


Tijdens Chrome Dev Summit 2020 hebben we voor het eerst de foutopsporingsondersteuning van Chrome voor WebAssembly-applicaties op internet gedemonstreerd. Sindsdien heeft het team veel energie gestoken in het schaalbaar maken van de ontwikkelaarservaring voor grote en zelfs enorme toepassingen. In dit bericht laten we je de knoppen zien die we hebben toegevoegd (of gemaakt) in de verschillende tools en hoe je ze kunt gebruiken!
Schaalbare foutopsporing
Laten we verdergaan waar we gebleven waren in onze post van 2020. Hier is het voorbeeld waar we toen naar keken:
#include <SDL2/SDL.h>
#include <complex>
int main() {
// Init SDL.
int width = 600, height = 600;
SDL_Init(SDL_INIT_VIDEO);
SDL_Window* window;
SDL_Renderer* renderer;
SDL_CreateWindowAndRenderer(width, height, SDL_WINDOW_OPENGL, &window,
&renderer);
// Generate a palette with random colors.
enum { MAX_ITER_COUNT = 256 };
SDL_Color palette[MAX_ITER_COUNT];
srand(time(0));
for (int i = 0; i < MAX_ITER_COUNT; ++i) {
palette[i] = {
.r = (uint8_t)rand(),
.g = (uint8_t)rand(),
.b = (uint8_t)rand(),
.a = 255,
};
}
// Calculate and draw the Mandelbrot set.
std::complex<double> center(0.5, 0.5);
double scale = 4.0;
for (int y = 0; y < height; y++) {
for (int x = 0; x < width; x++) {
std::complex<double> point((double)x / width, (double)y / height);
std::complex<double> c = (point - center) * scale;
std::complex<double> z(0, 0);
int i = 0;
for (; i < MAX_ITER_COUNT - 1; i++) {
z = z * z + c;
if (abs(z) > 2.0)
break;
}
SDL_Color color = palette[i];
SDL_SetRenderDrawColor(renderer, color.r, color.g, color.b, color.a);
SDL_RenderDrawPoint(renderer, x, y);
}
}
// Render everything we've drawn to the canvas.
SDL_RenderPresent(renderer);
// SDL_Quit();
}
Het is nog steeds een vrij klein voorbeeld en je zult waarschijnlijk niet de echte problemen tegenkomen die je zou zien in een hele grote applicatie, maar we kunnen je nog steeds laten zien wat de nieuwe functies zijn. Het is snel en eenvoudig in te stellen en zelf te proberen!
In het vorige bericht hebben we besproken hoe we dit voorbeeld kunnen compileren en debuggen. Laten we dat nog een keer doen, maar laten we ook een kijkje nemen in de //performance// :
$ emcc -sUSE_SDL=2 -g -O0 -o mandelbrot.html mandelbrot.cc -sALLOW_MEMORY_GROWTH
Deze opdracht produceert een wasm-binair bestand van 3 MB. En het grootste deel daarvan bestaat, zoals je zou verwachten, uit foutopsporingsinformatie. Je kunt dit verifiëren met de llvm-objdump tool [1], bijvoorbeeld:
$ llvm-objdump -h mandelbrot.wasm
mandelbrot.wasm: file format wasm
Sections:
Idx Name Size VMA Type
0 TYPE 0000026f 00000000
1 IMPORT 00001f03 00000000
2 FUNCTION 0000043e 00000000
3 TABLE 00000007 00000000
4 MEMORY 00000007 00000000
5 GLOBAL 00000021 00000000
6 EXPORT 0000014a 00000000
7 ELEM 00000457 00000000
8 CODE 0009308a 00000000 TEXT
9 DATA 0000e4cc 00000000 DATA
10 name 00007e58 00000000
11 .debug_info 000bb1c9 00000000
12 .debug_loc 0009b407 00000000
13 .debug_ranges 0000ad90 00000000
14 .debug_abbrev 000136e8 00000000
15 .debug_line 000bb3ab 00000000
16 .debug_str 000209bd 00000000
Deze uitvoer toont ons alle secties die zich in het gegenereerde wasm-bestand bevinden. De meeste ervan zijn standaard WebAssembly-secties, maar er zijn ook verschillende aangepaste secties waarvan de naam begint met .debug_ . Dat is waar het binaire bestand onze foutopsporingsinformatie bevat! Als we alle formaten bij elkaar optellen, zien we dat debug-informatie ongeveer 2,3 MB van ons bestand van 3 MB uitmaakt. Als we ook het emcc -commando time , zien we dat het op onze machine ongeveer 1,5 seconde duurde om het uit te voeren. Deze cijfers vormen een mooie kleine basislijn, maar ze zijn zo klein dat waarschijnlijk niemand er een oog voor zou hebben. In echte toepassingen kan het debug-binaire bestand echter gemakkelijk een omvang in de GB bereiken en het duurt maar enkele minuten om het te bouwen!
Binaryen overslaan
Bij het bouwen van een wasm-applicatie met Emscripten is een van de laatste bouwstappen het uitvoeren van de Binaryen -optimalisatie. Binaryen is een compilertoolkit die WebAssembly(-achtige) binaire bestanden zowel optimaliseert als legaliseert. Het uitvoeren van Binaryen als onderdeel van de build is vrij duur, maar is alleen onder bepaalde omstandigheden vereist. Voor debug-builds kunnen we de bouwtijd aanzienlijk versnellen als we de noodzaak van Binaryen-passen vermijden. De meest gebruikelijke vereiste Binaryen-pas is voor het legaliseren van functiehandtekeningen met 64-bits gehele waarden. Door u aan te melden voor de WebAssembly BigInt-integratie met -sWASM_BIGINT kunnen we dit voorkomen.
$ emcc -sUSE_SDL=2 -g -O0 -o mandelbrot.html mandelbrot.cc -sALLOW_MEMORY_GROWTH -sWASM_BIGINT -sERROR_ON_WASM_CHANGES_AFTER_LINK
Voor de zekerheid hebben we de vlag -sERROR_ON_WASM_CHANGES_AFTER_LINK ingevoerd. Het helpt detecteren wanneer Binaryen actief is en helpt het binaire bestand onverwachts te herschrijven. Op deze manier kunnen we ervoor zorgen dat we op het snelle pad blijven.
Ook al is ons voorbeeld vrij klein, we kunnen nog steeds het effect zien van het overslaan van Binaryen! Volgens time loopt dit commando net onder de 1s, dus een halve seconde sneller dan voorheen!
Geavanceerde aanpassingen
Scannen van invoerbestanden overslaan
Normaal gesproken scant emcc bij het koppelen van een Emscripten-project alle invoerobjectbestanden en bibliotheken. Het doet dit om nauwkeurige afhankelijkheden tussen JavaScript-bibliotheekfuncties en native symbolen in uw programma te implementeren. Voor grotere projecten kan dit extra scannen van invoerbestanden (met behulp van llvm-nm ) de linktijd aanzienlijk verlengen.
Het is mogelijk om in plaats daarvan uit te voeren met -sREVERSE_DEPS=all , wat emcc vertelt om alle mogelijke native afhankelijkheden van JavaScript-functies op te nemen. Dit heeft een kleine overhead aan code, maar kan de verbindingstijden versnellen en kan nuttig zijn voor debug-builds.
Voor een project zo klein als ons voorbeeld maakt dit geen echt verschil, maar als u honderden of zelfs duizenden objectbestanden in uw project heeft, kan dit de verbindingstijden aanzienlijk verbeteren.
Het gedeelte 'naam' wordt verwijderd
In grote projecten, vooral die met veel C++-sjabloongebruik, kan de sectie 'naam' van WebAssembly erg groot zijn. In ons voorbeeld is het slechts een klein deel van de totale bestandsgrootte (zie de uitvoer van llvm-objdump hierboven), maar in sommige gevallen kan het zeer aanzienlijk zijn. Als de sectie 'naam' van uw toepassing erg groot is en de dwergfoutopsporingsinformatie voldoende is voor uw foutopsporingsbehoeften, kan het voordelig zijn om de sectie 'naam' te verwijderen:
$ emstrip --no-strip-all --remove-section=name mandelbrot.wasm
Hierdoor wordt de sectie "naam" van WebAssembly verwijderd, terwijl de DWARF-foutopsporingssecties behouden blijven.
Debug splijting
Binaire bestanden met veel debug-gegevens zetten niet alleen de bouwtijd onder druk, maar ook de debugging-tijd. De debugger moet de gegevens laden en er een index voor bouwen, zodat deze snel kan reageren op vragen, zoals "Wat is het type van de lokale variabele x?".
Met debug-splitsing kunnen we de debug-informatie voor een binair bestand in twee delen splitsen: een deel dat in het binaire bestand blijft, en een deel dat zich in een afzonderlijk, zogenaamd DWARF-objectbestand ( .dwo ) bevindt. Het kan worden ingeschakeld door de vlag -gsplit-dwarf door te geven aan Emscripten:
$ emcc -sUSE_SDL=2 -g -gsplit-dwarf -gdwarf-5 -O0 -o mandelbrot.html mandelbrot.cc -sALLOW_MEMORY_GROWTH -sWASM_BIGINT -sERROR_ON_WASM_CHANGES_AFTER_LINK
Hieronder laten we de verschillende commando's zien en welke bestanden worden gegenereerd door het compileren zonder debug-gegevens, met debug-gegevens, en ten slotte met zowel debug-gegevens als debug-splitsing.
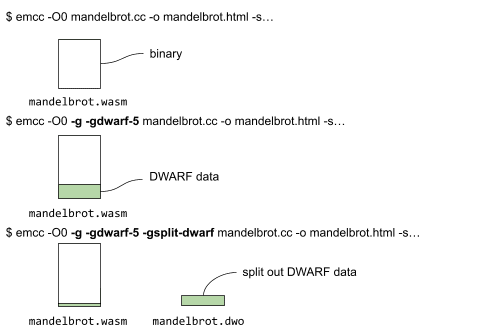
Bij het splitsen van de DWARF-gegevens blijft een deel van de debug-gegevens samen met het binaire bestand, terwijl het grootste deel in het mandelbrot.dwo -bestand wordt geplaatst (zoals hierboven geïllustreerd).
Voor mandelbrot hebben we slechts één bronbestand, maar over het algemeen zijn projecten groter dan dit en bevatten ze meer dan één bestand. Debug fission genereert voor elk van hen een .dwo -bestand. Om ervoor te zorgen dat de huidige bètaversie van de debugger (0.1.6.1615) deze gesplitste debug-informatie kan laden, moeten we deze allemaal bundelen in een zogenaamd DWARF-pakket ( .dwp ) zoals dit:
$ emdwp -e mandelbrot.wasm -o mandelbrot.dwp
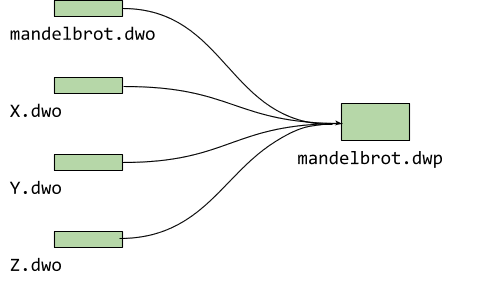
Het opbouwen van het DWARF-pakket uit de afzonderlijke objecten heeft als voordeel dat u slechts één extra bestand hoeft aan te leveren! We werken er momenteel aan om ook alle afzonderlijke objecten in een toekomstige release te laden.
Wat is er met DWARF 5?
Het is je misschien opgevallen dat we een andere vlag in het bovenstaande emcc commando hebben gestopt, -gdwarf-5 . Het inschakelen van versie 5 van de DWARF-symbolen, wat momenteel niet de standaard is, is een andere truc om ons te helpen sneller te gaan debuggen. Hiermee wordt bepaalde informatie opgeslagen in het hoofdbinaire bestand dat de standaardversie 4 heeft weggelaten. Concreet kunnen we de volledige set bronbestanden bepalen, alleen vanuit het hoofdbinaire bestand. Hierdoor kan de debugger basisacties uitvoeren, zoals het weergeven van de volledige bronstructuur en het instellen van breekpunten zonder de volledige symboolgegevens te laden en te parseren. Dit maakt het debuggen met gesplitste symbolen een stuk sneller, dus we gebruiken altijd de opdrachtregelvlaggen -gsplit-dwarf en -gdwarf-5 samen!
Met het DWARF5-foutopsporingsformaat krijgen we ook toegang tot een andere handige functie. Het introduceert een naamindex in de foutopsporingsgegevens die worden gegenereerd bij het doorgeven van de vlag -gpubnames :
$ emcc -sUSE_SDL=2 -g -gdwarf-5 -gsplit-dwarf -gpubnames -O0 -o mandelbrot.html mandelbrot.cc -sALLOW_MEMORY_GROWTH -sWASM_BIGINT -sERROR_ON_WASM_CHANGES_AFTER_LINK
Tijdens een foutopsporingssessie worden symbolen vaak opgezocht door op naam naar een entiteit te zoeken, bijvoorbeeld bij het zoeken naar een variabele of een type. De naamindex versnelt deze zoekopdracht door rechtstreeks te verwijzen naar de compilatie-eenheid die die naam definieert. Zonder een naamindex zou een uitgebreide zoekactie van de volledige foutopsporingsgegevens nodig zijn om de juiste compilatie-eenheid te vinden die de benoemde entiteit definieert waarnaar we op zoek zijn.
Voor de nieuwsgierigen: kijkend naar de foutopsporingsgegevens
U kunt llvm-dwarfdump gebruiken om een kijkje te nemen in de DWARF-gegevens. Laten we dit eens proberen:
llvm-dwarfdump mandelbrot.wasm
Dit geeft ons een overzicht van de “Compile-eenheden” (grofweg de bronbestanden) waarvoor we debug-informatie hebben. In dit voorbeeld hebben we alleen de foutopsporingsinformatie voor mandelbrot.cc . De algemene informatie laat ons weten dat we een skeleton unit hebben, wat alleen maar betekent dat we onvolledige gegevens over dit bestand hebben, en dat er een apart .dwo -bestand is dat de resterende debug-informatie bevat:

Je kunt ook naar andere tabellen in dit bestand kijken, bijvoorbeeld naar de regeltabel die de toewijzing van wasm-bytecode aan C++-regels toont (probeer llvm-dwarfdump -debug-line te gebruiken).
We kunnen ook de foutopsporingsinformatie bekijken die zich in het afzonderlijke .dwo -bestand bevindt:
llvm-dwarfdump mandelbrot.dwo

TL;DR: Wat is het voordeel van het gebruik van debug-splijting?
Er zijn verschillende voordelen verbonden aan het opsplitsen van de debug-informatie als men met grote applicaties werkt:
Sneller koppelen: de linker hoeft niet langer de volledige foutopsporingsinformatie te parseren . Linkers moeten meestal de volledige DWARF-gegevens in het binaire bestand analyseren. Door grote delen van de debug-informatie in afzonderlijke bestanden te verwijderen, kunnen linkers omgaan met kleinere binaire bestanden, wat resulteert in snellere koppelingstijden (vooral waar voor grote applicaties).
Sneller debuggen: De debugger kan het parseren van de extra symbolen in
.dwo/.dwp-bestanden overslaan voor sommige symboolzoekopdrachten . Voor sommige zoekopdrachten (zoals verzoeken voor de lijntoewijzing van wasm-naar-C++-bestanden) hoeven we niet naar de aanvullende foutopsporingsgegevens te kijken. Dit bespaart ons tijd, omdat we de aanvullende foutopsporingsgegevens niet hoeven te laden en te parseren.
1 : Als u geen recente versie van llvm-objdump op uw systeem heeft en u emsdk gebruikt, kunt u deze vinden in de map emsdk/upstream/bin .
Download de voorbeeldkanalen
Overweeg om Chrome Canary , Dev of Beta te gebruiken als uw standaard ontwikkelingsbrowser. Met deze voorbeeldkanalen krijgt u toegang tot de nieuwste DevTools-functies, kunt u geavanceerde webplatform-API's testen en kunt u problemen op uw site opsporen voordat uw gebruikers dat doen!
Neem contact op met het Chrome DevTools-team
Gebruik de volgende opties om de nieuwe functies, updates of iets anders gerelateerd aan DevTools te bespreken.
- Stuur feedback en functieverzoeken naar ons op crbug.com .
- Rapporteer een DevTools-probleem met Meer opties > Help > Rapporteer een DevTools-probleem in DevTools.
- Tweet op @ChromeDevTools .
- Laat reacties achter op Wat is er nieuw in DevTools YouTube-video's of DevTools Tips YouTube-video's .