


Podczas Chrome Dev Summit 2020 po raz pierwszy zaprezentowaliśmy w internecie obsługę debugowania aplikacji WebAssembly w Chrome. Od tego czasu zespół włożył wiele wysiłku w zapewnienie deweloperom możliwości tworzenia dużych, a nawet bardzo dużych aplikacji. W tym poście pokażemy Ci pokrętła, które dodaliśmy (lub które działają) w różnych narzędziach, oraz jak z nich korzystać.
Skalowalne debugowanie
Zacznijmy tam, gdzie skończyliśmy w 2020 r. Oto przykład, który analizowaliśmy w tamtym czasie:
#include <SDL2/SDL.h>
#include <complex>
int main() {
// Init SDL.
int width = 600, height = 600;
SDL_Init(SDL_INIT_VIDEO);
SDL_Window* window;
SDL_Renderer* renderer;
SDL_CreateWindowAndRenderer(width, height, SDL_WINDOW_OPENGL, &window,
&renderer);
// Generate a palette with random colors.
enum { MAX_ITER_COUNT = 256 };
SDL_Color palette[MAX_ITER_COUNT];
srand(time(0));
for (int i = 0; i < MAX_ITER_COUNT; ++i) {
palette[i] = {
.r = (uint8_t)rand(),
.g = (uint8_t)rand(),
.b = (uint8_t)rand(),
.a = 255,
};
}
// Calculate and draw the Mandelbrot set.
std::complex<double> center(0.5, 0.5);
double scale = 4.0;
for (int y = 0; y < height; y++) {
for (int x = 0; x < width; x++) {
std::complex<double> point((double)x / width, (double)y / height);
std::complex<double> c = (point - center) * scale;
std::complex<double> z(0, 0);
int i = 0;
for (; i < MAX_ITER_COUNT - 1; i++) {
z = z * z + c;
if (abs(z) > 2.0)
break;
}
SDL_Color color = palette[i];
SDL_SetRenderDrawColor(renderer, color.r, color.g, color.b, color.a);
SDL_RenderDrawPoint(renderer, x, y);
}
}
// Render everything we've drawn to the canvas.
SDL_RenderPresent(renderer);
// SDL_Quit();
}
To nadal dość mały przykład, więc prawdopodobnie nie zobaczysz żadnych rzeczywistych problemów, które występują w naprawdę dużych aplikacjach, ale możemy Ci pokazać nowe funkcje. Konfiguracja i testowanie tej funkcji jest szybkie i łatwe.
W poprzednim poście omawialiśmy kompilowanie i debugowanie tego przykładu. Spróbujmy jeszcze raz, ale tym razem zerknijmy też na //performance//:
$ emcc -sUSE_SDL=2 -g -O0 -o mandelbrot.html mandelbrot.cc -sALLOW_MEMORY_GROWTH
To polecenie wygeneruje plik binarny wasm o rozmiary 3 MB. Jak można się spodziewać, większość z nich to informacje debugujące. Możesz to sprawdzić za pomocą narzędzia llvm-objdump [1], np.:
$ llvm-objdump -h mandelbrot.wasm
mandelbrot.wasm: file format wasm
Sections:
Idx Name Size VMA Type
0 TYPE 0000026f 00000000
1 IMPORT 00001f03 00000000
2 FUNCTION 0000043e 00000000
3 TABLE 00000007 00000000
4 MEMORY 00000007 00000000
5 GLOBAL 00000021 00000000
6 EXPORT 0000014a 00000000
7 ELEM 00000457 00000000
8 CODE 0009308a 00000000 TEXT
9 DATA 0000e4cc 00000000 DATA
10 name 00007e58 00000000
11 .debug_info 000bb1c9 00000000
12 .debug_loc 0009b407 00000000
13 .debug_ranges 0000ad90 00000000
14 .debug_abbrev 000136e8 00000000
15 .debug_line 000bb3ab 00000000
16 .debug_str 000209bd 00000000
Wyjście zawiera wszystkie sekcje w wygenerowanym pliku wasm. Większość z nich to standardowe sekcje WebAssembly, ale jest też kilka niestandardowych sekcji, których nazwa zaczyna się od .debug_. To właśnie zawiera informacje debugowania. Jeśli zsumujemy wszystkie rozmiary, okaże się, że informacje debugowania zajmują około 2,3 MB z 3 MB pliku. Jeśli time polecenie emcc, widzimy, że na naszym komputerze zajęło to około 1,5 s. Te liczby stanowią dobrą podstawę, ale są tak małe, że nikt nie zwróci na nie uwagi. W rzeczywistych aplikacjach pliki binarne debugowania mogą osiągnąć rozmiar rzędu GB i tworzyć się przez kilka minut.
Pomijanie Binaryen
Podczas kompilowania aplikacji wasm za pomocą Emscripten jeden z końcowych kroków kompilacji to uruchomienie optymalizatora Binaryen. Binaryen to zestaw narzędzi kompilatora, który optymalizuje i legalizuje pliki binarne WebAssembly. Uruchomienie Binaryen w ramach kompilacji jest dość kosztowne, ale jest wymagane tylko w określonych warunkach. W przypadku kompilacji debugujących możemy znacznie przyspieszyć czas kompilacji, jeśli nie będziemy musieli uruchamiać Binaryen. Najczęściej wymagane jest przepuszczenie Binaryen w celu legalizacji podpisów funkcji z użyciem 64-bitowych wartości całkowitych. Aby tego uniknąć, możesz włączyć integrację BigInt w WebAssembly za pomocą -sWASM_BIGINT.
$ emcc -sUSE_SDL=2 -g -O0 -o mandelbrot.html mandelbrot.cc -sALLOW_MEMORY_GROWTH -sWASM_BIGINT -sERROR_ON_WASM_CHANGES_AFTER_LINK
Dla pewności dodaliśmy flagę -sERROR_ON_WASM_CHANGES_AFTER_LINK. Pomaga wykryć, kiedy Binaryen jest uruchomiony i nieoczekiwanie przepisuje plik binarny. Dzięki temu możemy mieć pewność, że trzymamy się ścieżki szybkiego działania.
Mimo że nasz przykład jest dość mały, widać wyraźnie efekt pominięcia Binaryen. Według time to polecenie wykonuje się w niecałą 1 s, czyli o pół sekundy szybciej niż wcześniej.
Zaawansowane ustawienia
Pomijanie skanowania pliku wejściowego
Zazwyczaj podczas łączenia projektu Emscripten emcc skanuje wszystkie pliki obiektów wejściowych i biblioteki. Robi to, aby zaimplementować dokładne zależności między funkcjami biblioteki JavaScript a wbudowanymi symbolami w programie. W przypadku większych projektów dodatkowe skanowanie plików wejściowych (za pomocą llvm-nm) może znacznie wydłużyć czas łączenia.
Zamiast tego można użyć opcji -sREVERSE_DEPS=all, która mówi emcc, aby uwzględnić wszystkie możliwe natywne zależności funkcji JavaScript. Ma to niewielki wpływ na rozmiar kodu, ale może przyspieszyć czas tworzenia linków i przydać się w przypadku wersji debugowania.
W przypadku tak małego projektu jak nasz przykład nie ma to większego znaczenia, ale jeśli masz w projekcie setki lub nawet tysiące plików obiektów, może to znacznie skrócić czas łączenia.
Usuwanie sekcji „name”
W dużych projektach, zwłaszcza tych, w których używa się wielu szablonów C++, sekcja „name” (nazwa) WebAssembly może być bardzo duża. W naszym przykładzie jest to tylko niewielka część całkowitego rozmiaru pliku (patrz dane wyjściowe funkcji llvm-objdump powyżej), ale w niektórych przypadkach może być to bardzo dużo. Jeśli sekcja „name” w aplikacji jest bardzo duża, a informacje debugowania w formacie DWARF wystarczają do debugowania, warto usunąć sekcję „name”:
$ emstrip --no-strip-all --remove-section=name mandelbrot.wasm
Spowoduje to usunięcie sekcji „name” (nazwa) WebAssembly, przy zachowaniu sekcji debugowania DWARF.
Debugowanie funkcji fission
Pliki binarne z dużą ilością danych debugowania nie tylko wydłużają czas kompilacji, ale też czas debugowania. Debuger musi wczytać dane i tworzyć dla nich indeks, aby mógł szybko odpowiadać na zapytania, np. „Jaki jest typ zmiennej lokalnej x?”.
Debug fission umożliwia podzielenie informacji debugowania binarnego na 2 części: jedną, która pozostaje w binarnym, i drugą, która jest zawarta w oddzielnym pliku obiektu DWARF (.dwo). Można go włączyć, przekazując flagę -gsplit-dwarf do Emscripten:
$ emcc -sUSE_SDL=2 -g -gsplit-dwarf -gdwarf-5 -O0 -o mandelbrot.html mandelbrot.cc -sALLOW_MEMORY_GROWTH -sWASM_BIGINT -sERROR_ON_WASM_CHANGES_AFTER_LINK
Poniżej przedstawiamy różne polecenia i pliki wygenerowane przez kompilację bez danych debugowania, z danymi debugowania i ostatecznie z danymi debugowania i debugowaniem fission.
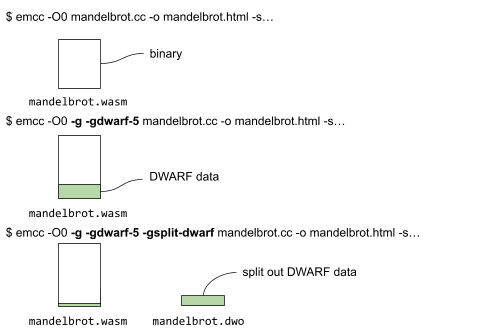
Podczas dzielenia danych DWARF część danych debugowania jest przechowywana razem z plikiem binarnym, a większa część trafia do pliku mandelbrot.dwo (jak pokazano powyżej).
W przypadku mandelbrot mamy tylko 1 plik źródłowy, ale zazwyczaj projekty są większe i zawierają więcej niż 1 plik. Debugowanie podziału generuje plik .dwo dla każdego z nich. Aby bieżąca wersja beta debugera (0.1.6.1615) mogła wczytać te podzielone informacje debugowania, musimy umieścić je w tak zwanym pakiecie DWARF (.dwp), który wygląda tak:
$ emdwp -e mandelbrot.wasm -o mandelbrot.dwp
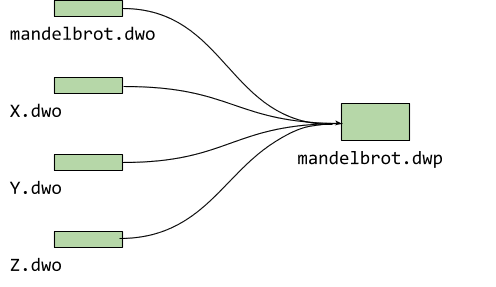
Budowanie pakietu DWARF z pojedynczych obiektów ma tę zaletę, że wystarczy przesłać tylko jeden dodatkowy plik. Obecnie pracujemy nad załadowaniem wszystkich poszczególnych obiektów w przyszłej wersji.
Co się dzieje z DWARF 5?
Jak pewnie zauważyłeś(-aś), w powyższym poleceniu emcc dodaliśmy jeszcze jedną flagę, -gdwarf-5. Włączenie wersji 5 symboli DWARF, która obecnie nie jest domyślna, to kolejny sposób na szybsze debugowanie. Dzięki temu niektóre informacje są przechowywane w głównym pliku binarnym, który nie był uwzględniany w domyślnej wersji 4. Konkretnie możemy określić pełny zestaw plików źródłowych tylko na podstawie głównego pliku binarnego. Dzięki temu debuger może wykonywać podstawowe czynności, takie jak wyświetlanie pełnego drzewa źródłowego i ustawianie punktów przerwania, bez wczytywania i analizowania pełnych danych symboli. Dzięki temu debugowanie z użyciem podzielonych symboli jest znacznie szybsze, dlatego zawsze używamy flag wiersza poleceń -gsplit-dwarf i -gdwarf-5 razem.
Format debugowania DWARF5 umożliwia też dostęp do innej przydatnej funkcji. Wprowadza on indeks nazw w danych debugowania, które zostaną wygenerowane po przekazaniu flagi -gpubnames:
$ emcc -sUSE_SDL=2 -g -gdwarf-5 -gsplit-dwarf -gpubnames -O0 -o mandelbrot.html mandelbrot.cc -sALLOW_MEMORY_GROWTH -sWASM_BIGINT -sERROR_ON_WASM_CHANGES_AFTER_LINK
Podczas sesji debugowania wyszukiwanie symboli często odbywa się przez wyszukiwanie elementu według nazwy, np. podczas wyszukiwania zmiennej lub typu. Indeks nazw przyspiesza to wyszukiwanie, wskazując bezpośrednio jednostkę kompilacji, która definiuje tę nazwę. Bez indeksu nazw konieczne byłoby wyczerpujące przeszukanie wszystkich danych debugowania w celu znalezienia odpowiedniej jednostki kompilacji, która definiuje poszukiwany przez nas element o nazwie.
Dla ciekawskich: sprawdzanie danych debugowania
Aby podejrzeć dane DWARF, możesz użyć llvm-dwarfdump. Spróbujmy:
llvm-dwarfdump mandelbrot.wasm
Dzięki temu mamy przegląd „jednostek kompilacji” (czyli w przybliżeniu plików źródłowych), dla których mamy informacje debugowania. W tym przykładzie mamy tylko informacje o debugowaniu dotyczące mandelbrot.cc. Informacje ogólne poinformują nas, że mamy szkieletową jednostkę, co oznacza, że mamy niekompletne dane w tym pliku i że istnieje oddzielny plik .dwo, który zawiera pozostałe informacje debugowania:

Możesz też spojrzeć na inne tabele w tym pliku, np. na tabelę wierszy, która pokazuje mapowanie kodu bajtowego wasm na wiersze C++ (spróbuj użyć llvm-dwarfdump -debug-line).
Możemy też sprawdzić informacje debugowania zawarte w osobnym pliku .dwo:
llvm-dwarfdump mandelbrot.dwo

TL;DR: Jaka jest zaleta korzystania z debugowania w procesie podziału?
Podzielenie informacji debugowania na kilka części ma kilka zalet, jeśli pracujesz z dużymi aplikacjami:
Szybsze łączenie: kompilator nie musi już analizować wszystkich informacji debugowania. Linkery muszą zwykle przeanalizować wszystkie dane DWARF zawarte w pliku binarnym. Dzięki wyodrębnianiu dużych części informacji debugujących w osobnych plikach linkery mają do czynienia z mniejszymi plikami binarnymi, co przekłada się na krótszy czas łączenia (szczególnie w przypadku dużych aplikacji).
Szybsze debugowanie: w przypadku niektórych wyszukiwań symboli debugger może pominąć analizowanie dodatkowych symboli w plikach
.dwo/.dwp. W przypadku niektórych wyszukiwań (np. żądań mapowania linii w plikach wasm-to-C++) nie musimy sprawdzać dodatkowych danych debugowania. Dzięki temu oszczędzamy czas, ponieważ nie musimy wczytywać i analizować dodatkowych danych debugowania.
1: jeśli w systemie nie masz najnowszej wersji llvm-objdump i korzystasz z emsdk, możesz ją znaleźć w katalogu emsdk/upstream/bin.
Pobieranie kanałów podglądu
Rozważ użycie jako domyślnej przeglądarki deweloperskiej przeglądarki Chrome w wersji Canary, Dev lub Beta. Te kanały wersji wstępnej zapewniają dostęp do najnowszych funkcji DevTools, umożliwiają testowanie najnowocześniejszych interfejsów API platformy internetowej i pomagają znaleźć problemy w witrynie, zanim zrobią to użytkownicy.
Kontakt z zespołem Narzędzi deweloperskich w Chrome
Aby omówić nowe funkcje, aktualizacje lub inne kwestie związane z Narzędziami deweloperskimi, skorzystaj z tych opcji.
- Przesyłaj opinie i prośby o dodanie funkcji na stronie crbug.com.
- Zgłoś problem z Narzędziami deweloperskimi, klikając Więcej opcji > Pomoc > Zgłoś problem z Narzędziami deweloperskimi w Narzędziach deweloperskich.
- Wyślij tweeta do @ChromeDevTools.
- Dodaj komentarze do filmów w YouTube z serii „Co nowego w Narzędziach deweloperskich” lub Wskazówki dotyczące Narzędzi deweloperskich.