
नेविगेशन में क्या होता है
यह चार हिस्सों वाली ब्लॉग सीरीज़ का दूसरा हिस्सा है. इसमें Chrome के काम करने के तरीके के बारे में बताया गया है. पिछली पोस्ट में, हमने देखा था कि अलग-अलग प्रोसेस और थ्रेड, ब्राउज़र के अलग-अलग हिस्सों को कैसे मैनेज करते हैं. इस पोस्ट में, हम इस बारे में ज़्यादा जानकारी देंगे कि वेबसाइट दिखाने के लिए, हर प्रोसेस और थ्रेड कैसे आपस में बातचीत करते हैं.
वेब ब्राउज़िंग के इस्तेमाल के एक आसान उदाहरण पर नज़र डालें: ब्राउज़र में कोई यूआरएल टाइप करने पर, ब्राउज़र इंटरनेट से डेटा फ़ेच करता है और कोई पेज दिखाता है. इस पोस्ट में, हम उस हिस्से पर फ़ोकस करेंगे जहां कोई उपयोगकर्ता किसी साइट का अनुरोध करता है और ब्राउज़र किसी पेज को रेंडर करने के लिए तैयार होता है. इसे नेविगेशन भी कहा जाता है.
यह ब्राउज़र प्रोसेस से शुरू होती है
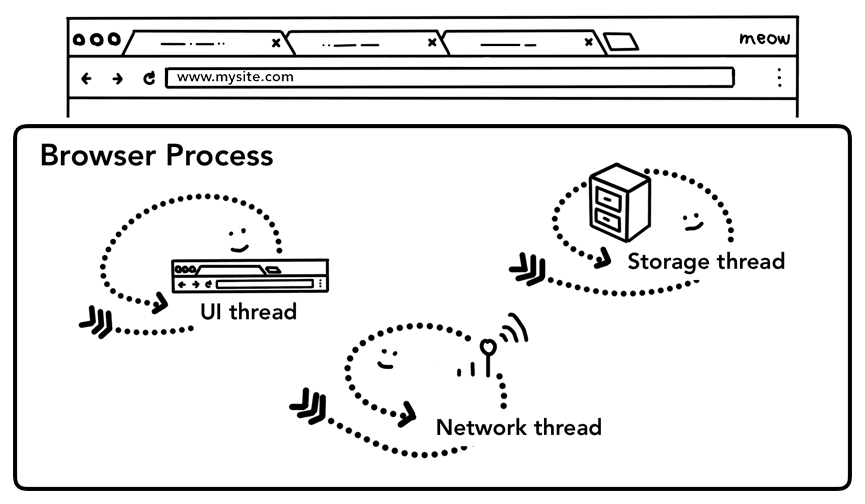
जैसा कि हमने पहले भाग: सीपीयू, जीपीयू, मेमोरी, और मल्टी-प्रोसेस आर्किटेक्चर में बताया है, टैब के बाहर की हर चीज़ को ब्राउज़र प्रोसेस मैनेज करती है. ब्राउज़र प्रोसेस में थ्रेड होते हैं. जैसे, यूज़र इंटरफ़ेस (यूआई) थ्रेड, जो ब्राउज़र के बटन और इनपुट फ़ील्ड को ड्रॉ करता है. नेटवर्क थ्रेड, जो इंटरनेट से डेटा पाने के लिए नेटवर्क स्टैक के साथ काम करता है. स्टोरेज थ्रेड, जो फ़ाइलों के ऐक्सेस को कंट्रोल करता है. जब पता बार में कोई यूआरएल टाइप किया जाता है, तो आपके इनपुट को ब्राउज़र प्रोसेस के यूज़र इंटरफ़ेस (यूआई) थ्रेड मैनेज करता है.
आसान नेविगेशन
पहला चरण: इनपुट मैनेज करना
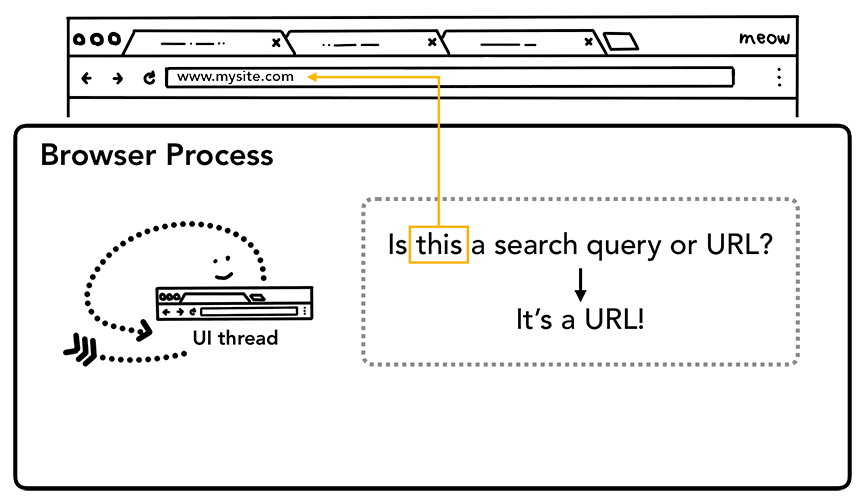
जब कोई उपयोगकर्ता पता बार में टाइप करना शुरू करता है, तो यूज़र इंटरफ़ेस थ्रेड सबसे पहले यह पूछता है कि "क्या यह खोज क्वेरी है या यूआरएल?". Chrome में, पता बार एक खोज इनपुट फ़ील्ड भी है. इसलिए, यूज़र इंटरफ़ेस (यूआई) थ्रेड को पार्स करके यह तय करना होता है कि आपको किसी सर्च इंजन पर भेजना है या उस साइट पर जिसका आपने अनुरोध किया है.
दूसरा चरण: नेविगेशन शुरू करना
जब कोई उपयोगकर्ता Enter दबाता है, तो यूज़र इंटरफ़ेस (यूआई) थ्रेड, साइट का कॉन्टेंट पाने के लिए नेटवर्क कॉल शुरू करता है. लोडिंग स्पिनर, टैब के कोने पर दिखता है. साथ ही, नेटवर्क थ्रेड, अनुरोध के लिए डीएनएस लुकअप और टीएलएस कनेक्शन बनाने जैसे सही प्रोटोकॉल से गुज़रता है.
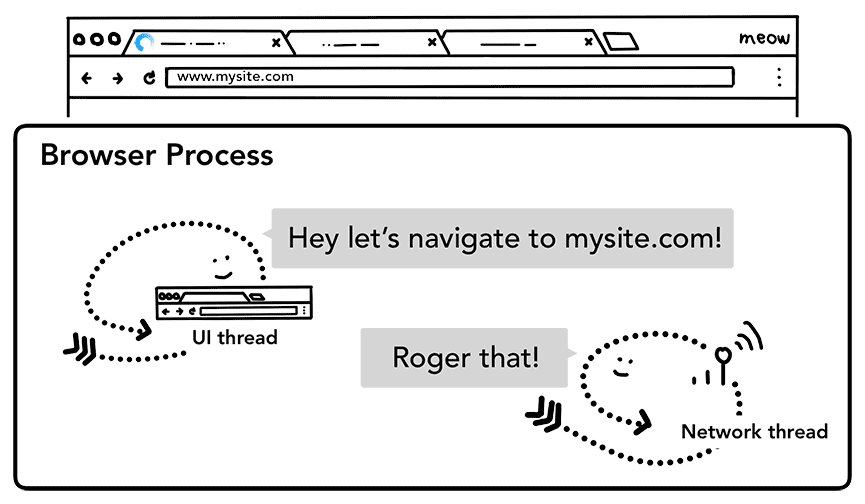
इस दौरान, नेटवर्क थ्रेड को एचटीटीपी 301 जैसे सर्वर रीडायरेक्ट हेडर मिल सकते हैं. ऐसे में, नेटवर्क थ्रेड, यूज़र इंटरफ़ेस (यूआई) थ्रेड से यह बताता है कि सर्वर रीडायरेक्ट का अनुरोध कर रहा है. इसके बाद, यूआरएल के लिए एक और अनुरोध शुरू किया जाएगा.
तीसरा चरण: जवाब पढ़ना
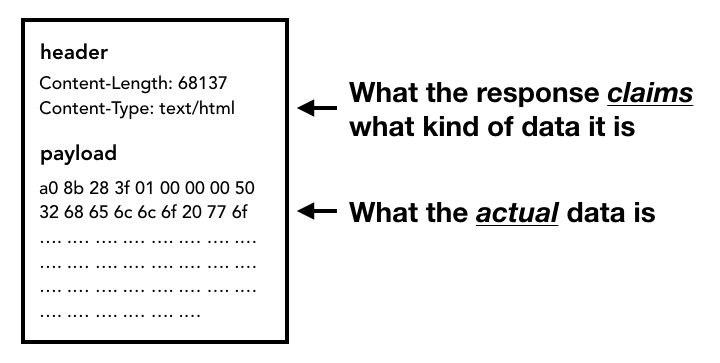
जब रिस्पॉन्स बॉडी (पेलोड) आने लगता है, तो नेटवर्क थ्रेड ज़रूरत पड़ने पर स्ट्रीम के पहले कुछ बाइट देखता है. रिस्पॉन्स के Content-Type हेडर से पता चलना चाहिए कि यह किस तरह का डेटा है. हालांकि, ऐसा हो सकता है कि यह हेडर मौजूद न हो या गलत हो. इसलिए, यहां MIME टाइप स्निफ़िंग की जाती है. सोर्स कोड में बताए गए तरीके से, यह "मुश्किल काम" है. टिप्पणी पढ़कर यह देखा जा सकता है कि अलग-अलग ब्राउज़र, कॉन्टेंट टाइप/पेलोड पेयर को कैसे हैंडल करते हैं.
अगर रिस्पॉन्स के तौर पर एचटीएमएल फ़ाइल मिलती है, तो अगला चरण डेटा को रेंडर करने की प्रोसेस में भेजना होगा. हालांकि, अगर यह कोई ZIP फ़ाइल या कोई दूसरी फ़ाइल है, तो इसका मतलब है कि यह डाउनलोड का अनुरोध है. इसलिए, उन्हें डेटा को डाउनलोड मैनेजर को भेजना होगा.
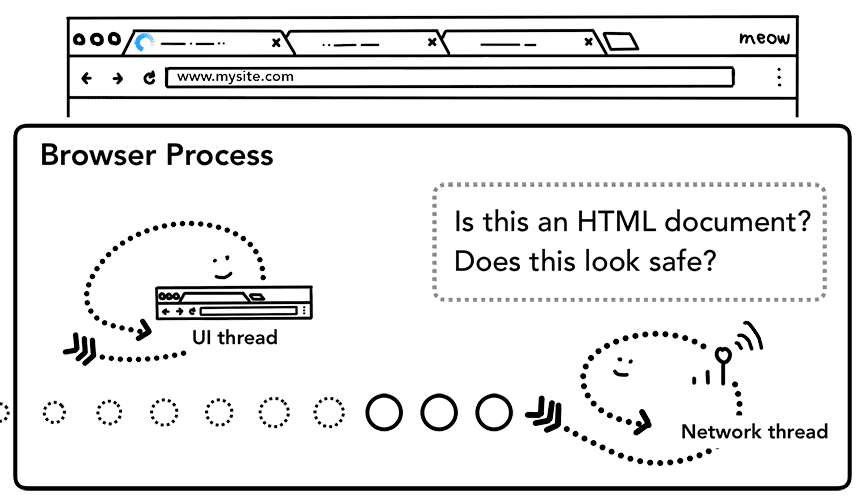
यहां SafeBrowsing की जांच भी की जाती है. अगर डोमेन और रिस्पॉन्स डेटा, किसी खतरनाक साइट से मेल खाता है, तो चेतावनी वाला पेज दिखाने के लिए नेटवर्क थ्रेड से सूचना मिलती है. इसके अलावा, क्रॉस ओरिजिन रीड ब्लॉकिंग (CORB) की जांच की जाती है, ताकि यह पक्का किया जा सके कि क्रॉस-साइट का संवेदनशील डेटा, रेंडरर प्रोसेस में न जाए.
चौथा चरण: रेंडर करने की प्रोसेस ढूंढना
सभी जांच पूरी होने और नेटवर्क थ्रेड को यह भरोसा होने के बाद कि ब्राउज़र को अनुरोध की गई साइट पर ले जाना चाहिए, नेटवर्क थ्रेड, यूज़र इंटरफ़ेस (यूआई) थ्रेड को बताता है कि डेटा तैयार है. इसके बाद, यूज़र इंटरफ़ेस (यूआई) थ्रेड, वेब पेज को रेंडर करने के लिए रेंडरर प्रोसेस ढूंढता है.
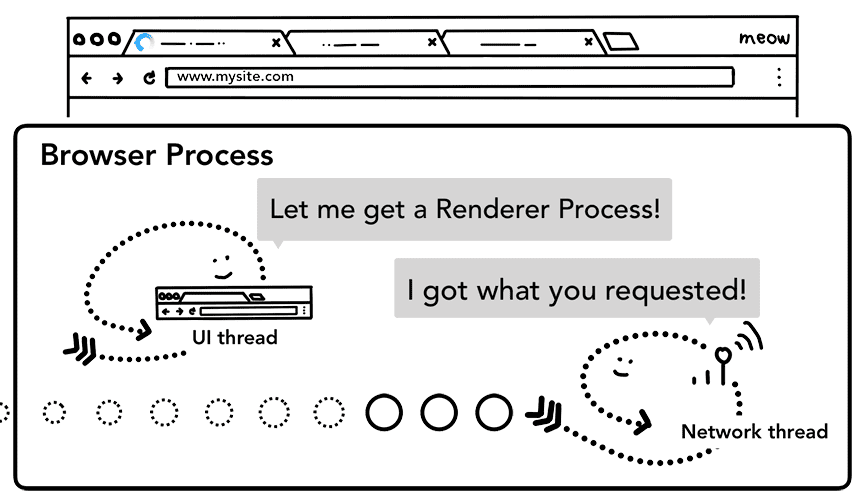
नेटवर्क अनुरोध को जवाब मिलने में कई सौ मिलीसेकंड लग सकते हैं. इसलिए, इस प्रोसेस को तेज़ करने के लिए ऑप्टिमाइज़ेशन लागू किया जाता है. जब यूज़र इंटरफ़ेस (यूआई) थ्रेड, दूसरे चरण में नेटवर्क थ्रेड को यूआरएल का अनुरोध भेज रहा होता है, तब उसे पहले से पता होता है कि वह किस साइट पर नेविगेट कर रहा है. यूज़र इंटरफ़ेस (यूआई) थ्रेड, नेटवर्क अनुरोध के साथ-साथ, पहले से ही रेंडरर प्रोसेस ढूंढने या शुरू करने की कोशिश करता है. इस तरह, अगर सब कुछ उम्मीद के मुताबिक होता है, तो नेटवर्क थ्रेड को डेटा मिलने पर, रेंडरर प्रोसेस पहले से ही स्टैंडबाय मोड में होती है. अगर नेविगेशन किसी दूसरी साइट पर रीडायरेक्ट करता है, तो हो सकता है कि इस स्टैंडबाय प्रोसेस का इस्तेमाल न किया जाए. ऐसे में, किसी दूसरी प्रोसेस की ज़रूरत पड़ सकती है.
पांचवां चरण: नेविगेशन को लागू करना
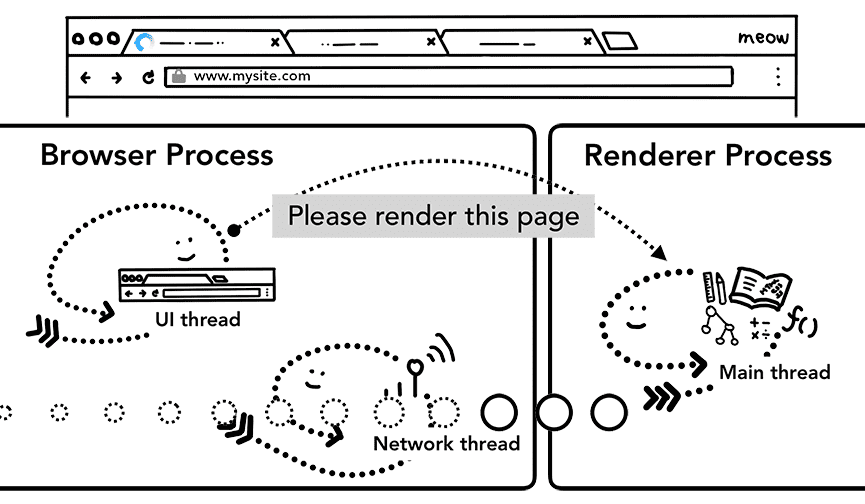
अब डेटा और रेंडरर प्रोसेस तैयार है. इसलिए, नेविगेशन को कमिट करने के लिए, ब्राउज़र प्रोसेस से रेंडरर प्रोसेस को आईपीसी भेजा जाता है. यह डेटा स्ट्रीम भी पास करता है, ताकि रेंडर करने की प्रोसेस को एचटीएमएल डेटा मिलता रहे. जब ब्राउज़र प्रोसेस को इस बात की पुष्टि मिल जाती है कि रेंडरर प्रोसेस में कमिट हो गया है, तो नेविगेशन पूरा हो जाता है और दस्तावेज़ लोड होने का फ़ेज़ शुरू हो जाता है.
इस दौरान, पता बार अपडेट हो जाता है. साथ ही, सुरक्षा इंडिकेटर और साइट सेटिंग यूज़र इंटरफ़ेस (यूआई), नए पेज की साइट की जानकारी दिखाता है. टैब के सेशन का इतिहास अपडेट हो जाएगा, ताकि बैक/फ़ॉरवर्ड बटन उस साइट पर ले जाएं जिस पर अभी-अभी नेविगेट किया गया था. टैब या सेशन को वापस लाने की सुविधा देने के लिए, टैब या विंडो बंद करने पर, सेशन का इतिहास डिस्क पर सेव किया जाता है.
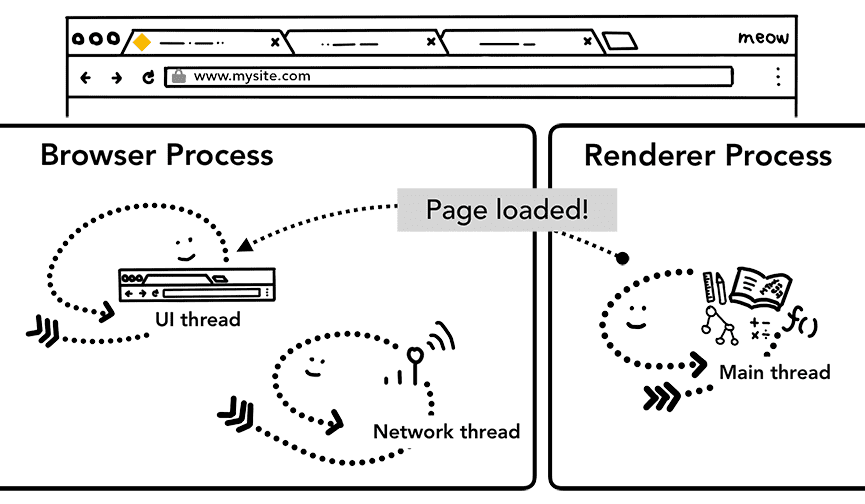
अतिरिक्त चरण: शुरुआती लोड पूरा हो गया
नेविगेशन की प्रोसेस पूरी होने के बाद, रेंडर करने की प्रोसेस रिसॉर्स लोड करती है और पेज को रेंडर करती है. हम अगली पोस्ट में इस बारे में पूरी जानकारी देंगे कि इस चरण में क्या होता है. रेंडरर प्रोसेस के रेंडर होने के बाद, वह ब्राउज़र प्रोसेस को एक आईपीसी भेजती है. ऐसा तब होता है, जब पेज के सभी फ़्रेम पर सभी onload इवेंट ट्रिगर हो जाते हैं और उन्हें पूरा कर लिया जाता है. इस समय,
यूज़र इंटरफ़ेस (यूआई) थ्रेड, टैब पर लोडिंग स्पिनर को बंद कर देता है.
मैंने "खत्म हो जाता है" कहा है, क्योंकि क्लाइंट साइड JavaScript इस बिंदु के बाद भी अतिरिक्त संसाधन लोड कर सकता है और नए व्यू रेंडर कर सकता है.
किसी दूसरी साइट पर जाना
आसान नेविगेशन पूरा हो गया! लेकिन, अगर कोई उपयोगकर्ता पता बार में फिर से कोई दूसरा यूआरएल डालता है, तो क्या होगा? अलग-अलग साइट पर जाने के लिए, ब्राउज़र की प्रोसेस में वही चरण अपनाए जाते हैं.
हालांकि, ऐसा करने से पहले, उसे फ़िलहाल रेंडर की गई साइट से यह पता करना होगा कि क्या उसे
beforeunload इवेंट की ज़रूरत है.
टैब को बंद करने या किसी दूसरे पेज पर जाने पर, beforeunload "क्या आपको इस साइट को छोड़ना है?" सूचना दिखा सकता है.
टैब में मौजूद हर चीज़ को रेंडरर प्रोसेस मैनेज करती है. इसमें आपका JavaScript कोड भी शामिल है. इसलिए, जब नया नेविगेशन अनुरोध आता है, तो ब्राउज़र प्रोसेस को मौजूदा रेंडरर प्रोसेस से जांच करनी होती है.
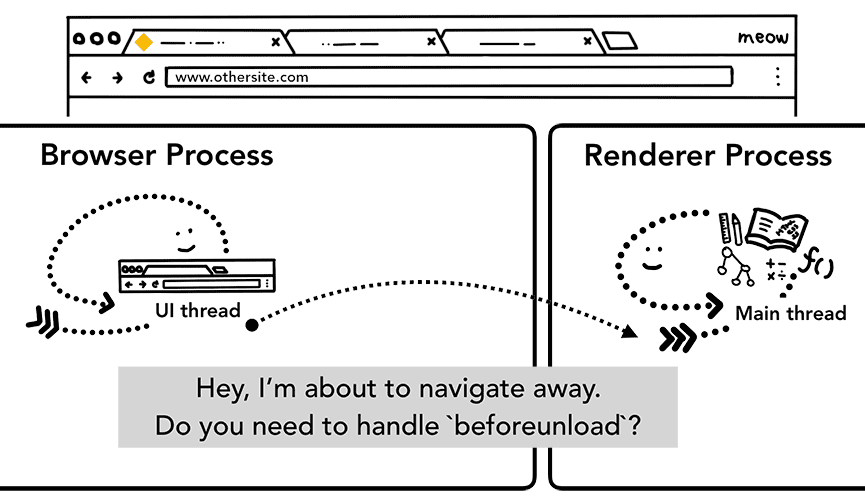
अगर नेविगेशन को रेंडरर प्रोसेस से शुरू किया गया था (जैसे, उपयोगकर्ता ने किसी लिंक पर क्लिक किया या क्लाइंट-साइड JavaScript ने window.location = "https://newsite.com" को चलाया है), तो रेंडरर प्रोसेस सबसे पहले beforeunload हैंडलर की जांच करती है. इसके बाद, यह उसी प्रोसेस से गुज़रता है जिससे ब्राउज़र की प्रोसेस से शुरू किया गया नेविगेशन गुज़रता है. इन दोनों में सिर्फ़ एक अंतर है. नेविगेशन अनुरोध, रेंडरर प्रोसेस से ब्राउज़र प्रोसेस पर भेजा जाता है.
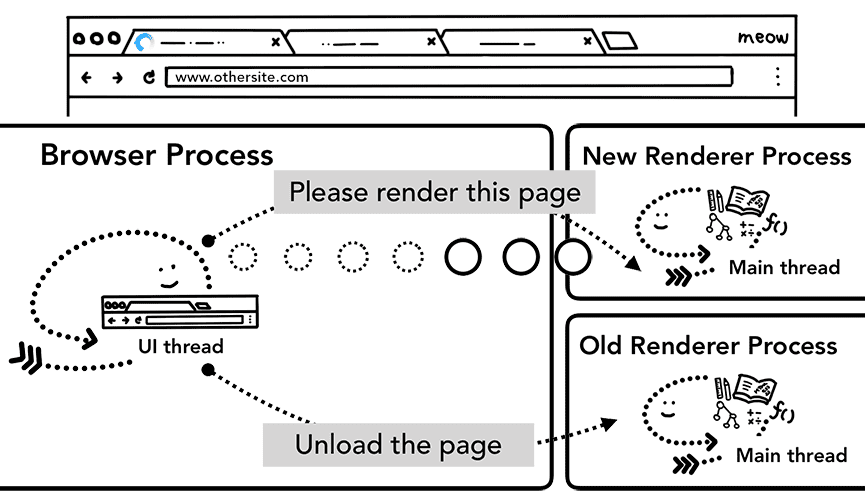
जब नया नेविगेशन, फ़िलहाल रेंडर की गई साइट से अलग साइट पर बनाया जाता है, तो नए नेविगेशन को मैनेज करने के लिए, रेंडर करने की एक अलग प्रोसेस को कॉल किया जाता है. वहीं, unload जैसे इवेंट को मैनेज करने के लिए, मौजूदा रेंडर प्रोसेस को रखा जाता है. ज़्यादा जानकारी के लिए, पेज के लाइफ़साइकल की स्थितियों की खास जानकारी देखें. साथ ही, पेज लाइफ़साइकल एपीआई की मदद से, इवेंट में कैसे शामिल हुआ जा सकता है, यह भी जानें.
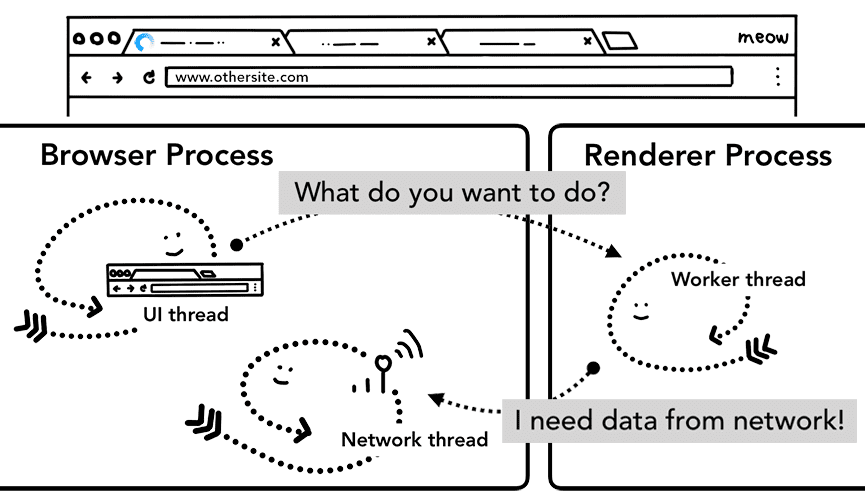
सर्विस वर्कर के मामले में
नेविगेशन की इस प्रोसेस में हाल ही में एक बदलाव किया गया है. इसमें सर्विस वर्क को शामिल किया गया है. सर्विस वर्कर, आपके ऐप्लिकेशन कोड में नेटवर्क प्रॉक्सी लिखने का एक तरीका है. इससे वेब डेवलपर, स्थानीय तौर पर क्या कैश मेमोरी में सेव करना है और नेटवर्क से नया डेटा कब लेना है, इस पर ज़्यादा कंट्रोल कर पाते हैं. अगर सेवा वर्कर को कैश मेमोरी से पेज लोड करने के लिए सेट किया गया है, तो नेटवर्क से डेटा का अनुरोध करने की ज़रूरत नहीं है.
ध्यान रखें कि सेवा वर्कर एक JavaScript कोड है, जो रेंडरर प्रोसेस में चलता है. हालांकि, जब नेविगेशन का अनुरोध आता है, तो ब्राउज़र प्रोसेस को कैसे पता चलता है कि साइट में सर्विस वर्कर्स मौजूद हैं?

जब कोई सेवा वर्कर रजिस्टर किया जाता है, तो सेवा वर्कर के दायरे को रेफ़रंस के तौर पर रखा जाता है (दायरे के बारे में ज़्यादा जानने के लिए, सेवा वर्कर का लाइफ़साइकल लेख पढ़ें). नेविगेशन होने पर, नेटवर्क थ्रेड, रजिस्टर किए गए सर्विस वर्कर के स्कोप के हिसाब से डोमेन की जांच करता है. अगर उस यूआरएल के लिए कोई सर्विस वर्कर रजिस्टर किया गया है, तो यूआई थ्रेड, सर्विस वर्कर कोड को लागू करने के लिए रेंडरर प्रोसेस ढूंढता है. ServiceWorker, कैश मेमोरी से डेटा लोड कर सकता है. इससे नेटवर्क से डेटा का अनुरोध करने की ज़रूरत नहीं पड़ती. इसके अलावा, यह नेटवर्क से नए संसाधनों का अनुरोध भी कर सकता है.
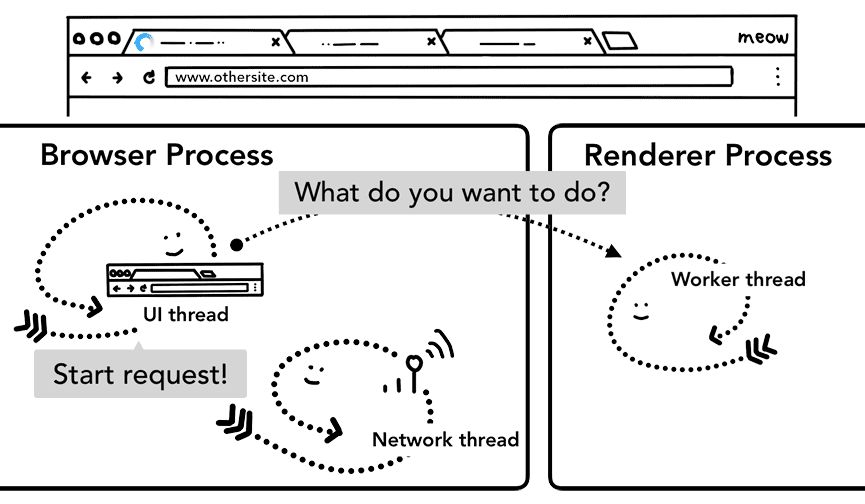
नेविगेशन को पहले से लोड करना
ब्राउज़र प्रोसेस और रेंडरर प्रोसेस के बीच इस राउंड ट्रिप की वजह से देरी हो सकती है. ऐसा तब होगा, जब सेवा वर्कर आखिर में नेटवर्क से डेटा का अनुरोध करेगा. नेविगेशन प्रीलोड एक ऐसा तरीका है जिससे इस प्रोसेस को तेज़ किया जा सकता है. इसके लिए, सेवा वर्कर के स्टार्टअप के साथ-साथ संसाधनों को लोड किया जाता है. यह इन अनुरोधों को हेडर के साथ मार्क करता है, ताकि सर्वर इन अनुरोधों के लिए अलग-अलग कॉन्टेंट भेज सकें. उदाहरण के लिए, पूरे दस्तावेज़ के बजाय सिर्फ़ अपडेट किया गया डेटा.
आखिर में खास जानकारी
इस पोस्ट में, हमने यह देखा कि नेविगेशन के दौरान क्या होता है और आपके वेब ऐप्लिकेशन कोड, जैसे कि रिस्पॉन्स हेडर और क्लाइंट-साइड JavaScript, ब्राउज़र के साथ कैसे इंटरैक्ट करते हैं. नेटवर्क से डेटा पाने के लिए, ब्राउज़र के चरणों को जानने से यह समझना आसान हो जाता है कि नेविगेशन प्रीलोड जैसे एपीआई क्यों डेवलप किए गए थे. अगली पोस्ट में, हम इस बारे में जानेंगे कि पेजों को रेंडर करने के लिए, ब्राउज़र हमारे एचटीएमएल/सीएसएस/JavaScript का आकलन कैसे करता है.
क्या आपको यह पोस्ट पसंद आई? अगर आने वाले समय में पोस्ट के लिए आपका कोई सवाल या सुझाव है, तो हमें बताएं. इसके लिए, नीचे दिए गए टिप्पणी वाले सेक्शन में या Twitter पर @kosamari पर हमसे संपर्क करें.