
ナビゲーションでの動作
この記事は、Chrome の内部の仕組みを探る 4 部構成のブログシリーズのパート 2 です。前回の投稿では、さまざまなプロセスとスレッドがブラウザのさまざまな部分を処理する方法について説明しました。この記事では、ウェブサイトを表示するために各プロセスとスレッドがどのように通信するかについて詳しく説明します。
ウェブブラウジングの簡単なユースケースを見てみましょう。ブラウザに URL を入力すると、ブラウザはインターネットからデータを取得してページを表示します。この記事では、ユーザーがサイトをリクエストし、ブラウザがページのレンダリングを準備する部分(ナビゲーション)に焦点を当てます。
ブラウザ プロセスから開始
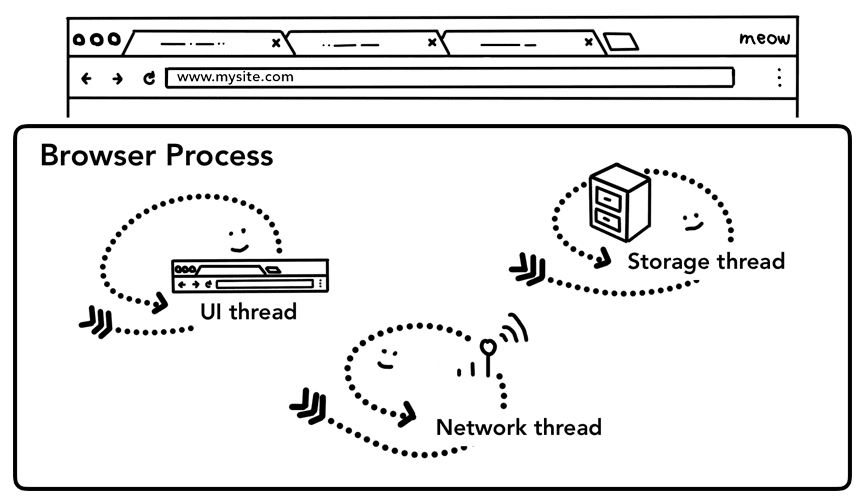
パート 1: CPU、GPU、メモリ、マルチプロセス アーキテクチャで説明したように、タブ外のすべてはブラウザ プロセスによって処理されます。ブラウザ プロセスには、ブラウザのボタンや入力フィールドを描画する UI スレッド、インターネットからデータを受信するためにネットワーク スタックを処理するネットワーク スレッド、ファイルへのアクセスを制御するストレージ スレッドなどがあります。アドレスバーに URL を入力すると、入力はブラウザ プロセスの UI スレッドによって処理されます。
シンプルなナビゲーション
ステップ 1: 入力を処理する
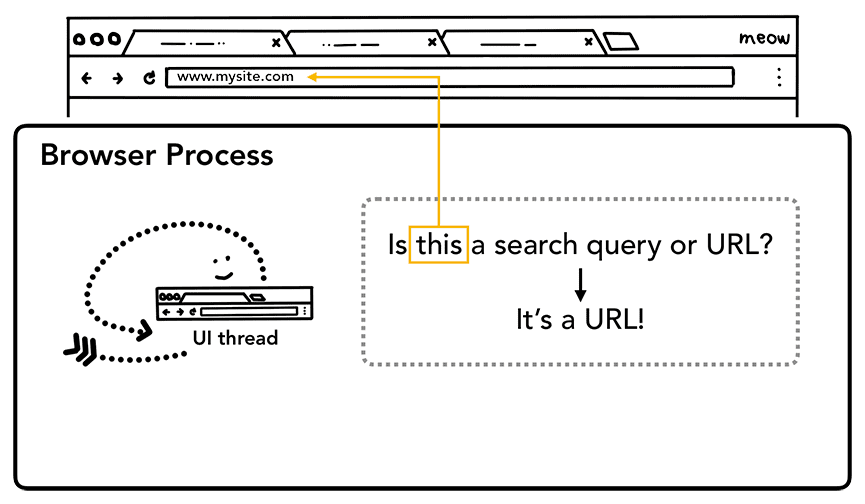
ユーザーがアドレスバーに入力を開始すると、UI スレッドはまず「これは検索クエリですか、それとも URL ですか?」と尋ねます。Chrome では、アドレスバーは検索入力フィールドでもあるため、UI スレッドが解析して、検索エンジンにリダイレクトするか、リクエストされたサイトにリダイレクトするかを決定する必要があります。
ステップ 2: ナビを開始する
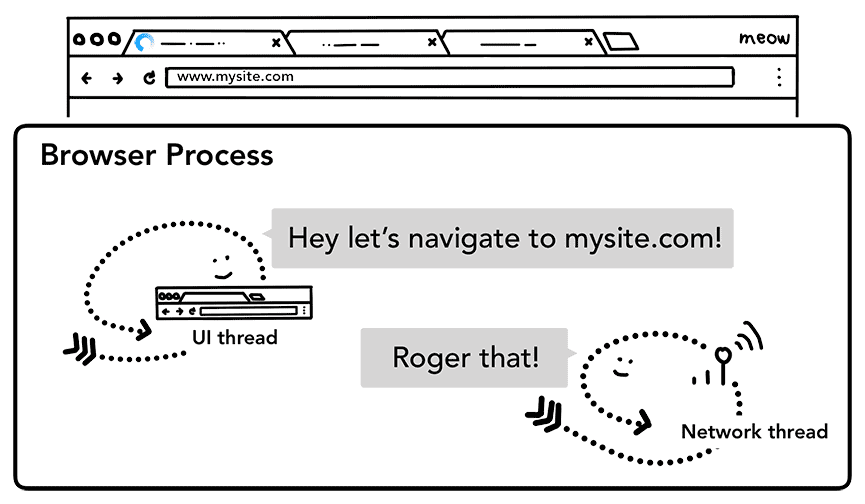
ユーザーが Enter キーを押すと、UI スレッドがネットワーク呼び出しを開始してサイト コンテンツを取得します。タブの隅に読み込みスピナーが表示され、ネットワーク スレッドは DNS ルックアップやリクエストの TLS 接続の確立など、適切なプロトコルを実行します。
この時点で、ネットワーク スレッドは HTTP 301 などのサーバー リダイレクト ヘッダーを受信することがあります。その場合、ネットワーク スレッドは、サーバーがリダイレクトをリクエストしていることを UI スレッドに通知します。その後、別の URL リクエストが開始されます。
ステップ 3: 回答を読み上げる
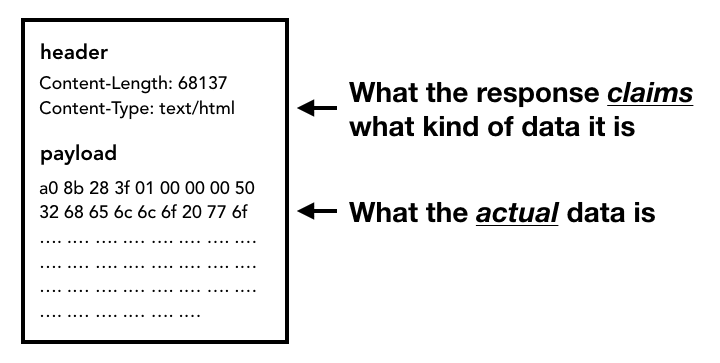
レスポンス本文(ペイロード)の受信が開始されると、ネットワーク スレッドは必要に応じてストリームの最初の数バイトを確認します。レスポンスの Content-Type ヘッダーにはデータの種類が記載されていますが、ヘッダーが欠落している場合や間違っている場合があるため、ここで MIME タイプのスニッフィングが行われます。これは、ソースコードでコメントされているように「難しい作業」です。コメントを読んで、さまざまなブラウザが content-type/ペイロードのペアをどのように扱うかを確認できます。
レスポンスが HTML ファイルの場合は、次のステップでレンダラ プロセスにデータを渡します。ZIP ファイルなどのファイルの場合は、ダウンロード リクエストであるため、ダウンロード マネージャーにデータを渡す必要があります。

また、SafeBrowsing チェックもここで行われます。ドメインとレスポンス データが既知の悪意のあるサイトと一致していると思われる場合、ネットワーク スレッドがアラートを発して警告ページを表示します。また、Cross Origin Read Blocking(CORB)チェックが行われ、機密性の高いクロスサイト データがレンダラ プロセスに到達しないようにします。
ステップ 4: レンダラ プロセスを見つける
すべてのチェックが完了し、ネットワーク スレッドがブラウザがリクエストされたサイトに移動する必要があることを確認すると、ネットワーク スレッドはデータの準備ができていることを UI スレッドに通知します。次に、UI スレッドはレンダラ プロセスを見つけて、ウェブページのレンダリングを続行します。
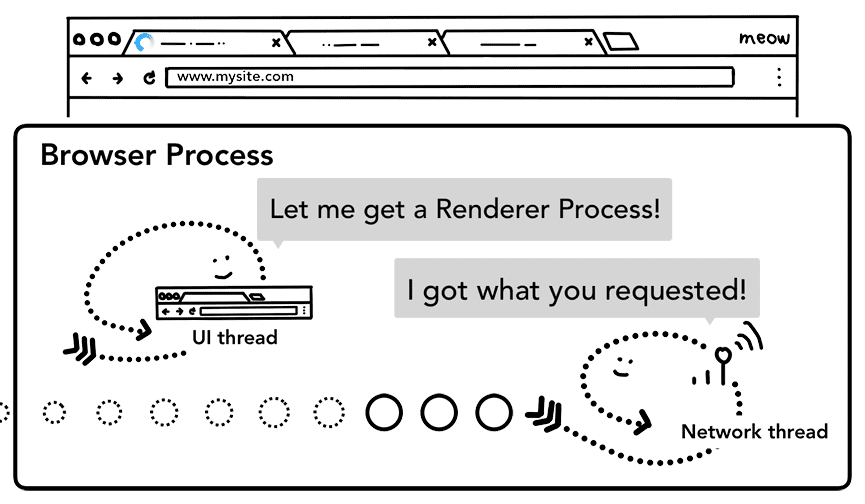
ネットワーク リクエストから応答が返されるまでに数百ミリ秒かかることがあるため、このプロセスを高速化するための最適化が適用されます。UI スレッドが手順 2 でネットワーク スレッドに URL リクエストを送信するときに、どのサイトに移動するかをすでに把握しています。UI スレッドは、ネットワーク リクエストと並行してレンダラ プロセスを事前に検出または開始しようとします。これにより、すべてが想定どおりに進んだ場合、ネットワーク スレッドがデータを受信したときに、レンダラ プロセスはすでにスタンバイ状態になっています。ナビゲーションがクロスサイトにリダイレクトされる場合、このスタンバイ プロセスは使用されないことがあります。その場合は、別のプロセスが必要になることがあります。
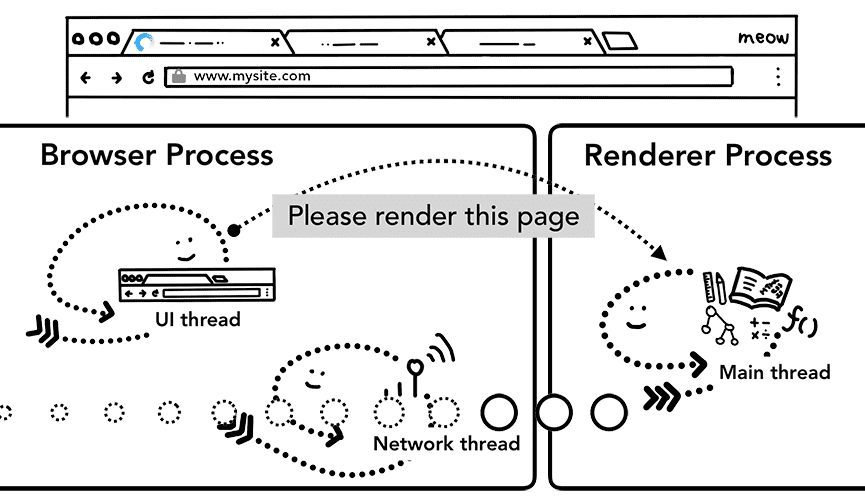
ステップ 5: ナビゲーションを commit する
データとレンダラ プロセスの準備ができたので、ブラウザ プロセスからレンダラ プロセスに IPC が送信され、ナビゲーションを commit します。また、レンダラ プロセスが HTML データを継続的に受信できるように、データ ストリームも渡します。レンダラ プロセスで commit が行われたことをブラウザ プロセスが確認すると、ナビゲーションが完了し、ドキュメントの読み込みフェーズが開始されます。
この時点で、アドレスバーが更新され、セキュリティ インジケーターとサイト設定 UI に新しいページのサイト情報が反映されます。タブのセッション履歴が更新され、移動したばかりのサイトを前後ボタンで移動できるようになります。タブまたはウィンドウを閉じたときにタブやセッションを簡単に復元できるように、セッション履歴はディスクに保存されます。
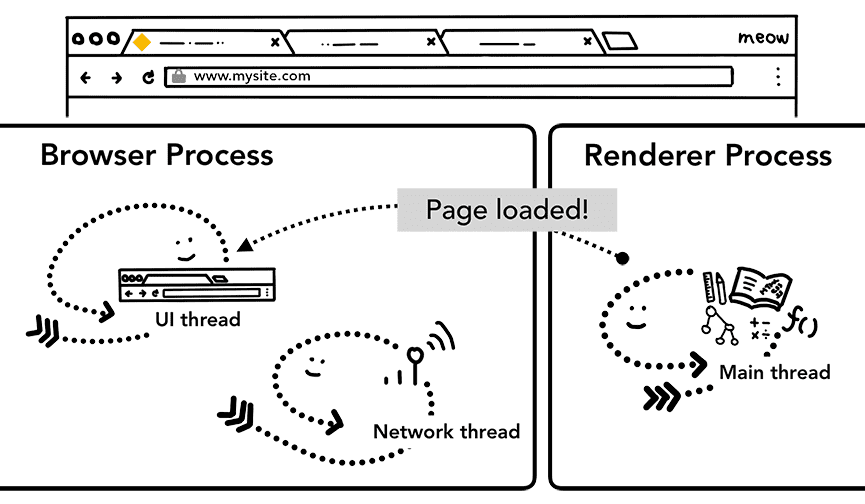
追加の手順: 初期読み込みの完了
ナビゲーションが commit されると、レンダラ プロセスはリソースの読み込みを続行し、ページをレンダリングします。この段階でどのような処理が行われるかについては、次の投稿で詳しく説明します。レンダラ プロセスがレンダリングを「完了」すると、IPC をブラウザ プロセスに送り返します(これは、ページ内のすべてのフレームですべての onload イベントがトリガーされ、実行が完了した後です)。この時点で、UI スレッドはタブの読み込みスピナーを停止します。
「終了」と表現したのは、この時点でもクライアントサイドの JavaScript が追加のリソースを読み込み、新しいビューをレンダリングする可能性があるためです。
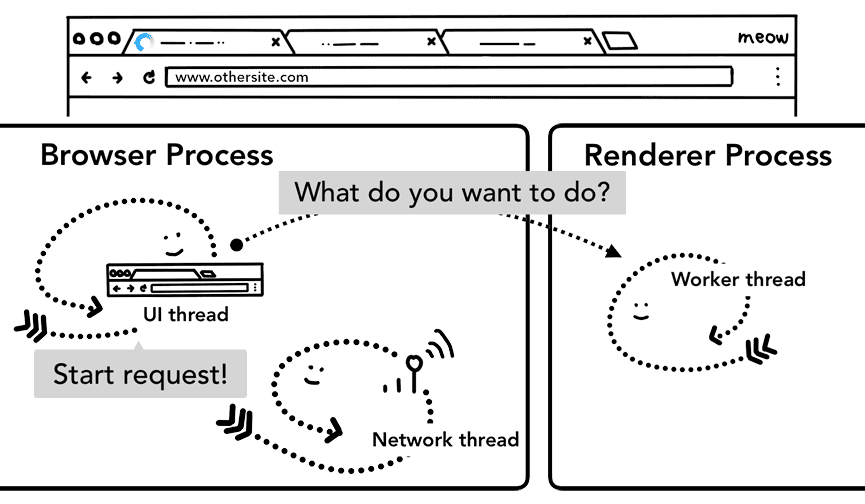
別のサイトに移動する
シンプルなナビゲーションが完成しました。では、ユーザーがアドレスバーに別の URL を入力した場合はどうなりますか?ブラウザのプロセスは、別のサイトに移動する際にも同じ手順を踏みます。ただし、その前に、現在レンダリングされているサイトが beforeunload イベントを気にしているかどうかを確認する必要があります。
beforeunload は、タブを移動または閉じようとしたときに「このサイトを離れますか?」というアラートを作成できます。JavaScript コードを含むタブ内のすべてはレンダラ プロセスによって処理されるため、新しいナビゲーション リクエストが届いたときに、ブラウザ プロセスは現在のレンダラ プロセスを確認する必要があります。

レンダラ プロセスからナビゲーションが開始された場合(ユーザーがリンクをクリックした、またはクライアントサイドの JavaScript が window.location = "https://newsite.com" を実行したなど)、レンダラ プロセスはまず beforeunload ハンドラを確認します。その後、ブラウザ プロセスが開始したナビゲーションと同じプロセスを経ます。唯一の違いは、ナビゲーション リクエストがレンダラ プロセスからブラウザ プロセスにキックオフされることです。
新しいナビゲーションが、現在レンダリングされているサイトとは異なるサイトに移動する場合、新しいナビゲーションを処理するために別のレンダリング プロセスが呼び出され、現在のレンダリング プロセスは unload などのイベントを処理するために保持されます。詳細については、ページのライフサイクルの状態の概要と、Page Lifecycle API を使用してイベントにフックする方法をご覧ください。

Service Worker の場合
このナビゲーション プロセスの最近の変更点の 1 つが、サービス ワーカーの導入です。サービス ワーカーは、アプリケーション コードにネットワーク プロキシを記述する方法です。これにより、ウェブ デベロッパーは、ローカルにキャッシュに保存する内容と、ネットワークから新しいデータを取得するタイミングをより細かく制御できます。Service Worker がキャッシュからページを読み込むように設定されている場合、ネットワークからデータをリクエストする必要はありません。
重要なのは、Service Worker はレンダラ プロセスで実行される JavaScript コードであるということです。ただし、ブラウザ プロセスは、ナビゲーション リクエストが届いたときに、サイトにサービス ワーカーがあることをどのようにして認識するのでしょうか。

サービス ワーカーが登録されると、サービス ワーカーのスコープの参照が保持されます(スコープについて詳しくは、サービス ワーカーのライフサイクルをご覧ください)。ナビゲーションが発生すると、ネットワーク スレッドは登録済みのサービス ワーカー スコープとドメインを照合します。その URL にサービス ワーカーが登録されている場合、UI スレッドはレンダラ プロセスを見つけてサービス ワーカー コードを実行します。サービス ワーカーは、キャッシュからデータを読み込み、ネットワークからデータをリクエストする必要をなくすことができます。また、ネットワークから新しいリソースをリクエストすることもできます。

ナビゲーションのプリロード
サービス ワーカーが最終的にネットワークからデータをリクエストする場合、ブラウザ プロセスとレンダラ プロセス間のこのラウンド トリップにより遅延が発生する可能性があります。ナビゲーション プリロードは、サービス ワーカーの起動と並行してリソースを読み込むことで、このプロセスを高速化するメカニズムです。これらのリクエストにはヘッダーが付けられ、サーバーはこのリクエストに対して異なるコンテンツ(ドキュメント全体ではなく更新されたデータのみなど)を送信するように決定できます。
まとめ
この投稿では、ナビゲーション中に何が起こるか、レスポンス ヘッダーやクライアントサイドの JavaScript などのウェブ アプリケーション コードがブラウザとどのようにやり取りするかについて説明しました。ブラウザがネットワークからデータを取得する手順を理解すると、ナビゲーション プリロードなどの API が開発された理由を簡単に理解できます。次回の投稿では、ブラウザが HTML/CSS/JavaScript を評価してページをレンダリングする方法について詳しく説明します。
投稿はいかがでしたか?今後の記事についてご質問やご提案がございましたら、以下のコメント欄または Twitter の @kosamari までお寄せください。