

La compilación de sitios web que respondan rápidamente a las entradas del usuario ha sido uno de los aspectos más desafiantes del rendimiento web, en el que el equipo de Chrome ha trabajado arduamente para ayudar a los desarrolladores web a cumplir. Este año, se anunció que la métrica Interacción a la siguiente pintura (INP) pasaría de ser experimental a pendiente. Ahora está listo para reemplazar el retraso de primera entrada (FID) como Métrica web esencial en marzo de 2024.
En un esfuerzo continuo por ofrecer nuevas APIs que ayuden a los desarrolladores web a que sus sitios web sean lo más ágiles posible, el equipo de Chrome está ejecutando una prueba de origen para scheduler.yield a partir de la versión 115 de Chrome. scheduler.yield es una nueva incorporación propuesta a la API del programador que permite una forma más fácil y mejor de devolver el control al subproceso principal que los métodos que se usaban tradicionalmente.
Cuando se produce un rendimiento
JavaScript usa el modelo de ejecución hasta la finalización para controlar las tareas. Esto significa que, cuando una tarea se ejecuta en el subproceso principal, esta se ejecuta durante el tiempo necesario para completarse. Cuando se completa una tarea, el control se devuelve al subproceso principal, lo que le permite procesar la siguiente tarea de la cola.
Aparte de los casos extremos en los que una tarea nunca termina (como un bucle infinito, por ejemplo), la entrega es un aspecto inevitable de la lógica de programación de tareas de JavaScript. Sucederá, solo es cuestión de cuándo, y es mejor hacerlo cuanto antes. Cuando las tareas tardan demasiado en ejecutarse (más de 50 milisegundos, para ser exactos), se consideran tareas largas.
Las tareas largas son una fuente de baja capacidad de respuesta de la página, ya que retrasan la capacidad del navegador para responder a las entradas del usuario. Cuanto más a menudo se produzcan tareas largas y cuanto más tiempo se ejecuten, es más probable que los usuarios tengan la impresión de que la página es lenta o incluso que está completamente dañada.
Sin embargo, solo porque tu código inicia una tarea en el navegador no significa que debas esperar hasta que se complete esa tarea antes de que se devuelva el control al subproceso principal. Puedes mejorar la capacidad de respuesta a las entradas del usuario en una página si cedes explícitamente en una tarea, lo que la divide para que se termine en la próxima oportunidad disponible. Esto permite que otras tareas obtengan tiempo en el subproceso principal antes que si tuvieran que esperar a que terminen las tareas largas.
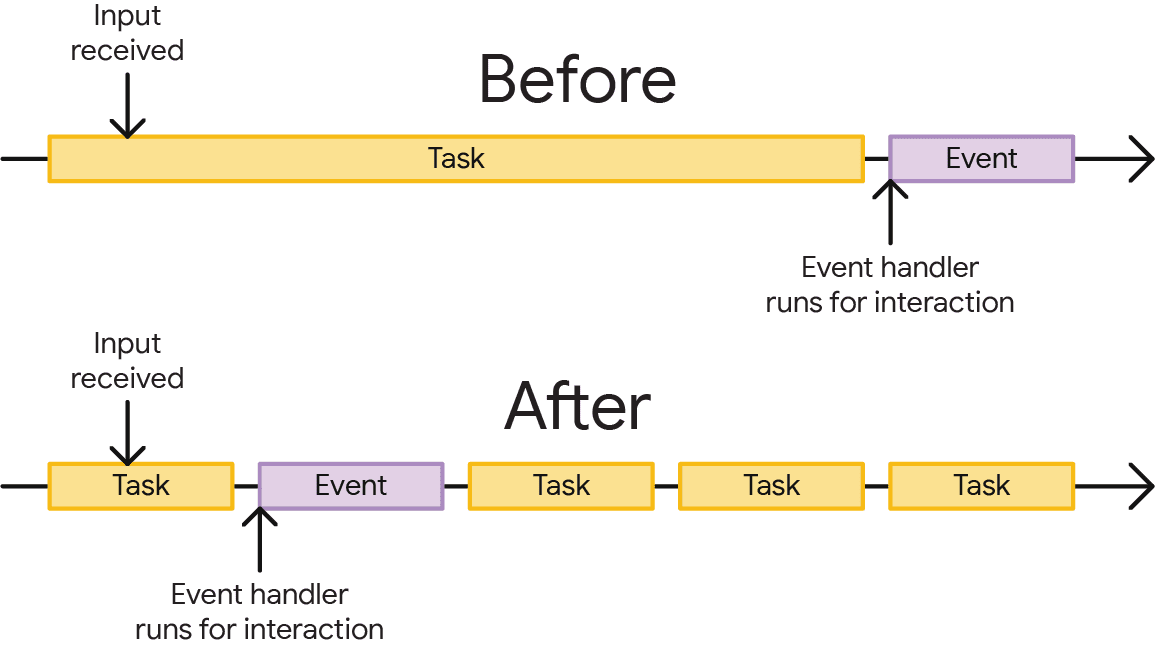
Cuando cedes de forma explícita, le dices al navegador: "Entiendo que el trabajo que voy a realizar podría demorar un tiempo y no quiero que tengas que hacer todo ese trabajo antes de responder a la entrada del usuario o a otras tareas que también podrían ser importantes". Es una herramienta valiosa en el kit de herramientas de un desarrollador que puede ser muy útil para mejorar la experiencia del usuario.
El problema con las estrategias de rendimiento actuales
Un método común para generar usa setTimeout con un valor de tiempo de espera de 0. Esto funciona porque la devolución de llamada que se pasa a setTimeout moverá el trabajo restante a una tarea independiente que se pondrá en cola para la ejecución posterior. En lugar de esperar a que el navegador genere resultados por sí solo, le dices que divida esta gran cantidad de trabajo en partes más pequeñas.
Sin embargo, ceder con setTimeout tiene un efecto secundario potencialmente no deseado: el trabajo que se produce después del punto de cesión irá al final de la cola de tareas. Las tareas programadas por las interacciones del usuario seguirán yendo al principio de la cola como deberían, pero el trabajo restante que querías hacer después de ceder explícitamente podría retrasarse aún más por otras tareas de fuentes en competencia que estaban en cola antes que ella.
Para ver cómo funciona, prueba esta demostración de Codepen o experimenta con ella en la siguiente versión incorporada. La demostración consta de algunos botones en los que puedes hacer clic y un cuadro debajo de ellos que registra cuándo se ejecutan las tareas. Cuando llegues a la página, realiza las siguientes acciones:
- Haz clic en el botón de la parte superior etiquetado como Run tasks periodically, que programará tareas de bloqueo para que se ejecuten cada tanto. Cuando hagas clic en este botón, el registro de tareas se propagará con varios mensajes que dicen Se ejecutó la tarea de bloqueo con
setInterval. - Luego, haz clic en el botón etiquetado Run loop, yielding with
setTimeouton each iteration.
Notarás que el cuadro en la parte inferior de la demostración dirá algo como lo siguiente:
Processing loop item 1
Processing loop item 2
Ran blocking task via setInterval
Processing loop item 3
Ran blocking task via setInterval
Processing loop item 4
Ran blocking task via setInterval
Processing loop item 5
Ran blocking task via setInterval
Ran blocking task via setInterval
Este resultado demuestra el comportamiento de "fin de la cola de tareas" que se produce cuando se cede con setTimeout. El bucle que se ejecuta procesa cinco elementos y genera setTimeout después de que se procesa cada uno.
Esto ilustra un problema común en la Web: no es inusual que una secuencia de comandos, en particular una de terceros, registre una función de temporizador que ejecute tareas en algún intervalo. El comportamiento de "fin de la cola de tareas" que se produce cuando se cede con setTimeout significa que el trabajo de otras fuentes de tareas puede ponerse en cola antes que el trabajo restante que el bucle debe hacer después de ceder.
Según tu aplicación, este puede ser o no un resultado deseable, pero, en muchos casos, este comportamiento es el motivo por el que los desarrolladores pueden sentirse reacios a renunciar al control del subproceso principal con tanta facilidad. La cesión es buena porque las interacciones del usuario tienen la oportunidad de ejecutarse antes, pero también permite que otras interacciones que no son del usuario también tengan tiempo en el subproceso principal. Es un problema real, pero scheduler.yield puede ayudarte a resolverlo.
Ingresa scheduler.yield.
scheduler.yield está disponible detrás de una marca como una función experimental de la plataforma web desde la versión 115 de Chrome. Una pregunta que podrías tener es “¿por qué necesito una función especial para generar cuando setTimeout ya lo hace?”.
Vale la pena señalar que la cesión no era un objetivo de diseño de setTimeout, sino un buen efecto secundario de programar una devolución de llamada para que se ejecute más adelante, incluso con un valor de tiempo de espera de 0 especificado. Sin embargo, lo más importante que debes recordar es que ceder con setTimeout envía el trabajo restante a la parte posterior de la cola de tareas. De forma predeterminada, scheduler.yield envía el trabajo restante al principio de la cola. Esto significa que el trabajo que deseas reanudar inmediatamente después de ceder no pasará a un segundo plano en comparación con las tareas de otras fuentes (con la excepción notable de las interacciones del usuario).
scheduler.yield es una función que cede al subproceso principal y muestra un Promise cuando se la llama. Esto significa que puedes await en una función async:
async function yieldy () {
// Do some work...
// ...
// Yield!
await scheduler.yield();
// Do some more work...
// ...
}
Para ver scheduler.yield en acción, haz lo siguiente:
- Navega a
chrome://flags. - Habilita el experimento Funciones experimentales de la plataforma web. Es posible que debas reiniciar Chrome después de hacerlo.
- Navega a la página de demostración o usa la siguiente versión incorporada después de esta lista.
- Haz clic en el botón de la parte superior etiquetado como Ejecutar tareas periódicamente.
- Por último, haz clic en el botón etiquetado como Run loop, yielding with
scheduler.yieldon each iteration.
El resultado en el cuadro de la parte inferior de la página se verá de la siguiente manera:
Processing loop item 1
Processing loop item 2
Processing loop item 3
Processing loop item 4
Processing loop item 5
Ran blocking task via setInterval
Ran blocking task via setInterval
Ran blocking task via setInterval
Ran blocking task via setInterval
Ran blocking task via setInterval
A diferencia de la demostración que genera con setTimeout, puedes ver que el bucle, aunque genera después de cada iteración, no envía el trabajo restante al final de la cola, sino al principio. Esto te brinda lo mejor de ambos mundos: puedes ceder para mejorar la capacidad de respuesta de las entradas en tu sitio web, pero también asegurarte de que el trabajo que querías terminar después de ceder no se retrase.
¡Pruébalo!
Si scheduler.yield te parece interesante y quieres probarlo, puedes hacerlo de dos maneras a partir de la versión 115 de Chrome:
- Si quieres experimentar con
scheduler.yieldde forma local, escribechrome://flagsen la barra de direcciones de Chrome y selecciona Habilitar en el menú desplegable de la sección Funciones experimentales de la plataforma web. De esta manera,scheduler.yield(y cualquier otra función experimental) estará disponible solo en tu instancia de Chrome. - Si quieres habilitar
scheduler.yieldpara usuarios reales de Chromium en un origen de acceso público, deberás registrarte en la prueba de origen descheduler.yield. Esto te permite experimentar de forma segura con las funciones propuestas durante un período determinado y le brinda al equipo de Chrome estadísticas valiosas sobre cómo se usan esas funciones en el campo. Para obtener más información sobre cómo funcionan las pruebas de origen, lee esta guía.
La forma en que uses scheduler.yield (sin dejar de admitir navegadores que no lo implementen) depende de tus objetivos. Puedes usar el polyfill oficial. El polyfill es útil si se cumple alguna de las siguientes condiciones:
- Ya usas
scheduler.postTasken tu aplicación para programar tareas. - Quieres poder establecer tareas y prioridades de rendimiento.
- Supongamos que quieres poder cancelar o repriorizar tareas con la clase
TaskControllerque ofrece la API descheduler.postTask.
Si esta no es tu situación, es posible que el polyfill no sea adecuado para ti. En ese caso, puedes implementar tu propio resguardo de varias maneras. El primer enfoque usa scheduler.yield si está disponible, pero recurre a setTimeout si no lo está:
// A function for shimming scheduler.yield and setTimeout:
function yieldToMain () {
// Use scheduler.yield if it exists:
if ('scheduler' in window && 'yield' in scheduler) {
return scheduler.yield();
}
// Fall back to setTimeout:
return new Promise(resolve => {
setTimeout(resolve, 0);
});
}
// Example usage:
async function doWork () {
// Do some work:
// ...
await yieldToMain();
// Do some other work:
// ...
}
Esto puede funcionar, pero, como puedes imaginar, los navegadores que no admiten scheduler.yield no mostrarán el comportamiento de "fila de prioridad". Si eso significa que prefieres no generar rendimientos, puedes probar otro enfoque que use scheduler.yield si está disponible, pero que no generará rendimientos si no lo está:
// A function for shimming scheduler.yield with no fallback:
function yieldToMain () {
// Use scheduler.yield if it exists:
if ('scheduler' in window && 'yield' in scheduler) {
return scheduler.yield();
}
// Fall back to nothing:
return;
}
// Example usage:
async function doWork () {
// Do some work:
// ...
await yieldToMain();
// Do some other work:
// ...
}
scheduler.yield es una incorporación emocionante a la API del programador, que esperamos que les permita a los desarrolladores mejorar la capacidad de respuesta más que las estrategias de rendimiento actuales. Si crees que scheduler.yield es una API útil, participa en nuestra investigación para ayudar a mejorarla y envía comentarios sobre cómo podría mejorarse aún más.
Imagen hero de Unsplash, por Jonathan Allison.