


Ich bin Ian Kilpatrick und leite zusammen mit Koji Ishii das Engineering-Team des Blink-Layouts. Bevor ich im Blink-Team anfing, war ich Frontend-Entwickler (bevor Google die Rolle des Frontend-Engineers hatte) und entwickelte Funktionen für Google Docs, Drive und Gmail. Nach etwa fünf Jahren in dieser Position wagte ich ein großes Risiko und wechselte zum Blink-Team. Dort lernte ich C++ im Job und versuchte, mich mit der enorm komplexen Blink-Codebasis vertraut zu machen. Selbst heute verstehe ich nur einen relativ kleinen Teil davon. Ich bin Ihnen für die Zeit, die Sie mir in dieser Zeit geben, sehr dankbar. Ich fand es beruhigend, dass viele „rekonvaleszente Frontend-Entwickler“ vor mir den Wechsel zu „Browser-Entwicklern“ vollzogen hatten.
Meine bisherigen Erfahrungen haben mich bei der Arbeit im Blink-Team persönlich geprägt. Als Frontend-Entwickler bin ich ständig auf Browserinkonsistenzen, Leistungsprobleme, Rendering-Fehler und fehlende Funktionen gestoßen. LayoutNG bot mir die Möglichkeit, diese Probleme systematisch innerhalb des Layoutsystems von Blink zu beheben. Das ist die Summe der Bemühungen vieler Entwicklerinnen und Entwickler über die Jahre.
In diesem Beitrag erkläre ich, wie eine solche große Architekturänderung verschiedene Arten von Fehlern und Leistungsproblemen reduzieren und abmildern kann.
Ein allgemeiner Überblick über Layout-Engine-Architekturen
Bisher war das Layout-Baum von Blink ein sogenannter „veränderlicher Baum“.
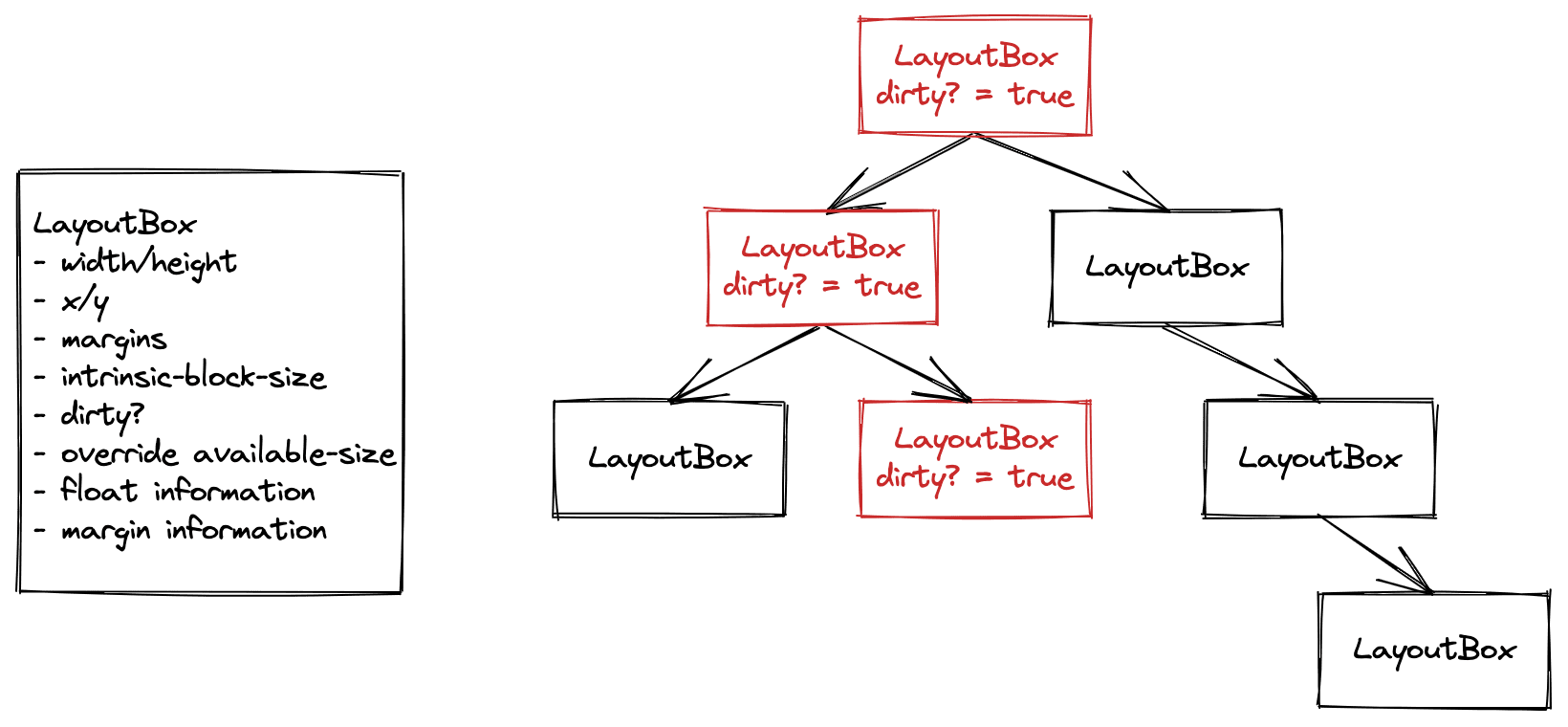
Jedes Objekt im Layoutbaum enthielt Eingabeinformationen, z. B. die von einem übergeordneten Element auferlegte verfügbare Größe, die Position aller Floating-Elemente und Ausgabeinformationen, z. B. die endgültige Breite und Höhe des Objekts oder seine X‑ und Y‑Position.
Diese Objekte wurden zwischen den Rendern beibehalten. Bei einer Stiländerung kennzeichneten wir das Objekt als „schmutzig“ und alle übergeordneten Elemente im Baum. Wenn die Layoutphase der Rendering-Pipeline ausgeführt wurde, haben wir den Baum bereinigt, alle schmutzigen Objekte durchgegangen und dann das Layout ausgeführt, um sie in einen sauberen Zustand zu versetzen.
Wir haben festgestellt, dass diese Architektur zu vielen Arten von Problemen geführt hat, die wir unten beschreiben. Aber zuerst wollen wir uns die Eingaben und Ausgaben des Layouts ansehen.
Beim Ausführen des Layouts auf einem Knoten in diesem Baum wird konzeptionell der Stil plus DOM verwendet, wobei alle übergeordneten Einschränkungen des übergeordneten Layoutsystems (Raster, Block oder Flex) den Algorithmus für Layouteinschränkungen ausgeführt werden und ein Ergebnis erzeugt wird.
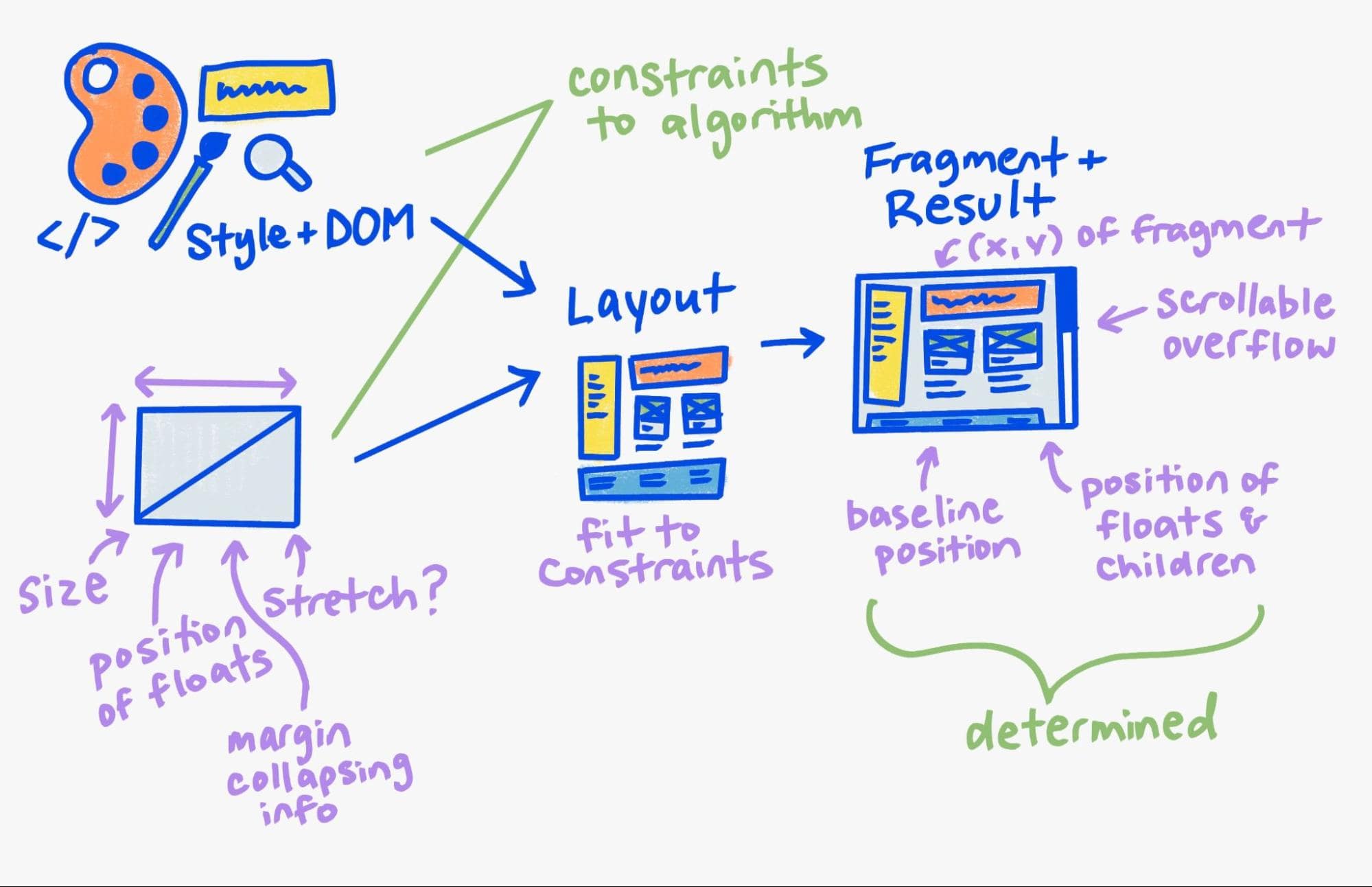
Unsere neue Architektur formalisiert dieses konzeptionelle Modell. Wir haben noch den Layoutbaum, aber wir verwenden ihn in erster Linie, um die Ein- und Ausgaben des Layouts zu speichern. Für die Ausgabe generieren wir ein vollständig neues, unveränderliches Objekt, das als Fragmentstruktur bezeichnet wird.
Ich habe bereits den unveränderlichen Fragmentbaum kennengelernt und beschrieben, wie große Teile des vorherigen Baums für inkrementelle Layouts wiederverwendet werden können.
Außerdem speichern wir das übergeordnete Objekt mit den Einschränkungen, aus dem dieses Fragment generiert wurde. Wir verwenden dies als Cache-Schlüssel, auf den wir weiter unten noch näher eingehen.
Der Inline-Layoutalgorithmus (Text) wird ebenfalls umgeschrieben, um der neuen unveränderlichen Architektur zu entsprechen. Sie erstellt nicht nur die unveränderliche, flache Listendarstellung für das Inline-Layout, sondern bietet auch Caching auf Absatzebene für ein schnelleres Layout, eine Form pro Absatz, um Schriftmerkmale auf Elemente und Wörter anzuwenden, einen neuen bidirektionalen Unicode-Algorithmus mit ICU, zahlreiche Korrektheitskorrekturen und vieles mehr.
Arten von Layoutfehlern
Layoutfehler lassen sich grob in vier verschiedene Kategorien unterteilen, die jeweils unterschiedliche Ursachen haben.
Richtigkeit
Bei Fehlern im Rendering-System geht es in der Regel um die Richtigkeit, zum Beispiel: "Browser A verhält sich X, Browser B verhält sich Y" oder "Browser A und B sind beide fehlerhaft". Zuvor haben wir viel Zeit damit verbracht, und währenddessen kämpften wir ständig mit dem System. Ein häufiger Fehler war, dass wir eine sehr gezielte Fehlerbehebung für einen Fehler angewendet haben, aber Wochen später feststellten, dass wir eine Regression in einem anderen (scheinbar nicht zusammenhängenden) Teil des Systems verursacht hatten.
Wie in vorherigen Beiträgen beschrieben, ist dies ein Zeichen für ein sehr brüchiges System. Insbesondere für das Layout gab es keine klare Vereinbarung zwischen den Klassen. Das führte dazu, dass Browserentwickler auf einen Status angewiesen waren, der nicht erforderlich war, oder einen Wert aus einem anderen Teil des Systems falsch interpretierten.
Beispielsweise gab es einmal eine Kette von etwa zehn Fehlern im Zusammenhang mit dem Flex-Layout, die sich über mehr als ein Jahr erstreckte. Jede Korrektur führte entweder zu einem Korrektheits- oder Leistungsproblem in einem Teil des Systems, was wiederum zu einem weiteren Fehler führte.
Da LayoutNG die Vereinbarung zwischen allen Komponenten im Layoutsystem klar definiert, können wir Änderungen jetzt mit viel größerer Sicherheit vornehmen. Außerdem profitieren wir sehr vom hervorragenden Web Platform Tests (WPT)-Projekt, mit dem mehrere Parteien zu einer gemeinsamen Web-Testsuite beitragen können.
Heute stellen wir fest, dass wir bei einer echten Regression auf unserem stabilen Kanal in der Regel keine zugehörigen Tests im WPT-Repository finden und dass sie nicht auf einem Missverständnis der Komponentenverträge beruht. Außerdem fügen wir im Rahmen unserer Richtlinie zur Fehlerbehebung immer einen neuen WPT-Test hinzu, um dafür zu sorgen, dass kein Browser denselben Fehler noch einmal macht.
Unter „Außerkraftsetzung“
Wenn Sie schon einmal einen mysteriösen Fehler hatten, bei dem der Fehler durch Ändern der Größe des Browserfensters oder Umschalten einer CSS-Eigenschaft wie von Zauberhand verschwindet, haben Sie ein Problem mit unzureichender Invalidation. Tatsächlich wurde ein Teil des änderbaren Baums als sauber erachtet. Aufgrund von Änderungen bei den übergeordneten Einschränkungen wurde jedoch nicht die richtige Ausgabe dargestellt.
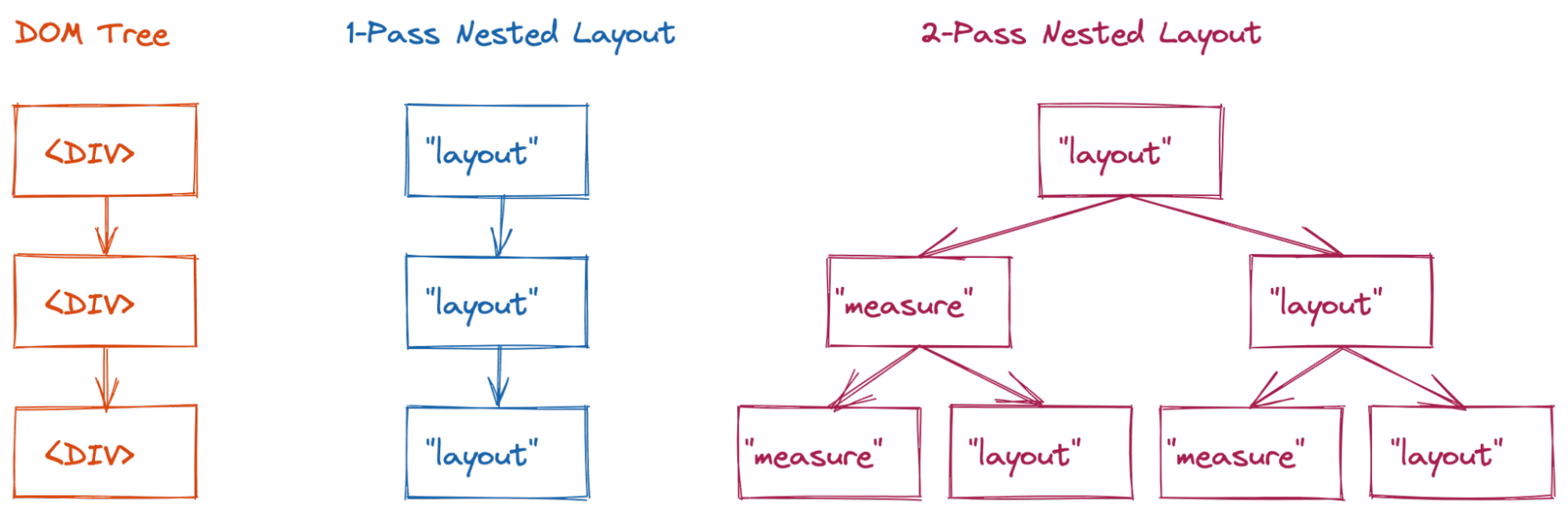
Das ist bei den unten beschriebenen Layoutmodi mit zwei Durchläufen (der Layoutbaum wird zweimal durchlaufen, um den endgültigen Layoutstatus zu ermitteln) sehr häufig der Fall. Bisher sah unser Code so aus:
if (/* some very complicated statement */) {
child->ForceLayout();
}
Eine Fehlerbehebung für diese Art von Fehler sieht in der Regel so aus:
if (/* some very complicated statement */ ||
/* another very complicated statement */) {
child->ForceLayout();
}
Eine Behebung dieses Problems führte in der Regel zu einer erheblichen Leistungsverschlechterung (siehe unten „Übermäßige Invalidation“) und war sehr schwierig.
Heute haben wir (wie oben beschrieben) ein unveränderliches übergeordnetes Einschränkungsobjekt, das alle Eingaben vom übergeordneten Layout in das untergeordnete Element beschreibt. Dieser wird zusammen mit dem resultierenden unveränderlichen Fragment gespeichert. Aus diesem Grund haben wir einen zentralen Ort, an dem wir diese beiden Eingaben vergleichen, um festzustellen, ob für das untergeordnete Element ein weiterer Layout-Durchlauf ausgeführt werden muss. Diese Differenzierungslogik ist kompliziert, aber gut strukturiert. Das Beheben dieser Klasse von Problemen mit der Unterentwertung führt in der Regel dazu, dass die beiden Eingaben manuell geprüft und entschieden werden, was sich in der Eingabe geändert hat, sodass ein weiterer Layoutdurchlauf erforderlich ist.
Korrekturen an diesem Code zum Vergleichen sind in der Regel einfach und können aufgrund der einfachen Erstellung dieser unabhängigen Objekte leicht mithilfe von Unit-Tests getestet werden.
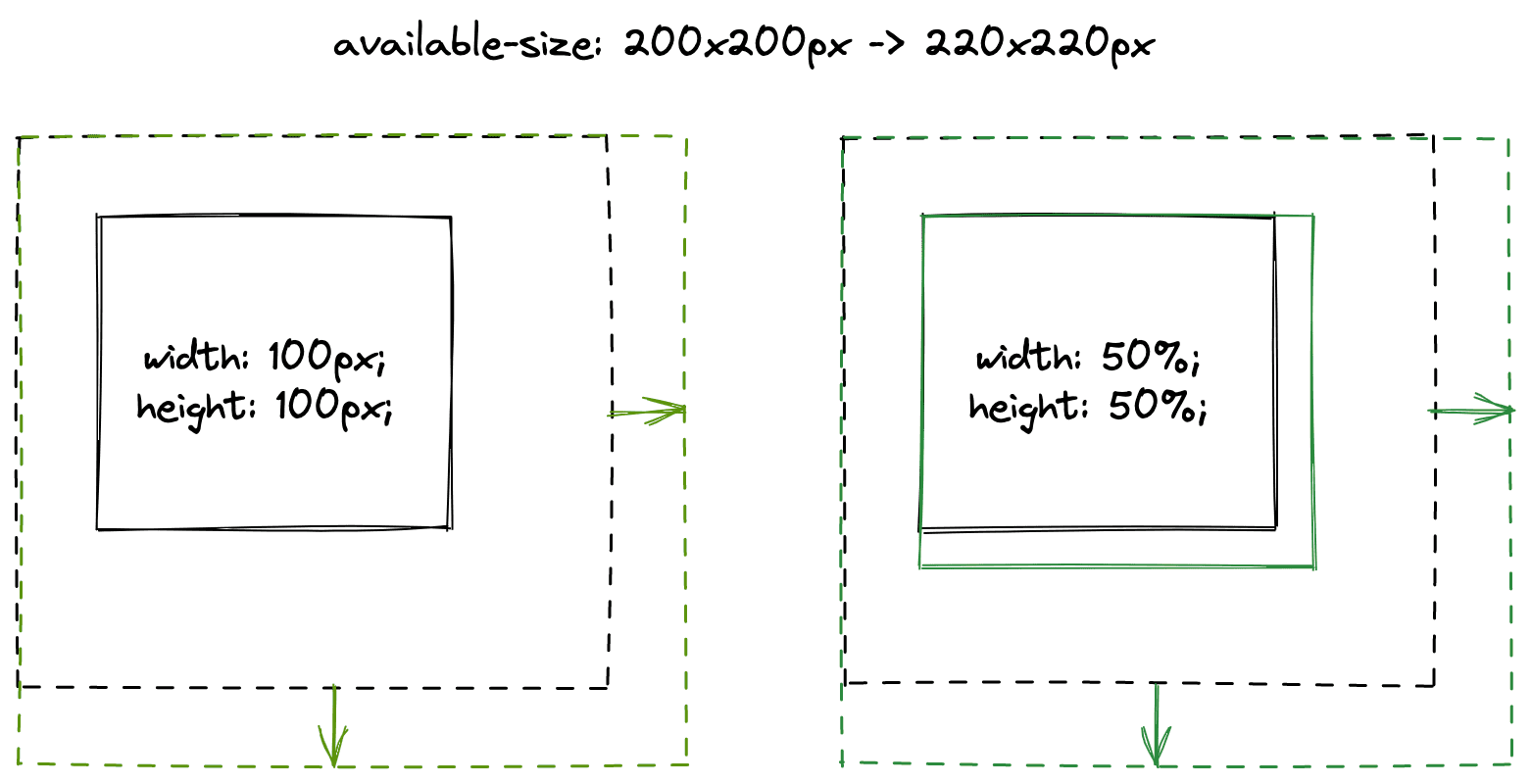
Der Diff-Code für das obige Beispiel lautet:
if (width.IsPercent()) {
if (old_constraints.WidthPercentageSize()
!= new_constraints.WidthPercentageSize())
return kNeedsLayout;
}
if (height.IsPercent()) {
if (old_constraints.HeightPercentageSize()
!= new_constraints.HeightPercentageSize())
return kNeedsLayout;
}
Hysterese
Diese Art von Fehlern ähnelt der Unterbeanstandung. Im vorherigen System war es unglaublich schwierig, sicherzustellen, dass das Layout idempotent war, d. h., die erneute Ausführung des Layouts mit denselben Eingaben führte zur gleichen Ausgabe.
Im folgenden Beispiel wechseln wir einfach zwischen zwei Werten einer CSS-Property hin und her. Dies führt jedoch zu einem „unendlich wachsenden“ Rechteck.
Mit unserem vorherigen änderbaren Baum war es unglaublich einfach, Bugs wie diesen einzubauen. Wenn durch den Code der Fehler gemacht wurde, die Größe oder Position eines Objekts zum falschen Zeitpunkt oder in der falschen Phase zu lesen (da wir beispielsweise die vorherige Größe oder Position nicht „gelöscht“ haben), würden wir sofort einen subtilen Hysteresefehler hinzufügen. Diese Fehler treten in der Regel nicht bei Tests auf, da sich die meisten Tests auf ein einzelnes Layout und Rendering konzentrieren. Noch besorgniserregender war, dass wir wussten, dass ein Teil dieser Hysterese erforderlich war, damit einige Layoutmodi richtig funktionieren. Es gab Fehler, bei denen wir eine Optimierung durchgeführt haben, um einen Layout-Pass zu entfernen, aber einen „Fehler“ eingeführt haben, da der Layout-Modus zwei Pässe erforderte, um die richtige Ausgabe zu erhalten.
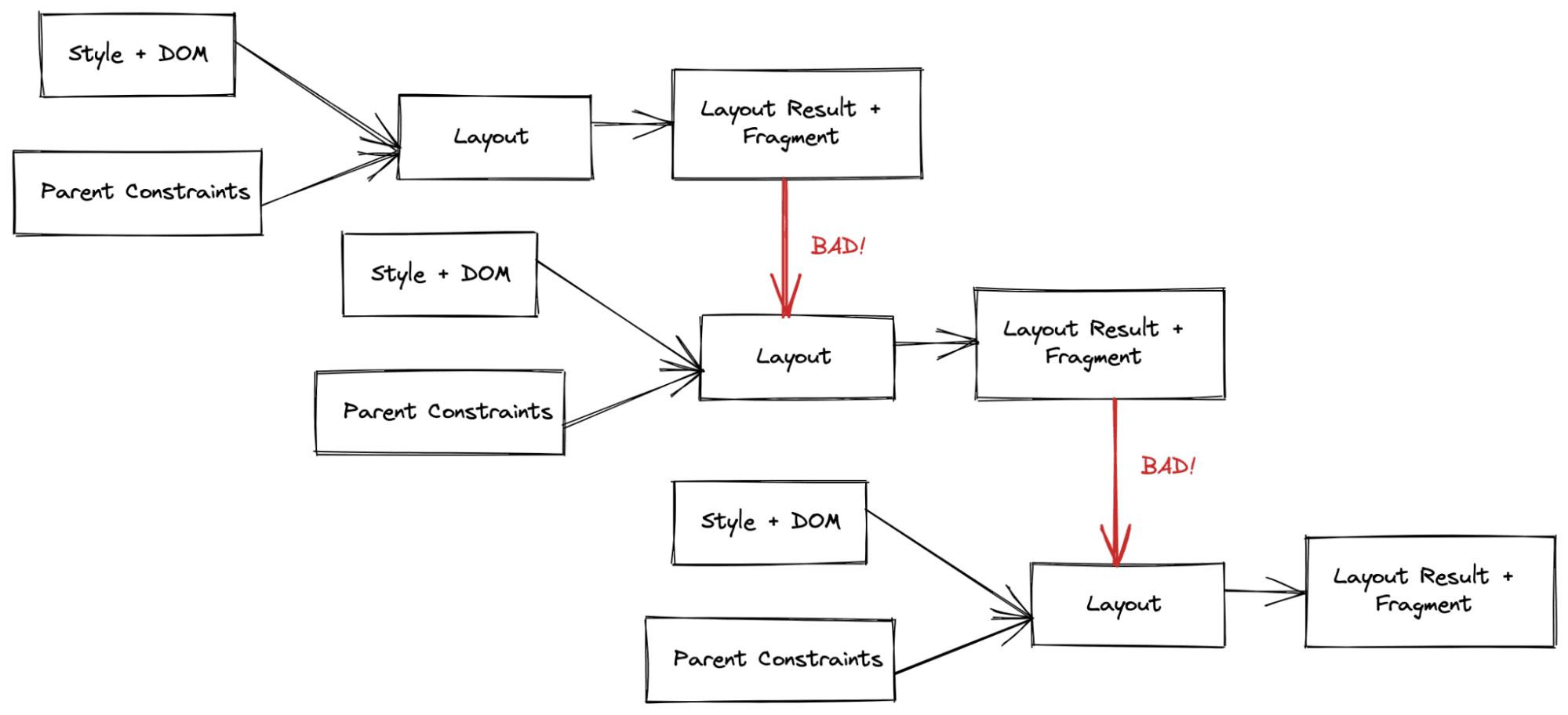
Da wir bei LayoutNG explizite Eingabe- und Ausgabedatenstrukturen haben und der Zugriff auf den vorherigen Zustand nicht zulässig ist, konnten wir diese Art von Fehler im Layoutsystem weitgehend beheben.
Übermäßige Invalidation und Leistung
Dies ist das genaue Gegenteil der Klasse von Fehlern, bei denen zu wenig Daten ungültig gemacht werden. Oft haben wir bei der Behebung eines Fehlers, bei dem zu wenige Einträge ungültig gemacht wurden, eine Leistungseinbußen ausgelöst.
Oft mussten wir schwierige Entscheidungen treffen, bei denen wir die Korrektheit der Leistung vorrangig betrachtet haben. Im nächsten Abschnitt erfahren Sie, wie wir diese Leistungsprobleme behoben haben.
Die Ära der Layouts mit zwei Durchläufen und Leistungseinbrüche
Flex- und Rasterlayouts haben die Ausdruckskraft von Layouts im Web verändert. Diese Algorithmen unterscheiden sich jedoch grundlegend von dem Block-Layout-Algorithmus, der vorher eingesetzt wurde.
Für das Block-Layout ist in fast allen Fällen erforderlich, dass die Suchmaschine das Layout für alle untergeordneten Elemente nur genau einmal ausführt. Das ist zwar gut für die Leistung, aber nicht so ausdrucksstark, wie es Webentwickler wünschen.
Beispielsweise möchten Sie oft, dass die Größe aller untergeordneten Elemente auf die Größe der größten erweitert wird. Zu diesem Zweck führt das übergeordnete Layout (Flex oder Raster) eine Messungsübergabe durch, um zu bestimmen, wie groß die einzelnen untergeordneten Elemente sind. Dann wird ein Layoutübergang durchgeführt, um alle untergeordneten Elemente auf diese Größe zu erweitern. Dieses Verhalten ist sowohl für das Flex- als auch für das Grid-Layout standardmäßig aktiviert.

Diese Layouts mit zwei Durchgängen waren anfangs leistungsmäßig akzeptabel, da sie in der Regel nicht tief verschachtelt waren. Mit komplexeren Inhalten traten jedoch erhebliche Leistungsprobleme auf. Wenn Sie das Ergebnis der Messungsphase nicht im Cache speichern, wechselt der Layoutbaum zwischen seinem measure- und seinem endgültigen layout-Status.
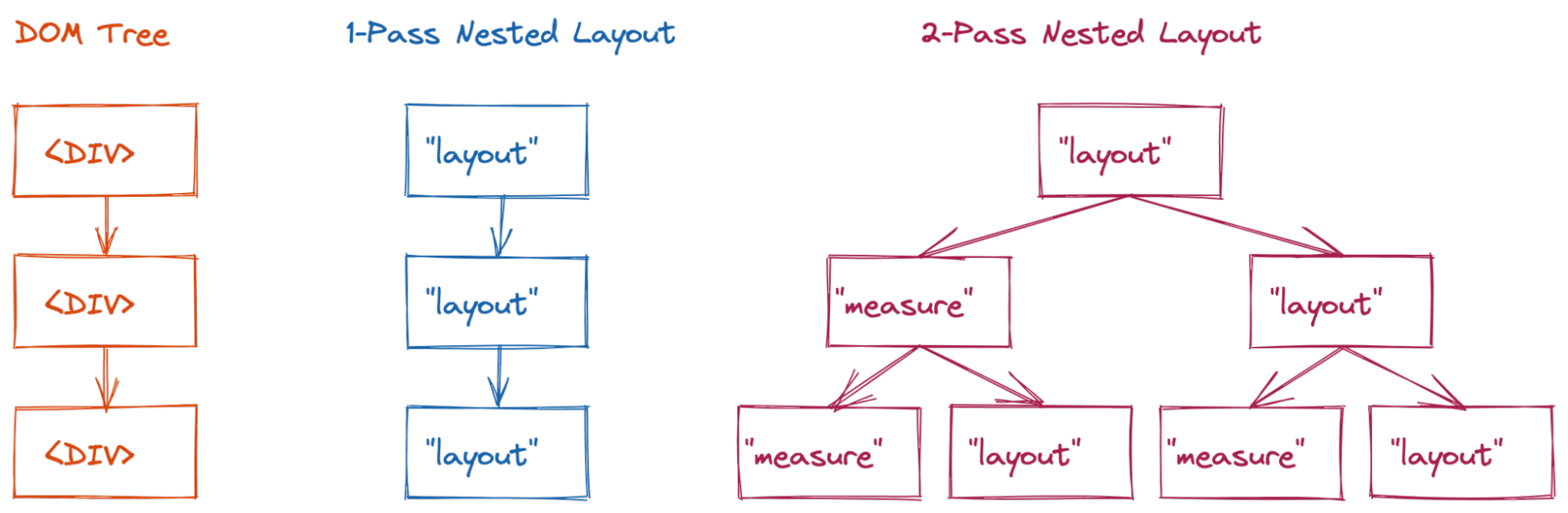
<div>-Elemente zu sehen.
Bei einem einfachen Layout mit nur einem Durchlauf (z. B. Blocklayout) werden drei Layoutknoten besucht (Komplexität O(n)).
Bei einem Layout mit zwei Durchläufen (z. B. Flex oder Grid) kann dies jedoch zu einer Komplexität von O(2n) Besuchen für dieses Beispiel führen.
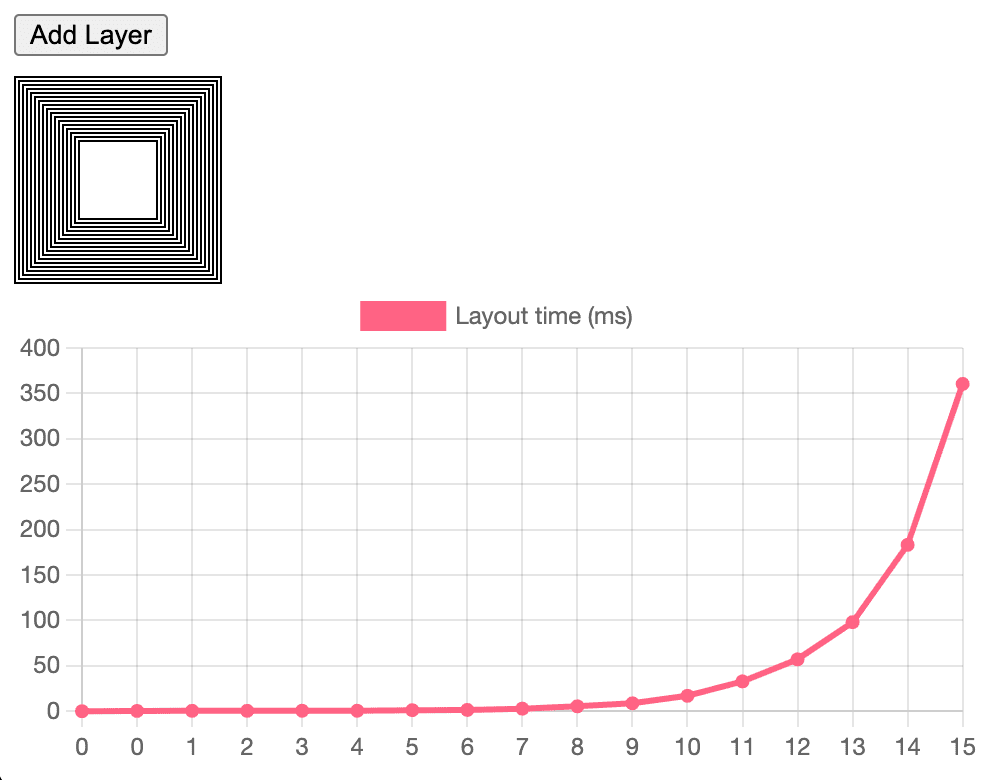
Früher haben wir versucht, dem Flex- und Raster-Layout sehr spezifische Caches hinzuzufügen, um diese Art von Leistungsklippen zu beseitigen. Das funktionierte (und wir kamen mit Flex sehr weit), aber wir hatten ständig mit Fehlern zu kämpfen, bei denen die Daten zu oft oder zu selten ungültig gemacht wurden.
Mit LayoutNG können wir sowohl für die Eingabe als auch für die Ausgabe des Layouts explizite Datenstrukturen erstellen. Außerdem haben wir Caches für die Mess- und Layoutpässe erstellt. Dadurch wird die Komplexität wieder auf O(n) zurückgeführt, was zu einer vorhersehbaren linearen Leistung für Webentwickler führt. Sollte ein Layout drei Durchläufe erfordern, wird auch dieser Durchlauf einfach im Cache gespeichert. Dies kann in Zukunft die Möglichkeit eröffnen, erweiterte Layoutmodi sicher einzuführen. Ein Beispiel dafür, wie RenderingNG die Erweiterbarkeit insgesamt grundlegend verbessert. In einigen Fällen kann ein Grid-Layout drei Durchläufe erfordern, was derzeit jedoch äußerst selten vorkommt.
Wenn Entwickler Leistungsprobleme speziell beim Layout feststellen, liegt das in der Regel an einem Fehler bei der exponentiellen Layoutzeit und nicht am Rohdurchsatz der Layoutphase der Pipeline. Wenn eine kleine inkrementelle Änderung (ein Element ändert eine einzelne CSS-Eigenschaft) zu einem Layout von 50–100 Millisekunden führt, ist das wahrscheinlich ein exponentieller Layoutfehler.
Zusammenfassung
Das Layout ist ein extrem komplexer Bereich. Wir haben nicht alle interessanten Details wie Inline-Layout-Optimierungen (wie das gesamte Inline- und Text-Subsystem funktioniert) behandelt. Selbst die hier besprochenen Konzepte haben nur an der Oberfläche gekratzt und viele Details ausgeblendet. Wir hoffen jedoch, dass wir gezeigt haben, wie die systematische Verbesserung der Architektur eines Systems langfristig zu überdurchschnittlichen Gewinnen führen kann.
Uns ist aber bewusst, dass noch viel Arbeit vor uns liegt. Wir sind uns der verschiedenen Kategorien von Problemen (Leistung und Richtigkeit) bewusst, an deren Lösung wir arbeiten, und freuen uns auf neue Layoutfunktionen für CSS. Wir sind davon überzeugt, dass die Architektur von LayoutNG sicher und umsetzbar ist.
Ein Bild (Sie wissen schon welches!) von Una Kravets