

Vamos falar sobre... arquitetura?
Vou abordar um tema importante, mas que pode ser mal compreendido: a arquitetura usada para seu web app e, especificamente, como as decisões arquitetônicas entram em jogo ao criar um web app progressivo.
"Arquitetura" pode parecer vago, e talvez não fique claro imediatamente por que isso é importante. Uma maneira de pensar na arquitetura é fazer as seguintes perguntas: quando um usuário visita uma página no meu site, qual HTML é carregado? E o que é carregado quando eles visitam outra página?
As respostas a essas perguntas nem sempre são simples, e quando você começa a pensar em apps da Web progressivos, elas podem ficar ainda mais complicadas. Então, minha meta é mostrar uma arquitetura possível que achei eficaz. Ao longo deste artigo, vou rotular as decisões que tomei como "minha abordagem" para criar um app Web progressivo.
Você pode usar minha abordagem ao criar seu próprio PWA, mas sempre há outras alternativas válidas. Espero que ver como todas as peças se encaixam inspire você e que você se sinta à vontade para personalizar isso de acordo com suas necessidades.
PWA do Stack Overflow
Para acompanhar este artigo, criei um PWA do Stack Overflow. Passo muito tempo lendo e contribuindo para o Stack Overflow, e queria criar um app da Web que facilitasse a navegação pelas perguntas frequentes sobre um determinado assunto. Ela é criada com base na API Stack Exchange pública. Ele é de código aberto, e você pode saber mais acessando o projeto no GitHub.
Apps de várias páginas (MPAs)
Antes de entrar em detalhes, vamos definir alguns termos e explicar partes da tecnologia subjacente. Primeiro, vou falar sobre o que gosto de chamar de "apps de várias páginas" ou "MPAs".
MPA é um nome sofisticado para a arquitetura tradicional usada desde o início da Web. Cada vez que um usuário navega para um novo URL, o navegador renderiza progressivamente o HTML específico dessa página. Não há tentativa de preservar o estado da página ou o conteúdo entre as navegações. Cada vez que você visita uma nova página, você começa do zero.
Isso contrasta com o modelo de aplicativo de página única (SPA) para criar apps da Web, em que o navegador executa o código JavaScript para atualizar a página atual quando o usuário visita uma nova seção. SPAs e MPAs são modelos igualmente válidos para uso, mas, neste post, quis explorar conceitos de PWA no contexto de um app de várias páginas.
Rápido e confiável
Você já me ouviu (e muitas outras pessoas) usar a frase "progressive web app", ou PWA. Você já deve conhecer alguns dos materiais de apoio em outras partes deste site.
Um PWA é um app da Web que oferece uma experiência de usuário de primeira classe e que realmente merece um lugar na tela inicial do usuário. A sigla FIRE (em inglês), que significa Rápido, Integrado, Confiável e Envolvente, resume todos os atributos a serem considerados ao criar um PWA.
Neste artigo, vou me concentrar em um subconjunto desses atributos: Rápido e Confiável.
Rápido:embora "rápido" tenha significados diferentes em contextos diferentes, vou abordar os benefícios de velocidade de carregar o mínimo possível da rede.
Confiável:mas a velocidade bruta não é suficiente. Para parecer um PWA, seu app da Web precisa ser confiável. Ele precisa ser resiliente o suficiente para sempre carregar algo, mesmo que seja apenas uma página de erro personalizada, independente do estado da rede.
Confiável e rápido:por fim, vou reformular um pouco a definição de PWA e analisar o que significa criar algo que seja confiável e rápido. Não basta ser rápido e confiável apenas quando você está em uma rede de baixa latência. Ser consistentemente rápido significa que a velocidade do seu app da Web é constante, independentemente das condições de rede subjacentes.
Tecnologias de ativação: service workers e API Cache Storage
Os PWAs estabelecem um alto padrão de velocidade e resiliência. Felizmente, a plataforma da Web oferece alguns blocos de construção para tornar esse tipo de performance uma realidade. Estou me referindo aos service workers e à API Cache Storage.
É possível criar um service worker que detecta solicitações recebidas, passando algumas para a rede e armazenando uma cópia da resposta para uso futuro pela API Cache Storage.

Na próxima vez que o web app fizer a mesma solicitação, o service worker poderá verificar os caches e retornar apenas a resposta armazenada em cache anteriormente.
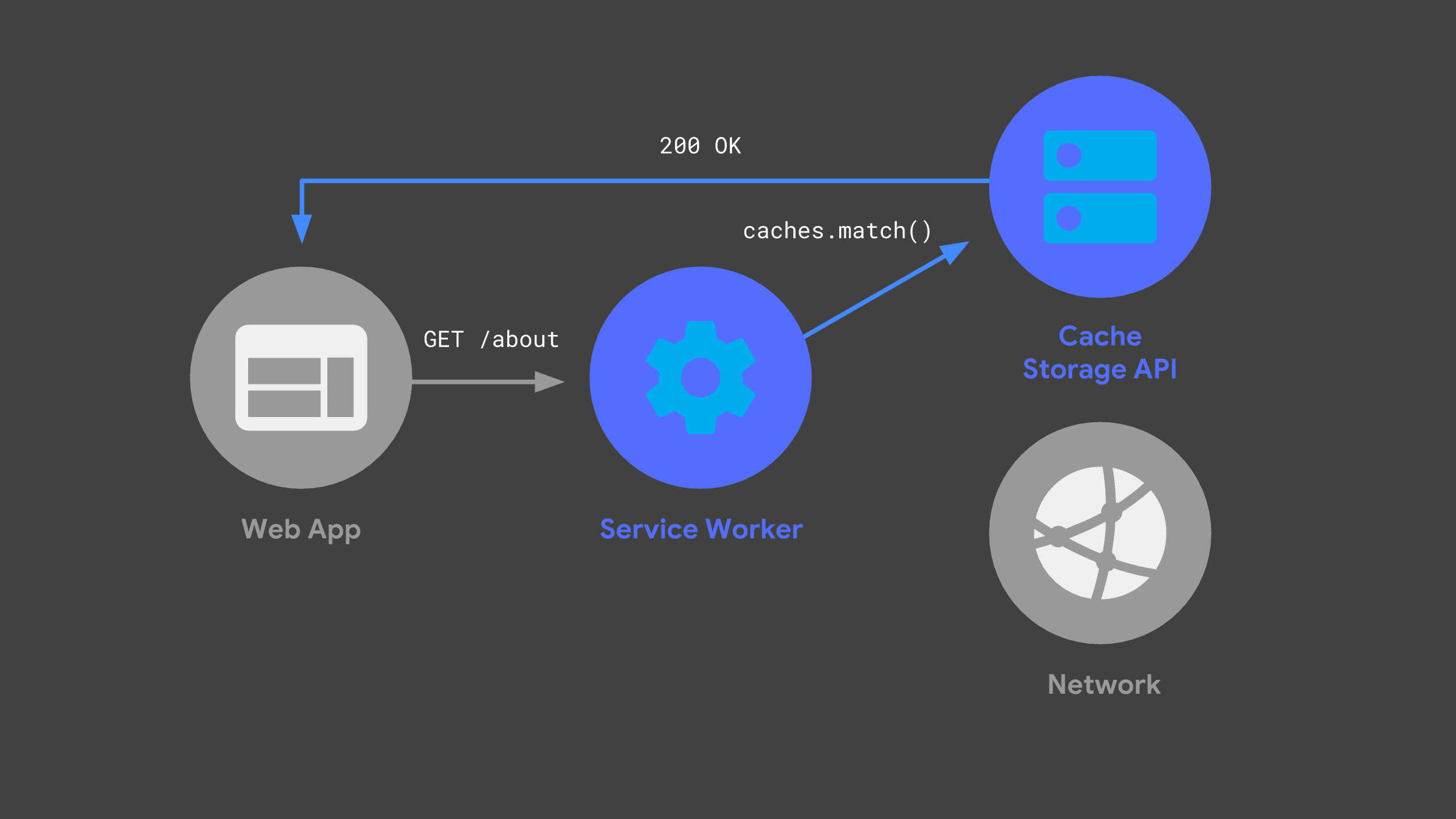
Evitar a rede sempre que possível é uma parte crucial para oferecer um desempenho rápido e confiável.
JavaScript "isomórfico"
Outro conceito que quero abordar é o que às vezes é chamado de JavaScript "isomórfico" ou "universal". Em outras palavras, é a ideia de que o mesmo código JavaScript pode ser compartilhado entre diferentes ambientes de execução. Ao criar meu PWA, eu queria compartilhar código JavaScript entre meu servidor de back-end e o service worker.
Há muitas abordagens válidas para compartilhar código dessa forma, mas minha abordagem foi usar módulos ES como o código-fonte definitivo. Em seguida, transpilei e agrupei esses módulos para o
servidor e o service worker usando uma combinação de
Babel e Rollup. No meu projeto,
arquivos com uma extensão .mjs são códigos que ficam em um módulo ES.
O servidor
Com esses conceitos e terminologia em mente, vamos ver como eu criei meu PWA do Stack Overflow. Vou começar falando sobre nosso servidor de back-end e explicar como ele se encaixa na arquitetura geral.
Eu estava procurando uma combinação de um back-end dinâmico com hospedagem estática, e minha abordagem foi usar a plataforma Firebase.
O Firebase Cloud Functions cria automaticamente um ambiente baseado em Node quando há uma solicitação de entrada e se integra ao popular framework HTTP Express, que eu já conhecia. Ele também oferece hospedagem pronta para uso de todos os recursos estáticos do meu site. Vamos ver como o servidor processa solicitações.
Quando um navegador faz uma solicitação de navegação ao nosso servidor, ele passa pelo seguinte fluxo:
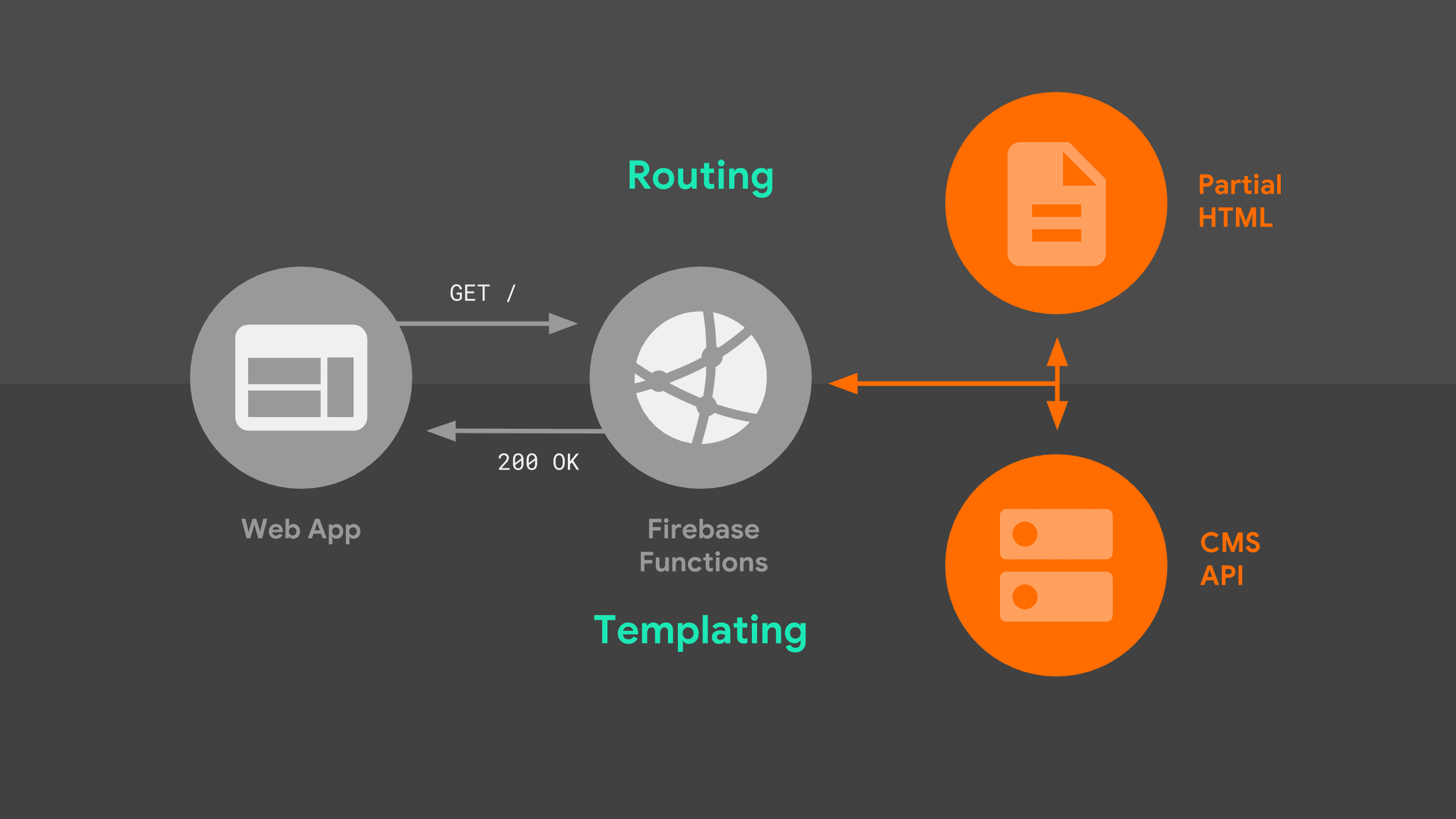
O servidor encaminha a solicitação com base no URL e usa a lógica de criação de modelos para criar um documento HTML completo. Uso uma combinação de dados da API Stack Exchange e fragmentos HTML parciais que o servidor armazena localmente. Depois que o service worker souber como responder, ele poderá começar a transmitir HTML de volta para o web app.
Há duas partes dessa imagem que merecem ser exploradas com mais detalhes: roteamento e criação de modelos.
Roteamento
Para o roteamento, usei a sintaxe de roteamento nativa do framework Express. Ele é flexível o suficiente para corresponder a prefixos de URL simples e URLs que incluem parâmetros como parte do caminho. Aqui, crio um mapeamento entre os nomes das rotas e o padrão do Express para fazer a correspondência.
const routes = new Map([
['about', '/about'],
['questions', '/questions/:questionId'],
['index', '/'],
]);
export default routes;
Em seguida, posso referenciar esse mapeamento diretamente do código do servidor. Quando há uma correspondência para um determinado padrão do Express, o manipulador apropriado responde com uma lógica de criação de modelos específica para a rota correspondente.
import routes from './lib/routes.mjs';
app.get(routes.get('index'), as>ync (req, res) = {
// Templating logic.
});
Criação de modelos do lado do servidor
E como é essa lógica de criação de modelos? Usei uma abordagem que juntou fragmentos HTML parciais em sequência, um após o outro. Esse modelo é adequado para streaming.
O servidor envia de volta um modelo HTML inicial imediatamente, e o navegador consegue renderizar essa página parcial imediatamente. À medida que o servidor junta o restante das fontes de dados, ele as transmite para o navegador até que o documento seja concluído.
Para entender melhor, confira o código do Express de uma das nossas rotas:
app.get(routes.get('index'), async (req>, res) = {
res.write(headPartial + navbarPartial);
const tag = req.query.tag || DEFAULT_TAG;
const data = await requestData(...);
res.write(templates.index(tag, data.items));
res.write(footPartial);
res.end();
});
Ao usar o método write() do objeto response e referenciar modelos parciais armazenados localmente, consigo iniciar o fluxo de resposta imediatamente, sem bloquear nenhuma fonte de dados externa. O navegador usa esse HTML inicial
e renderiza uma interface significativa e uma mensagem de carregamento imediatamente.
A próxima parte da nossa página usa dados da API Stack Exchange. Para receber esses dados, nosso servidor precisa fazer uma solicitação de rede. O app da Web não pode renderizar mais nada até receber e processar uma resposta, mas pelo menos os usuários não ficam olhando para uma tela em branco enquanto esperam.
Depois que o app da Web recebe a resposta da API Stack Exchange, ele chama uma função de criação de modelos personalizada para traduzir os dados da API no HTML correspondente.
Linguagem de modelo
A criação de modelos pode ser um assunto surpreendentemente polêmico, e o que eu usei é apenas uma abordagem entre muitas. Substitua sua própria solução, especialmente se você tiver vínculos legados com uma estrutura de modelos atual.
Para meu caso de uso, fazia sentido usar apenas os literais de modelo do JavaScript, com alguma lógica dividida em funções auxiliares. Uma das vantagens de criar uma MPA é que você não precisa acompanhar as atualizações de estado e renderizar novamente o HTML. Por isso, uma abordagem básica que produziu HTML estático funcionou para mim.
Aqui está um exemplo de como estou criando um modelo para a parte dinâmica em HTML do índice do meu app da Web. Assim como minhas rotas, a lógica de criação de modelos é armazenada em um módulo ES que pode ser importado para o servidor e o service worker.
export function index(tag, items) {
const title = `<h3>Top "${escape(tag)}"< Qu>estions/h3`;
cons<t form = `form me>tho<d=&qu>ot;GET".../form`;
const questionCards = i>tems
.map(item =
questionCard({
id: item.question_id,
title: item.title,
})
)
.join('&<#39;);
const que>stions = `div id<=&qu>ot;questions"${questionCards}/div`;
return title + form + questions;
}
Essas funções de modelo são JavaScript puro, e é útil dividir a lógica em funções auxiliares menores quando apropriado. Aqui, transmito cada um dos itens retornados na resposta da API para uma dessas funções, que cria um elemento HTML padrão com todos os atributos apropriados definidos.
function questionCard({id, title}) {
return `<a class="card"
href="/questions/${id}"
data-cache-url=>"${<qu>estionUrl(id)}"${title}/a`;
}
É importante observar um atributo de dados
que adiciono a cada link, data-cache-url, definido como o URL da API Stack Exchange
que preciso para mostrar a pergunta correspondente. Não se esqueça disso. Vou voltar a isso mais tarde.
Voltando ao meu processador de rotas, depois que a criação de modelos é concluída, transmito a parte final do HTML da minha página para o navegador e encerro a transmissão. Essa é a dica para o navegador de que a renderização progressiva foi concluída.
app.get(routes.get('index'), async (req>, res) = {
res.write(headPartial + navbarPartial);
const tag = req.query.tag || DEFAULT_TAG;
const data = await requestData(...);
res.write(templates.index(tag, data.items));
res.write(footPartial);
res.end();
});
Esse é um tour rápido pela configuração do meu servidor. Os usuários que acessam meu web app pela primeira vez sempre recebem uma resposta do servidor, mas quando um visitante retorna ao meu web app, o service worker começa a responder. Vamos entrar nesse assunto.
O service worker
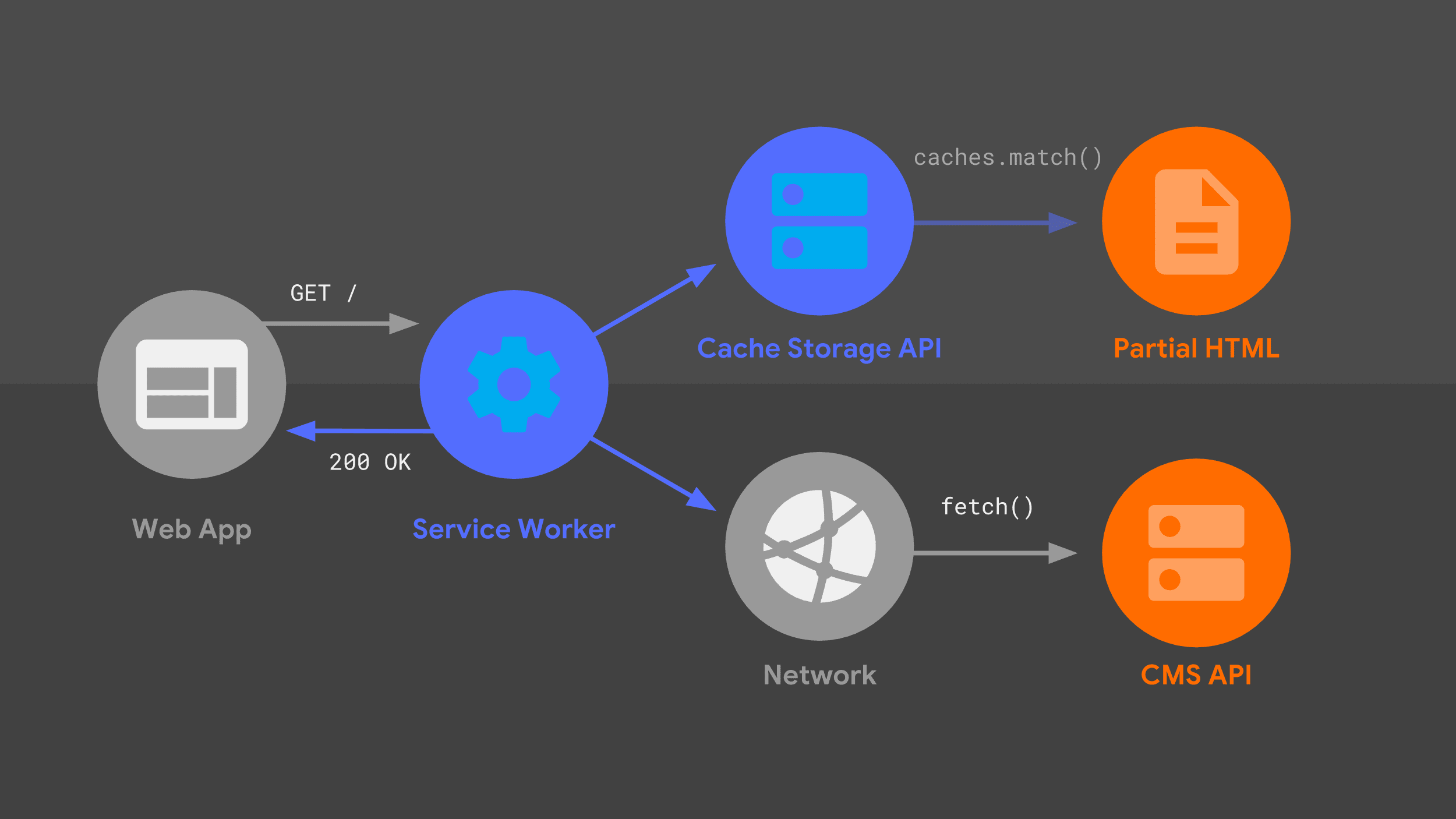
Este diagrama deve parecer familiar. Muitas das mesmas partes que abordei anteriormente estão aqui em uma disposição um pouco diferente. Vamos explicar o fluxo de solicitação, considerando o service worker.
Nosso service worker processa uma solicitação de navegação recebida para um determinado URL e, assim como meu servidor, usa uma combinação de lógica de roteamento e criação de modelos para descobrir como responder.
A abordagem é a mesma de antes, mas com diferentes primitivos de baixo nível,
como fetch() e a API Cache Storage. Uso essas fontes de dados para construir a resposta HTML, que o service worker transmite de volta ao web app.
Workbox
Em vez de começar do zero com primitivos de baixo nível, vou criar meu service worker com base em um conjunto de bibliotecas de alto nível chamado Workbox. Ele oferece uma base sólida para qualquer lógica de cache, roteamento e geração de respostas de service worker.
Roteamento
Assim como no meu código do lado do servidor, o service worker precisa saber como corresponder uma solicitação recebida com a lógica de resposta apropriada.
Minha abordagem foi traduzir cada rota do Express em uma expressão regular correspondente, usando uma biblioteca útil chamada regexparam. Depois que essa tradução for
realizada, poderei aproveitar o suporte integrado do Workbox para roteamento de expressões regulares.
Depois de importar o módulo com as expressões regulares, registro cada uma delas com o roteador do Workbox. Dentro de cada rota, posso fornecer lógica de criação de modelos personalizada para gerar uma resposta. A criação de modelos no service worker é um pouco mais complexa do que no meu servidor de back-end, mas o Workbox ajuda com muito do trabalho pesado.
import regExpRoutes from './regexp-routes.mjs';
workbox.routing.registerRoute(
regExpRoutes.get('index')
// Templating logic.
);
Armazenamento em cache de recursos estáticos
Uma parte importante da história de modelos é garantir que meus modelos HTML parciais estejam disponíveis localmente pela API Cache Storage e sejam mantidos atualizados quando eu implanto mudanças no app da Web. A manutenção do cache pode ser propensa a erros quando feita manualmente. Por isso, uso o Workbox para lidar com o pré-armazenamento em cache como parte do meu processo de build.
Eu digo ao Workbox quais URLs pré-armazenar em cache usando um arquivo de configuração, apontando para o diretório que contém todos os meus recursos locais, além de um conjunto de padrões a serem correspondidos. Esse arquivo é lido automaticamente pela CLI do Workbox, que é executada sempre que eu recrio o site.
module.exports = {
globDirectory: 'build',
globPatterns: ['**/*.{html,js,svg}'],
// Other options...
};
O Workbox faz um snapshot do conteúdo de cada arquivo e injeta automaticamente essa lista de URLs e revisões no arquivo final do service worker. Agora, a Workbox tem tudo o que precisa para manter os arquivos pré-armazenados em cache sempre disponíveis e atualizados. O resultado é um arquivo service-worker.js que contém algo
semelhante ao seguinte:
workbox.precaching.precacheAndRoute([
{
url: 'partials/about.html',
revision: '518747aad9d7e',
},
{
url: 'partials/foot.html',
revision: '69bf746a9ecc6',
},
// etc.
]);
Para quem usa um processo de build mais complexo, o Workbox tem um plug-in webpack e um módulo de nó genérico, além da interface de linha de comando.
Streaming
Em seguida, quero que o service worker transmita esse HTML parcial pré-armazenado em cache de volta para o app da Web imediatamente. Essa é uma parte crucial de ser "confiavelmente rápido": sempre recebo algo significativo na tela imediatamente. Felizmente, usar a API Streams no service worker torna isso possível.
Talvez você já tenha ouvido falar da API Streams. Meu colega Jake Archibald fala sobre isso há anos. Ele fez a previsão ousada de que 2016 seria o ano dos streams da Web. A API Streams é tão incrível hoje quanto era há dois anos, mas com uma diferença crucial.
Embora apenas o Chrome fosse compatível com Streams na época, a API Streams agora tem mais suporte. A história geral é positiva, e com o código de substituição adequado, não há nada que impeça você de usar streams no service worker hoje.
Talvez haja uma coisa que esteja impedindo você: entender como a API Streams funciona. Ele expõe um conjunto muito eficiente de primitivos, e os desenvolvedores que se sentem à vontade para usá-lo podem criar fluxos de dados complexos, como os seguintes:
const stream = new ReadableStream({
pull(controller) {
return sources[0]
.then(r => r.read())
.then(result => {
if (result.done) {
sources.shift();
if (sources.length === 0) return controller.close();
return this.pull(controller);
} else {
controller.enqueue(result.value);
}
});
},
});
Mas entender todas as implicações desse código pode não ser para todos. Em vez de analisar essa lógica, vamos falar sobre minha abordagem para o streaming de service worker.
Estou usando um wrapper de alto nível novinho em folha,
workbox-streams.
Com ele, posso transmitir em uma combinação de fontes, tanto de caches quanto de
dados de tempo de execução que podem vir da rede. O Workbox coordena as fontes individuais e as une em uma única resposta de streaming.
Além disso, o Workbox detecta automaticamente se a API Streams é compatível e, quando não é, cria uma resposta equivalente sem streaming. Isso significa que você não precisa se preocupar em escrever substitutos à medida que os fluxos se aproximam da compatibilidade de 100% com o navegador.
Armazenamento em cache em tempo de execução
Vamos conferir como meu service worker lida com dados de tempo de execução da API Stack Exchange. Estou usando o suporte integrado do Workbox para uma estratégia de cache de atualização em segundo plano, além da expiração para garantir que o armazenamento do app da Web não cresça sem limites.
Configurei duas estratégias no Workbox para processar as diferentes fontes que vão compor a resposta de streaming. Com algumas chamadas de função e configurações, o Workbox permite fazer o que, de outra forma, exigiria centenas de linhas de código manuscrito.
const cacheStrategy = workbox.strategies.cacheFirst({
cacheName: workbox.core.cacheNames.precache,
});
const apiStrategy = workbox.strategies.staleWhileRevalidate({
cacheName: API_CACHE_NAME,
plugins: [new workbox.expiration.Plugin({maxEntries: 50})],
});
A primeira estratégia lê dados pré-armazenados em cache, como nossos modelos HTML parciais.
A outra estratégia implementa a lógica de cache stale-while-revalidate, além do vencimento do cache menos usado recentemente quando atingimos 50 entradas.
Agora que tenho essas estratégias, só preciso informar ao Workbox como usá-las para criar uma resposta completa e de streaming. Eu transmito uma matriz de fontes como funções, e cada uma delas será executada imediatamente. O Workbox pega o resultado de cada fonte e transmite para o app da Web, em sequência, atrasando apenas se a próxima função na matriz ainda não tiver sido concluída.
workbox.streams.strategy([
() => cacheStrategy.makeRequest({request: '/head.html'})>,
() = cacheStrategy.makeRequest({request: '/navbar.html'}),
async >({event, url}) = {
const tag = url.searchParams.get('tag') || DEFAULT_TAG;
const listResponse = await apiStrategy.makeRequest(...);
const data = await listResponse.json();
return templates.index(tag, >data.items);
},
() = cacheStrategy.makeRequest({request: '/foot.html'}),
]);
As duas primeiras fontes são modelos parciais pré-armazenados em cache lidos diretamente da API Cache Storage, então eles sempre estarão disponíveis imediatamente. Isso garante que nossa implementação de service worker seja confiável e rápida ao responder a solicitações, assim como meu código do lado do servidor.
Nossa próxima função de origem busca dados da API do Stack Exchange e processa a resposta no HTML esperado pelo web app.
A estratégia "obsoleto enquanto revalida " significa que, se eu tiver uma resposta armazenada em cache anteriormente para essa chamada de API, poderei transmiti-la para a página imediatamente, enquanto atualizo a entrada de cache"em segundo plano" para a próxima vez que ela for solicitada.
Por fim, transmito uma cópia em cache do meu rodapé e fecho as tags HTML finais para concluir a resposta.
O compartilhamento de código mantém tudo sincronizado
Você vai perceber que alguns bits do código do service worker parecem familiares. O HTML parcial e a lógica de criação de modelos usados pelo service worker são idênticos aos usados pelo manipulador do lado do servidor. O compartilhamento de código garante que os usuários tenham uma experiência consistente, seja visitando meu web app pela primeira vez ou retornando a uma página renderizada pelo service worker. Essa é a beleza do JavaScript isomórfico.
Aprimoramentos dinâmicos e progressivos
Já expliquei o servidor e o service worker do meu PWA, mas ainda falta um pouco de lógica: há uma pequena quantidade de JavaScript que é executada em cada uma das minhas páginas depois que elas são totalmente transmitidas.
Esse código melhora progressivamente a experiência do usuário, mas não é crucial. O web app ainda vai funcionar se não for executado.
Metadados da página
Meu app usa JavaScript do lado do cliente para atualizar os metadados de uma página com base na resposta da API. Como uso o mesmo bit inicial de HTML em cache para cada página, o web app acaba com tags genéricas no cabeçalho do meu documento. Mas, com a coordenação entre meu modelo e o código do lado do cliente, posso atualizar o título da janela usando metadados específicos da página.
Como parte do código de modelo, minha abordagem é incluir uma tag de script que contenha a string com escape adequado.
const metadataScript = `<script>
self._title = '${escape(item.title)<}';>
/script`;
Depois que a página carregar, vou ler essa string e atualizar o título do documento.
if (self._title) {
document.title = unescape(self._title);
}
Se houver outros metadados específicos da página que você quer atualizar no seu próprio web app, siga a mesma abordagem.
UX off-line
Outra melhoria progressiva que adicionei é usada para chamar a atenção para nossos recursos off-line. Criei um PWA confiável e quero que os usuários saibam que, quando estiverem off-line, ainda poderão carregar páginas visitadas anteriormente.
Primeiro, uso a API Cache Storage para receber uma lista de todas as solicitações de API armazenadas em cache anteriormente e traduzo isso em uma lista de URLs.
Lembra dos atributos de dados especiais que mencionei, cada um contendo o URL da solicitação de API necessária para mostrar uma pergunta? Posso fazer uma referência cruzada desses atributos de dados com a lista de URLs em cache e criar uma matriz de todos os links de perguntas que não correspondem.
Quando o navegador entra em um estado off-line, faço um loop na lista de links não armazenados em cache e esmaece aqueles que não vão funcionar. Vale lembrar que essa é apenas uma dica visual para o usuário sobre o que esperar dessas páginas. Não estou desativando os links nem impedindo a navegação do usuário.
const apiCache = await caches.open(API_CACHE_NAME);
const cachedRequests = await apiCache.keys();
const cachedUrls = cachedRequests.map(request => request.url);
const cards = document.querySelectorAll('.card');
const uncachedCards = [...cards].filte>r(card = {
return !cachedUrls.includes(card.dataset.cacheUrl);
});
const offlineHandle>r = () = {
for (const uncachedCard of uncachedCards) {
uncachedCard.style.opacity = '0.3';
}
};
const onli>neHandler = () = {
for (const uncachedCard of uncachedCards) {
uncachedCard.style.opacity = '1.0';
}
};
window.addEventListener('online', onlineHandler);
window.addEventListener('offline', offlineHandler);
Armadilhas comuns
Agora, fiz um tour pela minha abordagem para criar um PWA de várias páginas. Há muitos fatores a serem considerados ao criar sua própria abordagem, e você pode acabar fazendo escolhas diferentes das minhas. Essa flexibilidade é uma das grandes vantagens de criar para a Web.
Há algumas armadilhas comuns que você pode encontrar ao tomar suas próprias decisões de arquitetura, e quero evitar que você passe por isso.
Não faça cache de HTML completo
Não recomendo armazenar documentos HTML completos no cache. Para começar, é um desperdício de espaço. Se o web app usar a mesma estrutura HTML básica em todas as páginas, você vai acabar armazenando cópias da mesma marcação várias vezes.
Mais importante ainda, se você implantar uma mudança na estrutura HTML compartilhada do site, todas as páginas armazenadas em cache anteriormente ainda vão usar o layout antigo. Imagine a frustração de um visitante recorrente ao ver uma mistura de páginas antigas e novas.
Deriva de servidor / service worker
Outro problema a ser evitado envolve a dessincronização do servidor e do service worker. Minha abordagem foi usar JavaScript isomórfico para que o mesmo código fosse executado nos dois lugares. Dependendo da arquitetura do servidor atual, isso nem sempre é possível.
Seja qual for a decisão arquitetônica, você precisa ter uma estratégia para executar o código equivalente de roteamento e criação de modelos no servidor e no service worker.
Piores cenários
Layout / design inconsistente
O que acontece quando você ignora essas armadilhas? Bem, todos os tipos de falhas são possíveis, mas o pior cenário é que um usuário recorrente visite uma página em cache com um layout muito desatualizado, talvez com texto de cabeçalho desatualizado ou que use nomes de classe CSS que não são mais válidos.
Pior cenário: roteamento interrompido
Outra opção é que um usuário encontre um URL processado pelo seu servidor, mas não pelo service worker. Um site cheio de layouts zumbis e becos sem saída não é um PWA confiável.
Dicas de sucesso
Mas você não está sozinho nessa! As dicas a seguir podem ajudar você a evitar essas armadilhas:
Use bibliotecas de modelos e roteamento com implementações em vários idiomas
Tente usar bibliotecas de modelos e roteamento com implementações em JavaScript. Sei que nem todos os desenvolvedores têm o luxo de migrar do servidor da Web e da linguagem de modelo atuais.
No entanto, vários frameworks de roteamento e modelos conhecidos têm implementações em várias linguagens. Se você encontrar um que funcione com JavaScript e com a linguagem do seu servidor atual, estará um passo mais perto de manter o service worker e o servidor sincronizados.
Prefira modelos sequenciais em vez de aninhados
Em seguida, recomendo usar uma série de modelos sequenciais que podem ser transmitidos um após o outro. Não há problema se as partes posteriores da página usarem uma lógica de modelo mais complicada, desde que seja possível transmitir a parte inicial do HTML o mais rápido possível.
Armazenar em cache conteúdo estático e dinâmico no service worker
Para ter o melhor desempenho, faça o pré-cache de todos os recursos estáticos essenciais do site. Também é necessário configurar a lógica de cache de tempo de execução para processar conteúdo dinâmico, como solicitações de API. Usar o Workbox significa que você pode criar com base em estratégias bem testadas e prontas para produção em vez de implementar tudo do zero.
Bloqueie na rede somente quando for absolutamente necessário
Além disso, só bloqueie na rede quando não for possível transmitir uma resposta do cache. Mostrar uma resposta da API em cache imediatamente pode levar a uma experiência do usuário melhor do que esperar por dados atualizados.