
O que acontece na navegação
Esta é a segunda parte de uma série de quatro blogs que analisa o funcionamento interno do Chrome. Na postagem anterior, analisamos como diferentes processos e linhas de execução lidam com diferentes partes de um navegador. Nesta postagem, vamos nos aprofundar em como cada processo e encadeamento se comunicam para exibir um site.
Vamos analisar um caso de uso simples de navegação na Web: você digita um URL em um navegador, que busca dados da Internet e exibe uma página. Neste post, vamos nos concentrar na parte em que um usuário solicita um site e o navegador se prepara para renderizar uma página, também conhecida como navegação.
Ele começa com um processo do navegador
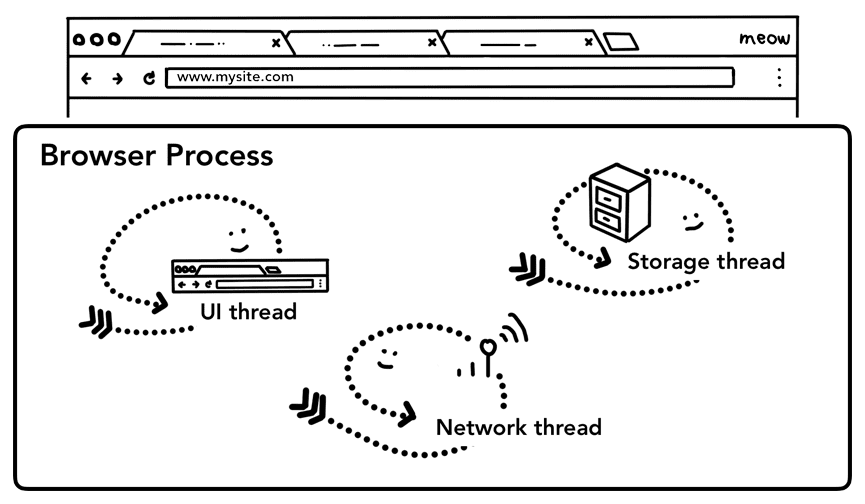
Conforme abordado na parte 1: CPU, GPU, memória e arquitetura multiprocesso, tudo fora de uma guia é processado pelo processo do navegador. O processo do navegador tem linhas de execução, como a linha de execução da interface que desenha botões e campos de entrada do navegador, a linha de execução de rede que lida com a pilha de rede para receber dados da Internet, a linha de execução de armazenamento que controla o acesso aos arquivos e muito mais. Quando você digita um URL na barra de endereço, a entrada é processada pela linha de execução de IU do processo do navegador.
Uma navegação simples
Etapa 1: processar a entrada
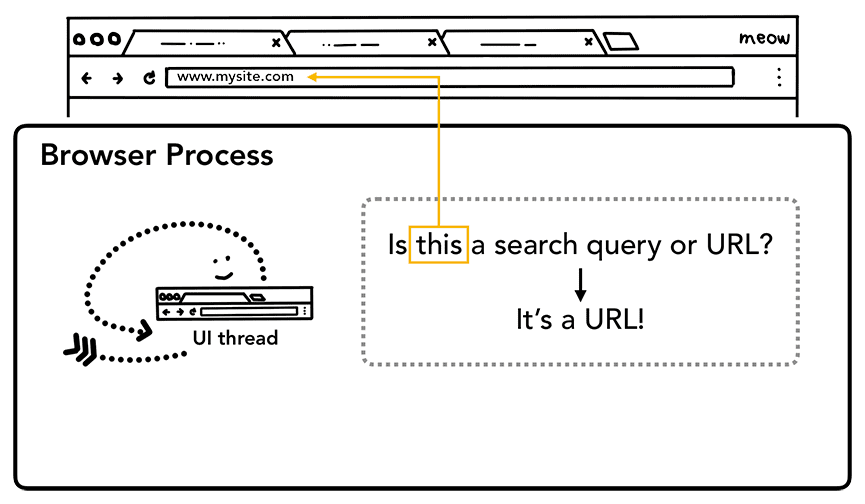
Quando um usuário começa a digitar na barra de endereço, a primeira coisa que a linha de execução da interface pergunta é "Is this a search query or URL?". No Chrome, a barra de endereço também é um campo de entrada de pesquisa. Portanto, a linha de execução da interface precisa analisar e decidir se vai enviar você para um mecanismo de pesquisa ou para o site solicitado.
Etapa 2: iniciar a navegação
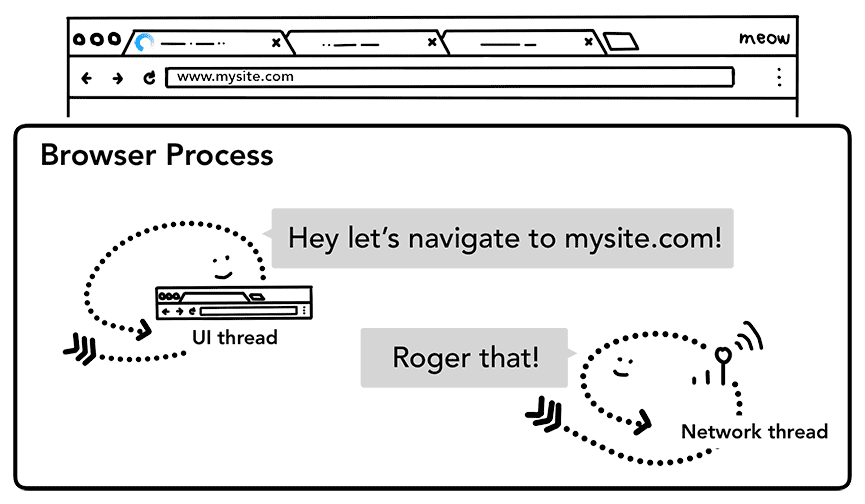
Quando um usuário pressiona a tecla Enter, a linha de execução da interface inicia uma chamada de rede para receber o conteúdo do site. O ícone de carregamento é exibido no canto de uma guia, e a linha de execução de rede passa por protocolos apropriados, como busca DNS e estabelecimento de conexão TLS para a solicitação.
Nesse ponto, a linha de execução de rede pode receber um cabeçalho de redirecionamento do servidor, como HTTP 301. Nesse caso, a linha de execução de rede se comunica com a linha de execução de interface que o servidor está solicitando redirecionamento. Em seguida, outra solicitação de URL será iniciada.
Etapa 3: ler a resposta
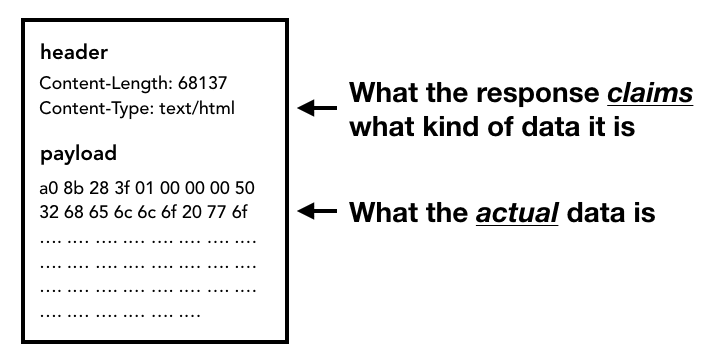
Quando o corpo da resposta (payload) começa a chegar, o segmento de rede verifica os primeiros bytes do fluxo, se necessário. O cabeçalho Content-Type da resposta precisa informar o tipo de dados, mas, como ele pode estar ausente ou incorreto, o sniffing de tipo MIME é feito aqui. Isso é uma "coisa complicada", como comentado no código-fonte. Leia o comentário para saber como diferentes navegadores tratam pares de tipo de conteúdo/payload.
Se a resposta for um arquivo HTML, a próxima etapa será transmitir os dados para o processo de renderização. No entanto, se for um arquivo ZIP ou outro, isso significa que é uma solicitação de download. Portanto, os dados precisam ser transmitidos para o gerenciador de downloads.
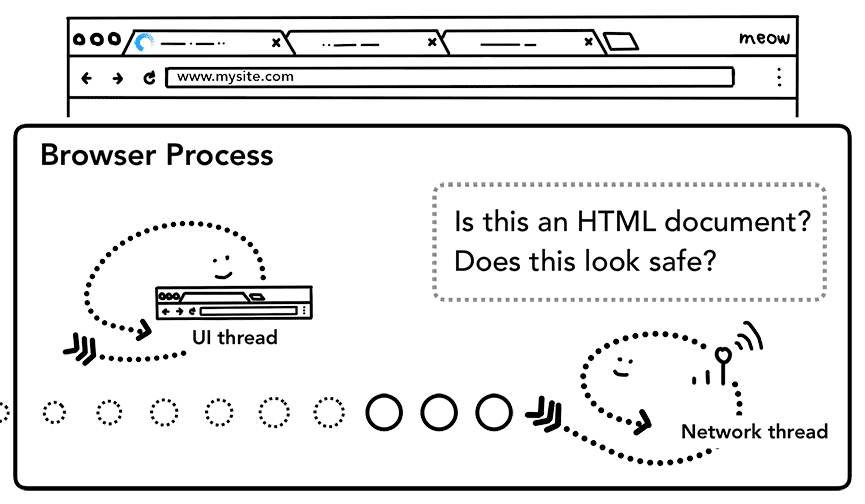
É aqui também que a verificação do SafeBrowsing acontece. Se o domínio e os dados de resposta parecerem corresponder a um site malicioso conhecido, a linha de execução da rede alerta para mostrar uma página de aviso. Além disso, a verificação de Cross Origin Read Blocking (CORB) é feita para garantir que dados sensíveis entre sites não cheguem ao processo de renderização.
Etapa 4: encontrar um processo de renderizador
Depois que todas as verificações forem concluídas e a linha de execução de rede tiver certeza de que o navegador deve navegar para o site solicitado, a linha de execução de rede informa à linha de execução da interface que os dados estão prontos. A linha de execução da interface encontra um processo de renderizador para continuar a renderização da página da Web.
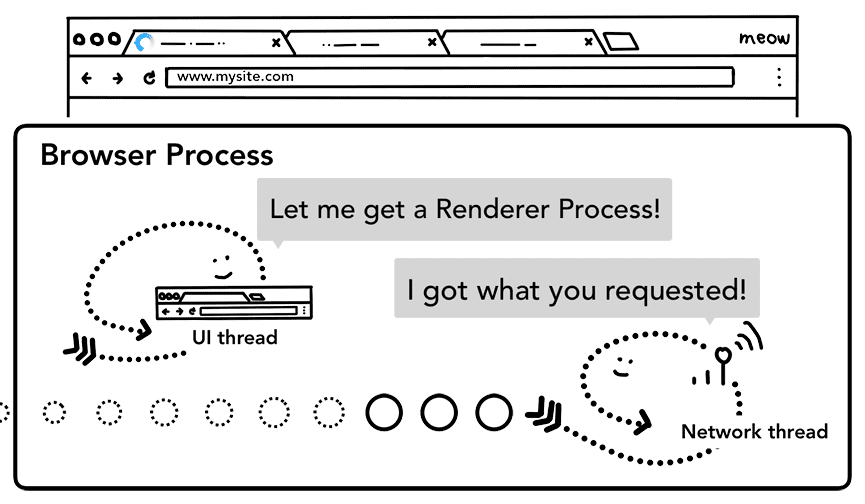
Como a solicitação de rede pode levar várias centenas de milissegundos para receber uma resposta, uma otimização para acelerar esse processo é aplicada. Quando a linha de execução da interface está enviando uma solicitação de URL para a linha de execução de rede na etapa 2, ela já sabe para qual site a navegação está sendo feita. A linha de execução da interface tenta encontrar ou iniciar um processo de renderizador de forma proativa em paralelo à solicitação de rede. Dessa forma, se tudo ocorrer conforme o esperado, um processo de renderizador já estará em modo de espera quando a linha de execução de rede receber dados. Esse processo de espera pode não ser usado se a navegação redirecionar entre sites. Nesse caso, um processo diferente pode ser necessário.
Etapa 5: confirmar a navegação
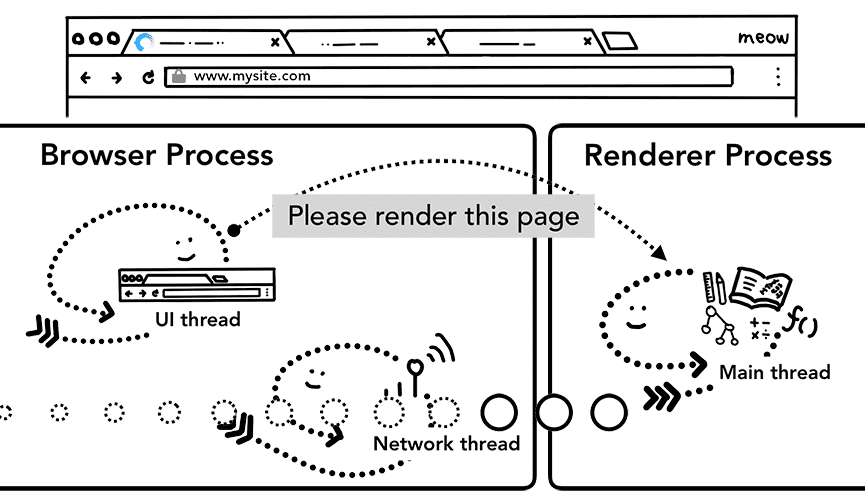
Agora que os dados e o processo de renderização estão prontos, um IPC é enviado do processo do navegador para o processo de renderização para confirmar a navegação. Ele também transmite o fluxo de dados para que o processo de renderização continue recebendo dados HTML. Quando o processo do navegador recebe a confirmação de que o commit aconteceu no processo de renderização, a navegação é concluída e a fase de carregamento do documento começa.
Nesse ponto, a barra de endereço é atualizada, e o indicador de segurança e a interface das configurações do site refletem as informações do site da nova página. O histórico de sessão da guia será atualizado para que os botões "voltar/avançar" acessem o site que acabou de ser acessado. Para facilitar a restauração de guias/sessões ao fechar uma guia ou janela, o histórico de sessões é armazenado no disco.
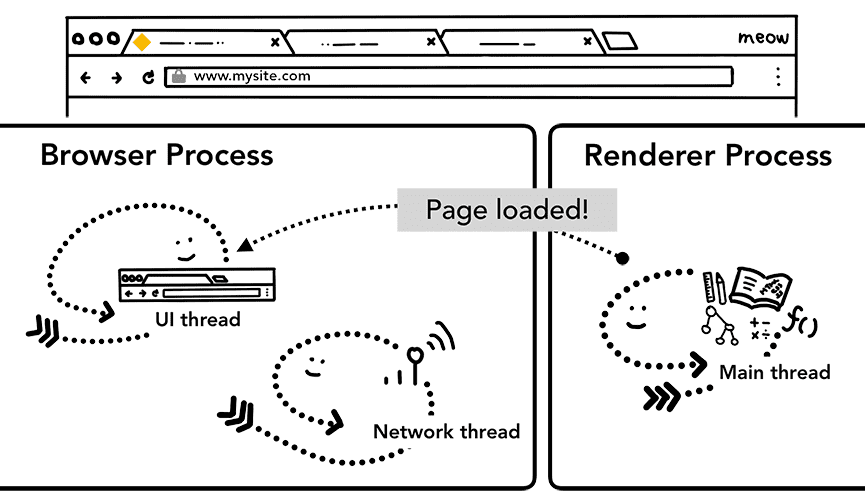
Etapa extra: carregamento inicial concluído
Depois que a navegação é confirmada, o processo de renderização continua carregando recursos e renderiza a
página. Vamos explicar os detalhes do que acontece nessa etapa na próxima postagem. Quando o processo de renderização "termina" a renderização, ele envia um IPC de volta para o processo do navegador (isso acontece depois que todos os
eventos onload são acionados em todos os frames da página e terminam de ser executados). Nesse ponto,
a linha de execução da interface interrompe o ícone de carregamento na guia.
Eu digo "termina" porque o JavaScript do lado do cliente ainda pode carregar recursos adicionais e renderizar novas visualizações depois desse ponto.
Como navegar até outro site
A navegação simples foi concluída. Mas o que acontece se um usuário colocar um URL diferente na barra de endereço
novamente? O processo do navegador passa pelas mesmas etapas para navegar para o site diferente.
Mas, antes disso, é necessário verificar com o site renderizado se ele se importa com o evento
beforeunload.
O beforeunload pode criar o alerta "Sair deste site?" quando você tenta sair ou fechar a guia.
Tudo dentro de uma guia, incluindo o código JavaScript, é processado pelo processo de renderização. Portanto,
o processo do navegador precisa verificar o processo de renderização atual quando uma nova solicitação de navegação chega.
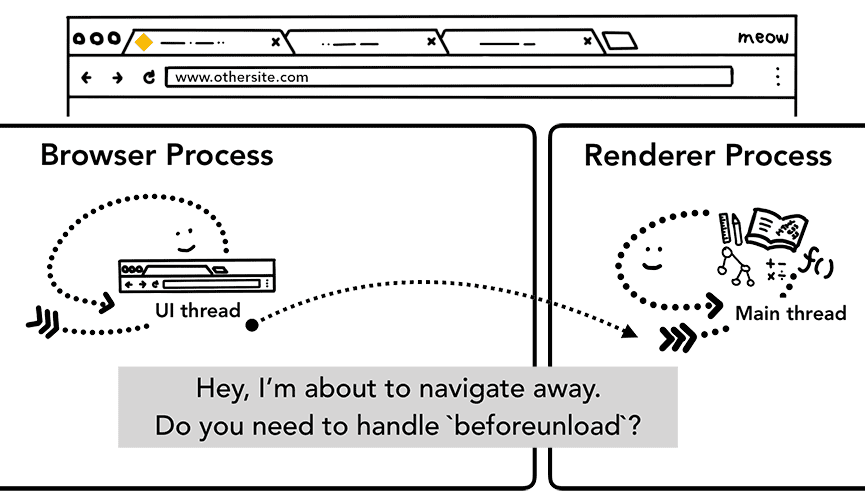
Se a navegação foi iniciada pelo processo do renderizador (como quando o usuário clica em um link ou
o JavaScript do lado do cliente executa window.location = "https://newsite.com"), o processo do renderizador
primeiro verifica os manipuladores beforeunload. Em seguida, ele passa pelo mesmo processo que o processo do navegador
iniciou a navegação. A única diferença é que a solicitação de navegação é iniciada do processo
do renderizador para o processo do navegador.
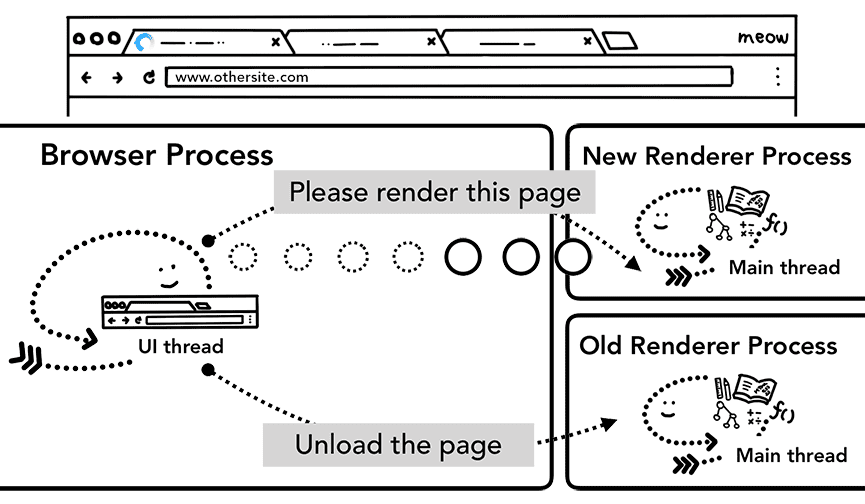
Quando a nova navegação é feita para um site diferente do renderizado atualmente, um processo de renderização
separado é chamado para processar a nova navegação, enquanto o processo de renderização atual é mantido para
processar eventos como unload. Para saber mais, consulte uma visão geral dos estados do ciclo de vida da página
e como conectar eventos com a
API Page Lifecycle.
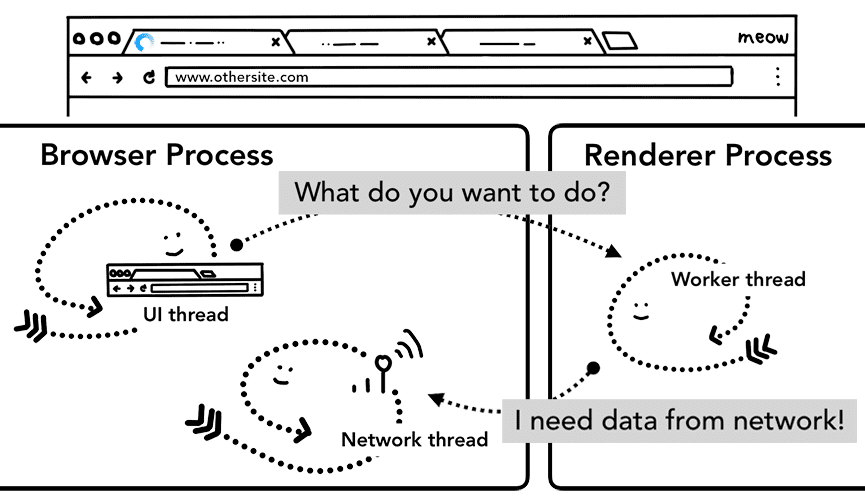
No caso de service worker
Uma mudança recente nesse processo de navegação foi a introdução do service worker. O worker de serviço é uma maneira de escrever proxy de rede no código do aplicativo, permitindo que os desenvolvedores da Web tenham mais controle sobre o que armazenar em cache localmente e quando receber novos dados da rede. Se o service worker estiver configurado para carregar a página do cache, não será necessário solicitar os dados da rede.
O importante é lembrar que o service worker é um código JavaScript executado em um processo de renderização. Mas, quando a solicitação de navegação chega, como um processo do navegador sabe que o site tem um service worker?

Quando um worker de serviço é registrado, o escopo dele é mantido como uma referência. Leia mais sobre o escopo neste artigo O ciclo de vida do worker de serviço. Quando uma navegação acontece, a linha de execução de rede verifica o domínio em relação aos escopos de worker de serviço registrados. Se um worker de serviço estiver registrado para esse URL, a linha de execução da interface vai encontrar um processo de renderizador para executar o código do worker de serviço. O worker de serviço pode carregar dados do cache, eliminando a necessidade de solicitar dados da rede ou pode solicitar novos recursos da rede.
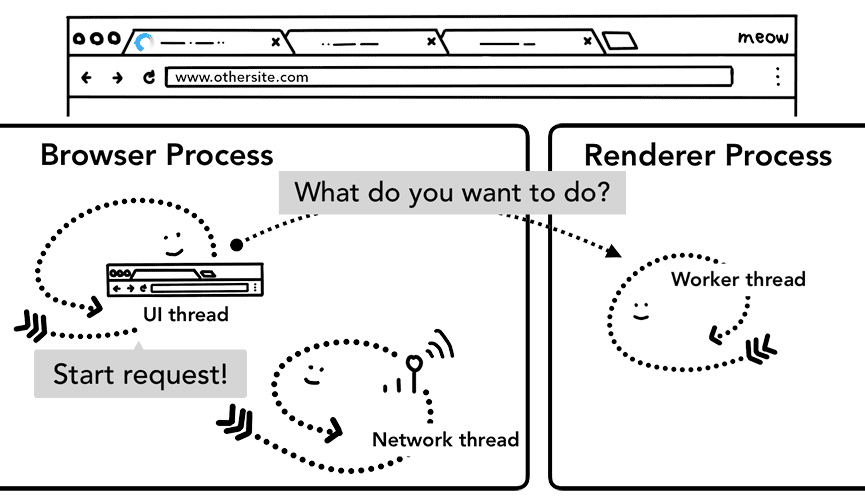
Pré-carregamento de navegação
Essa ida e volta entre o processo do navegador e o processo do renderizador pode resultar em atrasos se o worker de serviço decidir solicitar dados da rede. O pré-carregamento de navegação é um mecanismo para acelerar esse processo carregando recursos em paralelo à inicialização do service worker. Ele marca essas solicitações com um cabeçalho, permitindo que os servidores decidam enviar conteúdo diferente para essas solicitações. Por exemplo, apenas dados atualizados em vez de um documento completo.
Conclusão
Nesta postagem, analisamos o que acontece durante uma navegação e como o código do aplicativo da Web, como cabeçalhos de resposta e JavaScript do lado do cliente, interagem com o navegador. Conhecer as etapas pelas quais o navegador passa para receber dados da rede facilita a compreensão de por que APIs como o pré-carregamento de navegação foram desenvolvidas. No próximo post, vamos explicar como o navegador avalia nosso HTML/CSS/JavaScript para renderizar páginas.
Você gostou da postagem? Se você tiver dúvidas ou sugestões para a próxima postagem, entre em contato comigo na seção de comentários abaixo ou pelo @kosamari no Twitter.