
WebAssembly と WebGPU の機能強化がウェブでの ML のパフォーマンスを向上させる仕組みについて学びます。



ウェブでの AI 推論
AI が世界を変革しているという話は、誰もが耳にしたことがあるでしょう。ウェブも例外ではありません。
今年、Chrome には生成 AI 機能が追加されました。これには、カスタム テーマの作成やテキストの下書きの作成を支援する機能が含まれます。しかし、AI はそれだけではありません。AI はウェブ アプリケーション自体を拡充することもできます。
ウェブページには、顔の検出やジェスチャーの認識、音声分類、言語検出などのビジョン用のインテリジェント コンポーネントを埋め込むことができます。昨年、生成 AI は急速に普及し、ウェブ上で大規模言語モデルの非常に印象的なデモがいくつか公開されました。ウェブ デベロッパー向けの実用的なオンデバイス AI もご覧ください。
ウェブでの AI 推論は、現在、多くのデバイスで利用できます。また、ユーザーのデバイスのハードウェアを活用して、ウェブページ自体で AI 処理を行うこともできます。
次のような理由から、これは強力な機能です。
- 費用の削減: ブラウザ クライアントで推論を実行すると、サーバー費用が大幅に削減されます。これは、通常のクエリよりも数桁高い費用がかかる可能性がある GenAI クエリに特に役立ちます。
- レイテンシ: レイテンシに特に敏感なアプリ(オーディオ アプリや動画アプリなど)では、すべての処理をデバイス上で行うことでレイテンシを短縮できます。
- プライバシー: クライアントサイドで実行することで、データがサーバーに送信されない、プライバシーの強化が必要な新しいクラスのアプリケーションを実現できる可能性があります。
現在のウェブで AI ワークロードがどのように実行されるか
現在、アプリケーション デベロッパーと研究者はフレームワークを使用してモデルを構築し、モデルは Tensorflow.js や ONNX Runtime Web などのランタイムを使用してブラウザで実行されます。ランタイムは、実行に Web API を使用します。
これらのランタイムは最終的に、JavaScript または WebAssembly を介して CPU で実行されるか、WebGL または WebGPU を介して GPU で実行されます。
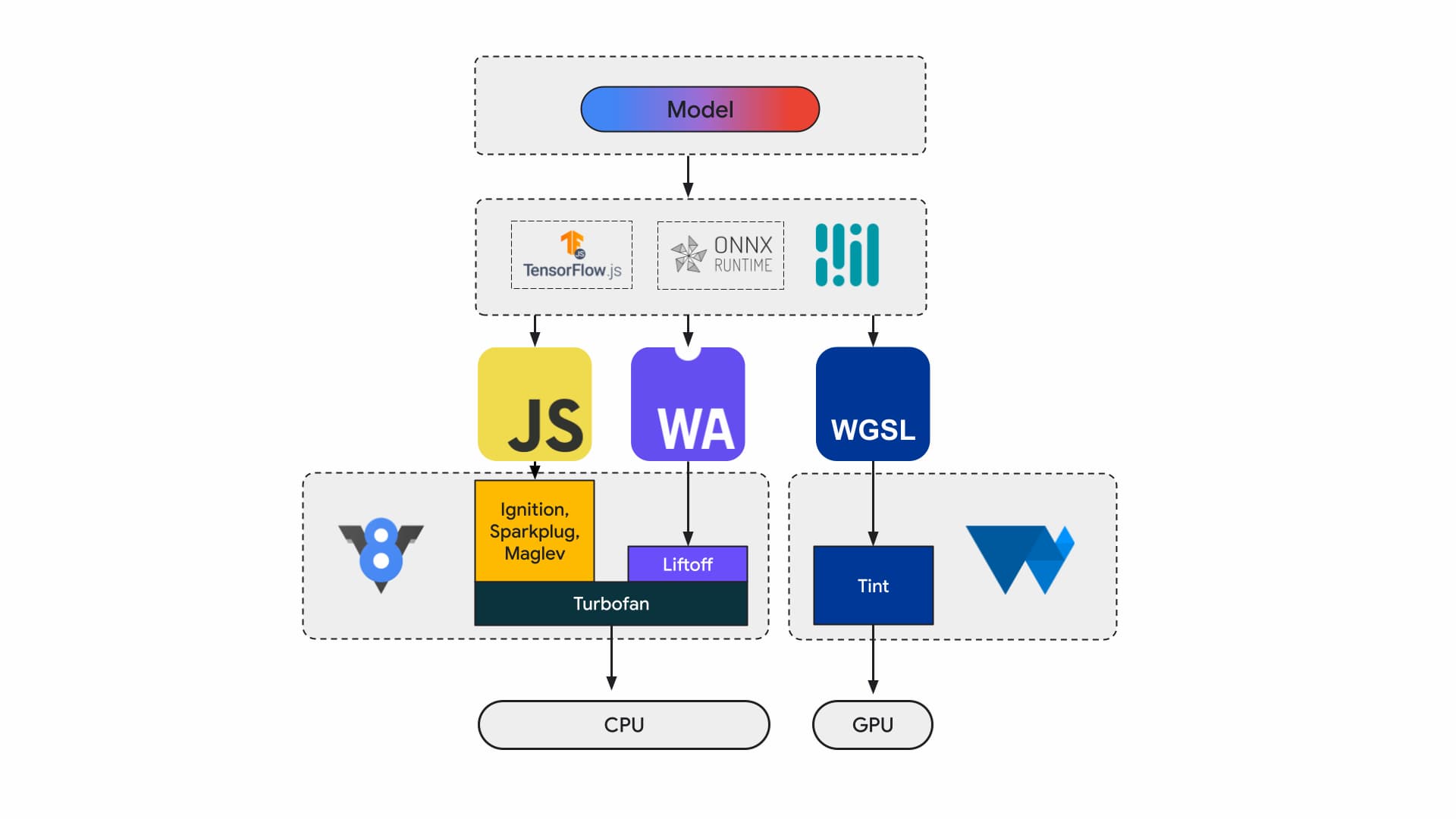
ML ワークロード
機械学習(ML)ワークロードは、計算ノードのグラフを介してテンソルを push します。テンソルは、データに対して大量の計算を行うこれらのノードの入力と出力です。
これは重要なことです。なぜなら、
- テンソルは非常に大きなデータ構造であり、数十億の重みを持つモデルに対して計算を行います。
- スケーリングと推論により、データ並列処理が実現できます。つまり、テンソル内のすべての要素に対して同じオペレーションが実行されます。
- ML では精度は必要ありません。月面着陸には 64 ビットの浮動小数点数が必要になるかもしれませんが、顔認識には 8 ビット以下の数値で十分な場合があります。
幸い、チップ設計者は、モデルの実行速度を上げ、温度を下げ、実行自体を可能にする機能を追加しています。
一方、WebAssembly チームと WebGPU チームでは、これらの新しい機能をウェブ デベロッパーに公開できるよう取り組んでいます。ウェブ アプリケーション デベロッパーは、これらの低レベルのプリミティブを頻繁に使用することはありません。使用しているツールチェーンまたはフレームワークが新機能と拡張機能をサポートしているため、インフラストラクチャの変更を最小限に抑えることができます。ただし、パフォーマンスを重視してアプリを手動でチューニングする場合は、これらの機能が役に立ちます。
WebAssembly
WebAssembly(Wasm)は、ランタイムが理解して実行できる、コンパクトで効率的なバイトコード形式です。基盤となるハードウェア機能を活用するように設計されているため、ネイティブに近い速度で実行できます。コードは検証され、メモリセーフのサンドボックス環境で実行されます。
Wasm モジュール情報は、高密度バイナリ エンコードで表されます。テキストベースの形式と比較して、デコードが高速化され、読み込みが高速化され、メモリ使用量が削減されます。モダン アーキテクチャにまだ一般的でない基盤となるアーキテクチャについて前提条件を設定しないという意味で、移植可能です。
WebAssembly の仕様は反復的であり、オープンな W3C コミュニティ グループで作業されています。
バイナリ形式ではホスト環境を前提としていないため、ウェブ以外のエンベディングでも適切に機能するように設計されています。
アプリケーションは 1 回コンパイルすれば、デスクトップ、ノートパソコン、スマートフォン、ブラウザを搭載したその他のデバイスなど、どこでも実行できます。詳しくは、Write once, run anywhere が WebAssembly でついに実現をご覧ください。
ウェブで AI 推論を実行するほとんどの本番環境アプリケーションは、CPU コンピューティングと特殊目的コンピューティングとのインターフェースの両方で WebAssembly を使用します。ネイティブ アプリケーションでは、アプリケーションがデバイスの機能にアクセスできるため、汎用コンピューティングと特殊用途コンピューティングの両方にアクセスできます。
ウェブでは、ポータビリティとセキュリティのために、公開されるプリミティブのセットを慎重に評価します。これにより、ウェブのアクセシビリティとハードウェアが提供する最大のパフォーマンスのバランスが取れます。
WebAssembly は CPU のポポータブルな抽象化であるため、すべての Wasm 推論は CPU で実行されます。これはパフォーマンスが最も高い選択肢ではありませんが、CPU は広く入手可能で、ほとんどのデバイスのほとんどのワークロードで動作します。
テキストや音声などの小規模なワークロードでは、GPU は高価になります。Wasm が適切な選択である最近の例は数多くあります。
- Adobe は TensorFlow.js を使用して、ウェブ向け Photoshop を強化しています。
- Google Meet に背景のぼかしが追加されました。これは、ウェブ上で初めての Wasm ベースの動画エフェクトの 1 つです。
- YouTube にはいくつかの拡張現実効果があります。
- Google フォトではオンライン編集が可能です。
whisper-tiny、llama.cpp、ブラウザで実行される Gemma2B などのオープンソースのデモで、さらに多くのことを確認できます。
アプリケーションに包括的なアプローチを適用する
プリミティブは、特定の ML モデル、アプリケーション インフラストラクチャ、ユーザー向けの全体的なアプリケーション エクスペリエンスに基づいて選択する必要があります。
たとえば、MediaPipe の顔ランドマーク検出では、CPU 推論と GPU 推論は同等ですが(Apple M1 デバイスで実行)、ばらつきが大幅に大きいモデルもあります。
ML ワークロードについては、フレームワークの作成者とアプリケーション パートナーの意見に耳を傾けながら、アプリケーションの包括的なビューを考慮し、最も要望の多い機能強化を開発してリリースしています。これらは大きく 3 つのカテゴリに分類されます。
- パフォーマンスに不可欠な CPU 拡張機能を公開する
- 大規模なモデルの実行を可能にする
- 他の Web API とのシームレスな相互運用を可能にする
コンピューティングの高速化
現時点では、WebAssembly 仕様には、ウェブに公開する特定の命令セットのみが含まれています。しかし、ハードウェアには新しい命令が継続的に追加されており、ネイティブと WebAssembly のパフォーマンスの差は広がっています。
ML モデルでは、必ずしも高い精度が必要とは限りません。Relaxed SIMD は、厳格な非決定性要件の一部を軽減し、パフォーマンスのホットスポットである一部のベクトル演算の codegen を高速化することを目的とした提案です。さらに、Relaxed SIMD では、既存のワークロードを 1.5 ~ 3 倍高速化する新しいドット積命令と FMA 命令が導入されています。これは Chrome 114 でリリースされました。
半精度浮動小数点形式では、単精度値に使用される 32 ビットではなく、IEEE FP16 に 16 ビットが使用されます。単精度値と比較して、半精度値を使用するにはいくつかの利点があります。メモリ要件が削減され、大規模なニューラル ネットワークのトレーニングとデプロイが可能になり、メモリ帯域幅が削減されます。精度を下げると、データ転送と演算の速度が向上します。
大規模なモデル
Wasm リニアメモリへのポインタは 32 ビット整数で表されます。これには 2 つの結果があります。ヒープサイズは 4 GB に制限されます(コンピュータの物理 RAM がそれよりはるかに多い場合)。また、Wasm をターゲットとするアプリケーション コードは、32 ビット ポインタサイズと互換性がある必要があります。
特に、現在のような大規模なモデルの場合、これらのモデルを WebAssembly に読み込むと制限が生じる可能性があります。Memory64 プロポーザルでは、リニアメモリを 4 GB より大きくし、ネイティブ プラットフォームのアドレス空間と一致させることで、これらの制限を解除します。
Chrome では完全な実装が完了しており、年内にリリースされる予定です。現時点では、chrome://flags/#enable-experimental-webassembly-features フラグを使用してテストを実施し、フィードバックをお送りいただけます。
ウェブの相互運用性の向上
WebAssembly は、ウェブ上の特殊なコンピューティングのエントリ ポイントになる可能性があります。
WebAssembly を使用すると、GPU アプリケーションをウェブに導入できます。つまり、デバイス上で実行できる C++ アプリケーションは、軽微な変更を加えてウェブでも実行できます。
Wasm コンパイラ ツールチェーンである Emscripten には、すでに WebGPU のバインディングがあります。これはウェブ上の AI 推論のエントリ ポイントであるため、Wasm が他のウェブ プラットフォームとシームレスに相互運用できることが重要です。Google では、この分野でいくつかの提案に取り組んでいます。
JavaScript Promise 統合(JSPI)
一般的な C および C++(および他の多くの言語)のアプリケーションは、通常、同期 API に対して記述されます。つまり、オペレーションが完了するまで、アプリケーションの実行は停止します。このようなブロック アプリケーションは、通常、非同期対応のアプリケーションよりも直感的に記述できます。
コストの高いオペレーションがメインスレッドをブロックすると、I/O がブロックされ、ジャンクがユーザーに表示されます。ネイティブ アプリケーションの同期プログラミング モデルとウェブの非同期モデルの間には不一致があります。これは、移植に費用がかかるレガシー アプリケーションで特に問題になります。Emscripten には Asyncify でこれを行う方法がありますが、コードサイズが大きくなり、効率が低下するため、これが最適な選択肢であるとは限りません。
次の例では、JavaScript の Promise を使用して加算し、フィボナッチ数を計算します。
long promiseFib(long x) {
if (x == 0)
return 0;
if (x == 1)
return 1;
return promiseAdd(promiseFib(x - 1), promiseFib(x - 2));
}
// promise an addition
EM_ASYNC_JS(long, promiseAdd, (long x, long y), {
return Promise.resolve(x+y);
});
emcc -O3 fib.c -o b.html -s ASYNCIFY=2
この例では、次の点に注意してください。
EM_ASYNC_JSマクロは、通常の関数の場合と同様に、JSPI を使用して Promise の結果にアクセスできるように、必要なグルーコードをすべて生成します。- 特別なコマンドライン オプション
-s ASYNCIFY=2。これにより、JSPI を使用してプロミスを返す JavaScript インポートとインターフェースするコードを生成するオプションが呼び出されます。
JSPI、その使用方法、メリットについて詳しくは、v8.dev での WebAssembly JavaScript Promise Integration API の紹介をご覧ください。現在のオリジン トライアルについて学びます。
メモリ制御
デベロッパーは Wasm メモリをほとんど制御できません。モジュールは独自のメモリを所有します。このメモリにアクセスする必要がある API は、コピーインまたはコピーアウトを行う必要があります。この使用量は非常に大きくなる場合もあります。たとえば、グラフィック アプリケーションでは、フレームごとにコピーインとコピーアウトが必要になる場合があります。
メモリ制御プロポーザルは、Wasm リニアメモリをきめ細かく制御し、アプリケーション パイプライン全体のコピー数を削減することを目的としています。この提案はフェーズ 1 です。標準の進化を反映するため、Chrome の JavaScript エンジンである V8 でプロトタイプを作成しています。
最適なバックエンドを決定する
CPU はどこにでもあるものですが、必ずしも最適な選択肢とは限りません。GPU またはアクセラレータでの専用コンピューティングでは、特に大規模なモデルやハイエンド デバイスで、桁違いのパフォーマンスを実現できます。これは、ネイティブ アプリケーションとウェブ アプリケーションの両方に当てはまります。
どのバックエンドを利用するかは、アプリケーション、フレームワーク、ツールチェーン、パフォーマンスに影響するその他の要因によって異なります。ただし、Google は、コア Wasm が他のウェブ プラットフォーム(特に WebGPU)と連携できるようにするための提案に引き続き投資しています。