. 즉, 텐서의 모든 요소에 동일한 작업이 실행됩니다.
- ML은 정밀도가 필요하지 않습니다. 달에 착륙하려면 64비트 부동 소수점 수가 필요할 수 있지만 얼굴 인식에는 8비트 이하의 숫자만 있으면 충분할 수 있습니다.
다행히 칩 설계자는 모델을 더 빠르고 시원하게 실행하고 아예 실행할 수 있도록 하는 기능을 추가했습니다.
WebAssembly 및 WebGPU팀에서는 이러한 새로운 기능을 웹 개발자에게 제공하기 위해 노력하고 있습니다. 웹 애플리케이션 개발자는 이러한 하위 수준 프리미티브를 자주 사용하지 않을 것입니다. 사용 중인 도구 모음 또는 프레임워크에서 새로운 기능과 확장 프로그램을 지원할 것으로 예상되므로 인프라를 최소한만 변경해도 이점을 누릴 수 있습니다. 하지만 성능을 위해 애플리케이션을 수동으로 조정하려는 경우 이러한 기능이 작업과 관련이 있습니다.
WebAssembly
WebAssembly (Wasm)는 런타임에서 이해하고 실행할 수 있는 간결하고 효율적인 바이트 코드 형식입니다. 기본 하드웨어 기능을 활용하도록 설계되어 거의 네이티브 속도로 실행할 수 있습니다. 코드는 메모리 안전 샌드박스 환경에서 유효성 검사를 거치고 실행됩니다.
Wasm 모듈 정보는 밀집된 바이너리 인코딩으로 표현됩니다. 텍스트 기반 형식과 비교하면 디코딩 속도가 빨라지고 로드 속도가 빨라지며 메모리 사용량이 줄어듭니다. 최신 아키텍처에 아직 공통되지 않은 기본 아키텍처에 관해 가정하지 않는다는 점에서 이식성이 있습니다.
WebAssembly 사양은 반복적이며 공개 W3C 커뮤니티 그룹에서 작업됩니다.
바이너리 형식은 호스트 환경에 관해 가정하지 않으므로 웹 외 삽입에도 잘 작동하도록 설계되었습니다.
애플리케이션을 한 번 컴파일하면 데스크톱, 노트북, 휴대전화, 브라우저가 있는 기타 모든 기기에서 실행할 수 있습니다. Write once, run anywhere finally realized with WebAssembly를 확인하여 자세히 알아보세요.
웹에서 AI 추론을 실행하는 대부분의 프로덕션 애플리케이션은 CPU 컴퓨팅과 특수 목적 컴퓨팅과의 인터페이스 모두에 WebAssembly를 사용합니다. 네이티브 애플리케이션에서는 애플리케이션이 기기 기능에 액세스할 수 있으므로 범용 컴퓨팅과 특수 목적 컴퓨팅에 모두 액세스할 수 있습니다.
웹에서는 휴대성과 보안을 위해 노출되는 프리미티브 집합을 신중하게 평가합니다. 이렇게 하면 웹의 접근성과 하드웨어에서 제공하는 최대 성능의 균형을 유지할 수 있습니다.
WebAssembly는 CPU의 휴대용 추상화이므로 모든 Wasm 추론은 CPU에서 실행됩니다. CPU는 성능이 가장 뛰어난 선택은 아니지만 널리 사용 가능하며 대부분의 기기에서 대부분의 워크로드에서 작동합니다.
텍스트 또는 오디오 워크로드와 같은 소규모 워크로드의 경우 GPU가 비쌉니다. Wasm이 적합한 선택인 최근의 사례가 많이 있습니다.
- Adobe는 TensorFlow.js를 사용하여 웹용 Photoshop을 개선합니다.
- 웹에서 최초로 Wasm 기반 동영상 효과 중 하나인 Google Meet의 배경 흐리게 처리가 추가되었습니다.
- YouTube에는 여러 증강 현실 효과가 있습니다.
- Google 포토에서는 온라인으로 수정할 수 있습니다.
whisper-tiny, llama.cpp, 브라우저에서 실행되는 Gemma2B와 같은 오픈소스 데모에서 더 많은 것을 확인할 수 있습니다.
애플리케이션에 대한 전체적인 접근 방식
특정 ML 모델, 애플리케이션 인프라, 사용자를 위한 전반적인 의도된 애플리케이션 환경을 기반으로 프리미티브를 선택해야 합니다.
예를 들어 MediaPipe의 얼굴 지형지물 감지에서 CPU 추론과 GPU 추론은 비슷하지만 (Apple M1 기기에서 실행) 차이가 훨씬 더 클 수 있는 모델도 있습니다.
ML 워크로드의 경우 Google은 프레임워크 작성자와 애플리케이션 파트너의 의견을 수렴하면서 전체적인 애플리케이션 관점을 고려하여 가장 요청이 많은 개선사항을 개발하고 출시합니다. 이러한 문제는 크게 세 가지 카테고리로 나뉩니다.
- 성능에 중요한 CPU 확장 노출
- 더 큰 모델 실행 사용 설정
- 다른 웹 API와의 원활한 상호 운용성 사용 설정
더 빠른 컴퓨팅
현재 WebAssembly 사양에는 웹에 노출되는 특정 명령 집합만 포함되어 있습니다. 하지만 하드웨어는 계속해서 최신 명령어를 추가하여 네이티브와 WebAssembly 성능 간의 격차를 벌리고 있습니다.
ML 모델에 항상 높은 수준의 정확도가 필요한 것은 아닙니다. 완화된 SIMD는 일부 엄격한 비결정론 요구사항을 줄여 성능의 핫스팟인 일부 벡터 연산의 코드 생성을 더 빠르게 하는 제안입니다. 또한 완화된 SIMD는 기존 워크로드의 속도를 1.5~3배 가속화하는 새로운 내적 및 FMA 명령을 도입합니다. 이 기능은 Chrome 114에서 출시되었습니다.
반정밀도 부동 소수점 형식은 단일 정밀도 값에 사용되는 32비트 대신 IEEE FP16에 16비트를 사용합니다. 단정밀도 값에 비해 절반 정밀도 값을 사용하면 메모리 요구사항이 줄어 더 큰 신경망의 학습 및 배포가 가능해지고 메모리 대역폭이 줄어드는 등 여러 이점이 있습니다. 정밀도를 낮추면 데이터 전송 및 수학 연산 속도가 빨라집니다.
대형 모델
Wasm 선형 메모리의 포인터는 32비트 정수로 표시됩니다. 이로 인해 두 가지 결과가 발생합니다. 힙 크기가 4GB로 제한되고(컴퓨터의 실제 RAM이 이보다 훨씬 더 많은 경우) Wasm을 타겟팅하는 애플리케이션 코드가 32비트 포인터 크기와 호환되어야 합니다.
특히 오늘날과 같은 대규모 모델의 경우 이러한 모델을 WebAssembly로 로드하는 것이 제한적일 수 있습니다. Memory64 제안서에서는 선형 메모리가 4GB보다 크고 네이티브 플랫폼의 주소 공간과 일치하도록 하여 이러한 제한을 삭제합니다.
Chrome에서 완전히 작동하는 구현이 있으며 올해 안에 출시될 예정입니다. 지금은 chrome://flags/#enable-experimental-webassembly-features 플래그를 사용하여 실험을 실행하고 의견을 보낼 수 있습니다.
향상된 웹 상호 운용성
WebAssembly는 웹에서 특수 목적 컴퓨팅의 진입점이 될 수 있습니다.
WebAssembly를 사용하여 GPU 애플리케이션을 웹으로 가져올 수 있습니다. 즉, 기기에서 실행할 수 있는 동일한 C++ 애플리케이션을 약간 수정하여 웹에서도 실행할 수 있습니다.
Wasm 컴파일러 도구 모음인 Emscripten에는 이미 WebGPU용 바인딩이 있습니다. 웹에서 AI 추론의 진입점으로, Wasm이 나머지 웹 플랫폼과 원활하게 상호 운용될 수 있어야 합니다. YouTube는 이 분야에서 몇 가지 제안을 준비하고 있습니다.
JavaScript Promise 통합 (JSPI)
일반적인 C 및 C++ 애플리케이션 (및 기타 여러 언어)은 일반적으로 동기식 API에 맞게 작성됩니다. 즉, 작업이 완료될 때까지 애플리케이션의 실행이 중지됩니다. 이러한 차단 애플리케이션은 일반적으로 비동기식 인식 애플리케이션보다 더 직관적으로 작성할 수 있습니다.
비용이 많이 드는 작업이 기본 스레드를 차단하면 I/O가 차단될 수 있으며 사용자에게 버벅거림이 표시됩니다. 네이티브 애플리케이션의 동기 프로그래밍 모델과 웹의 비동기 모델 간에 불일치가 있습니다. 이는 포팅하는 데 비용이 많이 드는 기존 애플리케이션에 특히 문제가 됩니다. Emscripten은 Asyncify를 사용하여 이를 수행하는 방법을 제공하지만, 항상 최선의 옵션은 아닙니다. 코드 크기가 더 크고 효율적이지 않습니다.
다음 예에서는 덧셈에 JavaScript 약속을 사용하여 피보나치 수를 계산합니다.
long promiseFib(long x) {
if (x == 0)
return 0;
if (x == 1)
return 1;
return promiseAdd(promiseFib(x - 1), promiseFib(x - 2));
}
// promise an addition
EM_ASYNC_JS(long, promiseAdd, (long x, long y), {
return Promise.resolve(x+y);
});
emcc -O3 fib.c -o b.html -s ASYNCIFY=2
이 예시에서 다음 사항에 유의하세요.
EM_ASYNC_JS매크로는 JSPI를 사용하여 일반 함수에서와 마찬가지로 약속의 결과에 액세스할 수 있도록 필요한 모든 글루 코드를 생성합니다.- 특수 명령줄 옵션
-s ASYNCIFY=2이렇게 하면 JSPI를 사용하여 약속을 반환하는 JavaScript 가져오기와 상호작용하는 코드를 생성하는 옵션이 호출됩니다.
JSPI, 사용 방법, 이점에 관한 자세한 내용은 v8.dev에서 WebAssembly JavaScript Promise Integration API 소개를 참고하세요. 현재 출처 체험판에 관해 알아보세요.
메모리 제어
개발자는 Wasm 메모리를 거의 제어할 수 없습니다. 모듈이 자체 메모리를 소유합니다. 이 메모리에 액세스해야 하는 모든 API는 복사하거나 복사해야 하며 이러한 사용량은 상당히 누적될 수 있습니다. 예를 들어 그래픽 애플리케이션은 각 프레임에 대해 복사하고 복사해야 할 수 있습니다.
메모리 제어 제안서의 목표는 Wasm 선형 메모리를 더 세부적으로 제어하고 애플리케이션 파이프라인 전반에서 사본 수를 줄이는 것입니다. 이 제안은 1단계에 있으며, 표준의 발전을 알리기 위해 Chrome의 JavaScript 엔진인 V8에서 프로토타입을 제작하고 있습니다.
적합한 백엔드 결정
CPU는 어디에나 있지만 항상 최선의 선택은 아닙니다. GPU 또는 가속기의 특수 목적 컴퓨팅은 특히 대규모 모델과 고급 기기에서 훨씬 더 높은 성능을 제공할 수 있습니다. 이는 네이티브 애플리케이션과 웹 애플리케이션 모두에 적용됩니다.
선택하는 백엔드는 애플리케이션, 프레임워크 또는 도구 모음뿐만 아니라 성능에 영향을 미치는 기타 요인에 따라 달라집니다. 하지만 핵심 Wasm이 나머지 웹 플랫폼, 특히 WebGPU와 원활하게 작동할 수 있도록 하는 제안에 계속 투자하고 있습니다.