

En la Chrome Dev Summit 2020, realizamos una demostración de la compatibilidad de Chrome con la depuración para aplicaciones WebAssembly en la Web. Desde entonces, el equipo invirtió una gran cantidad de energía para lograr que la experiencia de los desarrolladores se adapte a aplicaciones grandes y hasta enormes. En esta publicación, te mostraremos los controles que agregamos (o hicimos funcionar) en las diferentes herramientas y cómo usarlas.
Depuración escalable
Retomemos nuestra publicación de 2020 desde donde la dejamos. Este es el ejemplo que estábamos analizando en ese momento:
#include <SDL2/SDL.h>
#include <complex>
int main() {
// Init SDL.
int width = 600, height = 600;
SDL_Init(SDL_INIT_VIDEO);
SDL_Window* window;
SDL_Renderer* renderer;
SDL_CreateWindowAndRenderer(width, height, SDL_WINDOW_OPENGL, &window,
&renderer);
// Generate a palette with random colors.
enum { MAX_ITER_COUNT = 256 };
SDL_Color palette[MAX_ITER_COUNT];
srand(time(0));
for (int i = 0; i < MAX_ITER_COUNT; ++i) {
palette[i] = {
.r = (uint8_t)rand(),
.g = (uint8_t)rand(),
.b = (uint8_t)rand(),
.a = 255,
};
}
// Calculate and draw the Mandelbrot set.
std::complex<double> center(0.5, 0.5);
double scale = 4.0;
for (int y = 0; y < height; y++) {
for (int x = 0; x < width; x++) {
std::complex<double> point((double)x / width, (double)y / height);
std::complex<double> c = (point - center) * scale;
std::complex<double> z(0, 0);
int i = 0;
for (; i < MAX_ITER_COUNT - 1; i++) {
z = z * z + c;
if (abs(z) > 2.0)
break;
}
SDL_Color color = palette[i];
SDL_SetRenderDrawColor(renderer, color.r, color.g, color.b, color.a);
SDL_RenderDrawPoint(renderer, x, y);
}
}
// Render everything we've drawn to the canvas.
SDL_RenderPresent(renderer);
// SDL_Quit();
}
Sigue siendo un ejemplo bastante pequeño, y es probable que no veas ninguno de los problemas reales que verías en una aplicación realmente grande, pero aún podemos mostrarte cuáles son las nuevas funciones. Puedes configurarla y probarla de forma rápida y sencilla.
En la última publicación, analizamos cómo compilar y depurar este ejemplo. Volvamos a hacerlo, pero también analicemos el //performance//
$ emcc -sUSE_SDL=2 -g -O0 -o mandelbrot.html mandelbrot.cc -sALLOW_MEMORY_GROWTH
Este comando produce un objeto binario Wasm de 3 MB. La mayor parte de eso, como puedes esperar, es información de depuración. Puedes verificarlo con la herramienta de llvm-objdump [1], por ejemplo:
$ llvm-objdump -h mandelbrot.wasm
mandelbrot.wasm: file format wasm
Sections:
Idx Name Size VMA Type
0 TYPE 0000026f 00000000
1 IMPORT 00001f03 00000000
2 FUNCTION 0000043e 00000000
3 TABLE 00000007 00000000
4 MEMORY 00000007 00000000
5 GLOBAL 00000021 00000000
6 EXPORT 0000014a 00000000
7 ELEM 00000457 00000000
8 CODE 0009308a 00000000 TEXT
9 DATA 0000e4cc 00000000 DATA
10 name 00007e58 00000000
11 .debug_info 000bb1c9 00000000
12 .debug_loc 0009b407 00000000
13 .debug_ranges 0000ad90 00000000
14 .debug_abbrev 000136e8 00000000
15 .debug_line 000bb3ab 00000000
16 .debug_str 000209bd 00000000
En este resultado, se muestran todas las secciones que están en el archivo wasm generado. La mayoría de ellas son secciones estándar de WebAssembly, pero también hay varias secciones personalizadas cuyo nombre comienza con .debug_. Allí es donde el objeto binario contiene nuestra información de depuración. Si sumamos todos los tamaños, veremos que la información de depuración constituye alrededor de 2.3 MB de nuestro archivo de 3 MB. Si también usamos time para el comando emcc, veremos que, en nuestra máquina, tardó alrededor de 1.5 s en ejecutarse. Estos números constituyen una pequeña referencia, pero son tan pequeños que probablemente nadie los evaluaría. Sin embargo, en aplicaciones reales, el objeto binario de depuración puede alcanzar fácilmente un tamaño en GB y tardar minutos en compilarse.
Se omite Binaryen
Cuando se compila una aplicación de Wasm con Emscripten, uno de los últimos pasos de compilación es ejecutar el optimizador Binaryen. Binaryen es un kit de herramientas de compilación que optimiza y legaliza objetos binarios similares a WebAssembly. La ejecución de Binaryen como parte de la compilación es bastante costosa, pero solo es necesaria en ciertas condiciones. Para compilaciones de depuración, podemos acelerar el tiempo de compilación de manera significativa si evitamos la necesidad de pases de Binaryen. El pase de Binaryen requerido más común es para legalizar firmas de funciones que involucran valores enteros de 64 bits. Si habilitas la integración de WebAssembly BigInt con -sWASM_BIGINT, podemos evitar que suceda.
$ emcc -sUSE_SDL=2 -g -O0 -o mandelbrot.html mandelbrot.cc -sALLOW_MEMORY_GROWTH -sWASM_BIGINT -sERROR_ON_WASM_CHANGES_AFTER_LINK
Agregamos la marca -sERROR_ON_WASM_CHANGES_AFTER_LINK por si acaso. Ayuda a detectar si Binaryen se está ejecutando y vuelve a escribir el objeto binario de forma inesperada. De esta manera, podemos asegurarnos de mantenernos en el camino rápido.
Aunque nuestro ejemplo es bastante pequeño, podemos ver el efecto de omitir Binaryen. Según time, este comando se ejecuta un poco menos de 1 s, por lo que es medio segundo más rápido que antes.
Ajustes avanzados
Cómo omitir el análisis de archivos de entrada
Por lo general, cuando vinculas un proyecto de Emscripten, emcc analizará todos los archivos y bibliotecas de objetos de entrada. Lo hace para implementar dependencias precisas entre las funciones de la biblioteca de JavaScript y los símbolos nativos en tu programa. Para proyectos más grandes, este análisis adicional de los archivos de entrada (con llvm-nm) puede aumentar significativamente el tiempo de vinculación.
En su lugar, se puede ejecutar con -sREVERSE_DEPS=all, que le indica a emcc que incluya todas las dependencias nativas posibles de las funciones de JavaScript. Esto tiene una sobrecarga de tamaño de código pequeña, pero puede acelerar los tiempos de vinculación y puede ser útil para compilaciones de depuración.
Para un proyecto tan pequeño como nuestro ejemplo, esto no hace ninguna diferencia real, pero si tienes cientos o incluso miles de archivos de objetos en tu proyecto, puede mejorar significativamente los tiempos de vinculación.
Quitar la sección "nombre"
En proyectos grandes, especialmente aquellos que usan mucho plantillas de C++, la sección “name” de WebAssembly puede ser muy grande. En nuestro ejemplo, es solo una pequeña fracción del tamaño total del archivo (consulta el resultado de llvm-objdump más arriba), pero en algunos casos puede ser muy importante. Si la sección de “nombre” de tu aplicación es muy grande y la información de depuración de dwarf es suficiente para tus necesidades de depuración, puede ser beneficioso quitar la sección de “nombre”:
$ emstrip --no-strip-all --remove-section=name mandelbrot.wasm
Esto quitará la sección de “nombre” de WebAssembly y conservará las secciones de depuración de DWARF.
Fisión de depuración
Los objetos binarios con muchos datos de depuración no solo presionan el tiempo de compilación, sino también el de depuración. El depurador debe cargar los datos y debe compilar un índice para ellos de modo que pueda responder rápidamente a consultas, como “¿Cuál es el tipo de la variable local x?”.
La fisión de depuración nos permite dividir la información de depuración de un objeto binario en dos partes: una que permanece en el objeto binario y otra que está incluida en un archivo de objeto DWARF (.dwo) separado. Se puede habilitar si pasas la marca -gsplit-dwarf a Emscripten:
$ emcc -sUSE_SDL=2 -g -gsplit-dwarf -gdwarf-5 -O0 -o mandelbrot.html mandelbrot.cc -sALLOW_MEMORY_GROWTH -sWASM_BIGINT -sERROR_ON_WASM_CHANGES_AFTER_LINK
A continuación, mostramos los diferentes comandos y los archivos que se generan mediante la compilación sin datos de depuración, con datos de depuración y, por último, con datos de depuración y fisión de depuración.
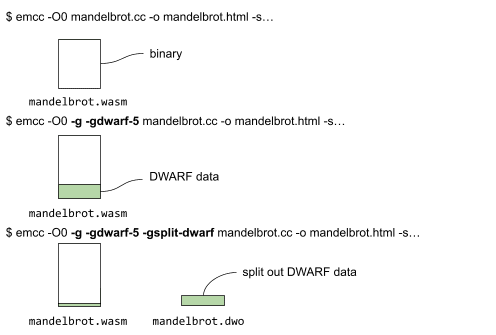
Cuando se dividen los datos de DWARF, una parte de los datos de depuración reside junto con el objeto binario, mientras que la parte grande se coloca en el archivo mandelbrot.dwo (como se ilustra más arriba).
Para mandelbrot, solo tenemos un archivo de origen, pero, por lo general, los proyectos son más grandes que este archivo y, además, incluyen más de un archivo. La fisión de depuración genera un archivo .dwo para cada uno de ellos. Para que la versión beta actual del depurador (0.1.6.1615) pueda cargar esta información de depuración dividida, debemos agruparlas en un paquete llamado DWARF (.dwp) de la siguiente manera:
$ emdwp -e mandelbrot.wasm -o mandelbrot.dwp
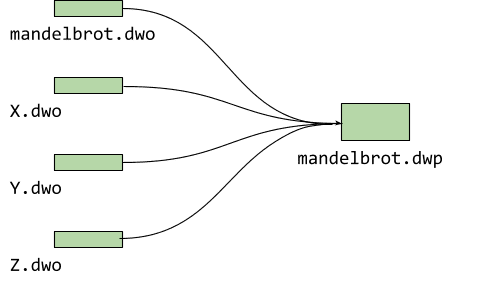
Compilar el paquete DWARF a partir de objetos individuales tiene la ventaja de que solo necesitas entregar un archivo adicional. Actualmente, estamos trabajando para cargar todos los objetos individuales en una versión futura.
¿Qué significa DWARF 5?
Es posible que hayas notado que agregamos otra marca al comando emcc de arriba, -gdwarf-5. Habilitar la versión 5 de los símbolos DWARF (que actualmente no es la opción predeterminada) es otro truco para ayudarnos a comenzar la depuración más rápido. Con él, se almacena cierta información en el objeto binario principal que la versión 4 predeterminada no la incluyó. Específicamente, podemos determinar el conjunto completo de archivos de origen solo a partir del objeto binario principal. De esta manera, el depurador puede realizar acciones básicas, como mostrar el árbol de fuentes completo y establecer puntos de interrupción, sin cargar ni analizar los datos de símbolos completos. Esto hace que la depuración con símbolos divididos sea mucho más rápida, por lo que siempre usamos las marcas de línea de comandos -gsplit-dwarf y -gdwarf-5 juntas.
Con el formato de depuración DWARF5, también tenemos acceso a otra función útil. Introduce un índice de nombres en los datos de depuración que se generarán cuando se pase la marca -gpubnames:
$ emcc -sUSE_SDL=2 -g -gdwarf-5 -gsplit-dwarf -gpubnames -O0 -o mandelbrot.html mandelbrot.cc -sALLOW_MEMORY_GROWTH -sWASM_BIGINT -sERROR_ON_WASM_CHANGES_AFTER_LINK
Durante una sesión de depuración, las búsquedas de símbolos suelen realizarse a través de la búsqueda de una entidad por nombre (p.ej., cuando se busca una variable o un tipo). El índice de nombres acelera esta búsqueda, ya que apunta directamente a la unidad de compilación que define ese nombre. Sin un índice de nombres, se requeriría una búsqueda exhaustiva de todos los datos de depuración para encontrar la unidad de compilación correcta que defina la entidad con nombre que estamos buscando.
Para los curiosos: Cómo ver los datos de depuración
Puedes usar llvm-dwarfdump para obtener una vista de los datos de DWARF. Probemos esto:
llvm-dwarfdump mandelbrot.wasm
Esto nos da una descripción general de las "unidades de compilación" (a grandes rasgos, los archivos de origen) para las que tenemos información de depuración. En este ejemplo, solo tenemos la información de depuración de mandelbrot.cc. La información general nos indicará que tenemos una unidad básica, lo que solo significa que tenemos datos incompletos en este archivo y que hay un archivo .dwo independiente que contiene la información de depuración restante:

También puedes consultar otras tablas dentro de este archivo, p.ej., la tabla de líneas que muestra la asignación del código de bytes de Wasm a las líneas de C++ (intenta usar llvm-dwarfdump -debug-line).
También podemos echar un vistazo a la información de depuración que se encuentra en el archivo .dwo independiente:
llvm-dwarfdump mandelbrot.dwo

Resumen: ¿Cuál es la ventaja de usar la fisión de depuración?
Existen varias ventajas en dividir la información de depuración si se trabaja con aplicaciones grandes:
Vinculación más rápida: El vinculador ya no necesita analizar toda la información de depuración. Por lo general, los vinculadores deben analizar todos los datos de DWARF del objeto binario. Al extraer grandes partes de la información de depuración en archivos separados, los vinculadores se ocupan de objetos binarios más pequeños, lo que resulta en tiempos de vinculación más rápidos (especialmente en el caso de las aplicaciones grandes).
Depuración más rápida: El depurador puede omitir el análisis de los símbolos adicionales en los archivos
.dwo/.dwppara algunas búsquedas de símbolos. Para algunas búsquedas (como las solicitudes en la asignación de líneas de archivos wasm a C++), no es necesario que examinemos los datos de depuración adicionales. Esto nos ahorra tiempo, ya que no necesitamos cargar y analizar los datos de depuración adicionales.
1: Si no tienes una versión reciente de llvm-objdump en tu sistema y usas emsdk, la encontrarás en el directorio emsdk/upstream/bin.
Descarga los canales de vista previa
Considera usar Canary, Dev o Beta de Chrome como tu navegador de desarrollo predeterminado. Estos canales de vista previa te brindan acceso a las funciones más recientes de Herramientas para desarrolladores, prueba APIs de plataformas web de vanguardia y encuentra problemas en tu sitio antes que tus usuarios.
Cómo comunicarse con el equipo de Herramientas para desarrolladores de Chrome
Usa las siguientes opciones para analizar las nuevas funciones y los cambios en la publicación, o cualquier otra cosa relacionada con Herramientas para desarrolladores.
- Envíanos tus sugerencias o comentarios a través de crbug.com.
- Informa un problema en Herramientas para desarrolladores mediante Más opciones
 > Ayuda > Informar problemas con Herramientas para desarrolladores en Herramientas para desarrolladores.
> Ayuda > Informar problemas con Herramientas para desarrolladores en Herramientas para desarrolladores. - Envía un tweet a @ChromeDevTools.
- Deja comentarios en los videos de YouTube de las Novedades de las Herramientas para desarrolladores o en las sugerencias de Herramientas para desarrolladores (videos de YouTube).