部署和管理此服务,以便为 Attribution Reporting API 或 Private Aggregation API 生成摘要报告。
部署和管理汇总服务,以通过 Attribution Reporting API 或 Private Aggregation API 处理可汇总报告,以创建摘要报告。
实现状态
- 汇总服务现已正式发布。
- 您可以使用 Attribution Reporting API 和适用于 Protected Audience API 和共享存储空间的 Private Aggegration API 测试汇总服务。
解释器概述了关键术语,有助于理解汇总服务。
可用性
| Proposal | Status |
|---|---|
| Aggregation Service support for Amazon Web Services (AWS) across Attribution Reporting API, Private Aggregation API
Explainer |
Available |
| Aggregation Service support for Google Cloud across Attribution Reporting API, Private Aggregation API Explainer |
Available in beta |
| Aggregation Service site enrollment and mapping of a site to cloud accounts (AWS, or GCP) FAQs on GitHub |
Available |
| The Aggregation Service's epsilon value will be kept as a range of up to 64, to facilitate experimentation and feedback on different parameters.
Submit ARA epsilon feedback. Submit PAA epsilon feedback. |
Available. We will provide advanced notice to the ecosystem before the epsilon range values are updated. |
| More flexible contribution filtering for Aggregation Service queries
Explainer |
Expected Q2 2024 |
| Process for budget recovery post-disasters (errors, misconfigurations, and so on)
GitHub issue |
Expected Q2 2024 |
| Accenture operating as one of the Coordinators on AWS
Developer Blog |
Available |
| Independent party operating as one of the Coordinators on Google Cloud
Developer Blog |
Expected Q3 2024 |
安全的数据处理方式
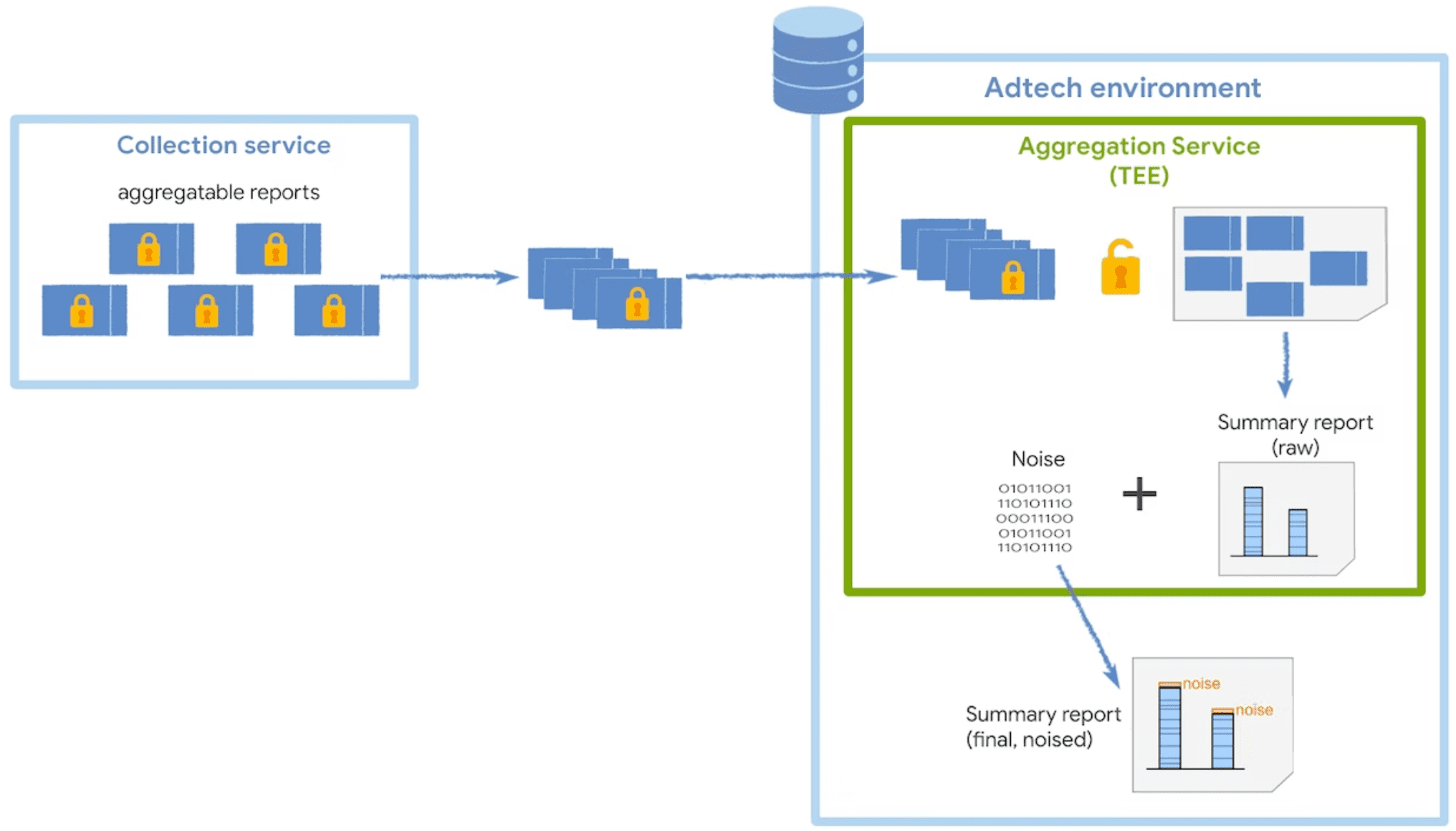
汇总服务会解密和合并从可汇总报告中收集的数据,添加噪声,然后返回最终的摘要报告。此服务在可信执行环境 (TEE) 中运行,该环境部署在支持必要安全措施保护这些数据的云服务上。
TEE 的代码是汇总服务中唯一有权访问原始报告的位置,此代码将可供安全研究人员、隐私保护倡导者和广告技术平台审核。为了确认 TEE 运行的是否为正版经批准的软件,并确保数据始终受保护,协调者会执行认证。
TEE 的协调器认证
协调者是负责密钥管理和可汇总报告会计的实体。
协调者有以下几项职责:
- 维护一个已授权二进制映像的列表。这些映像是 Google 将定期发布的汇总服务软件 build 的加密哈希。这种情况是可重现的,这样任何一方都可以验证这些映像是否与汇总服务 build 相同。
- 运行密钥管理系统。用户设备上的 Chrome 需要使用加密密钥才能加密可汇总报告。使用解密密钥来证明汇总服务代码与二进制图片匹配。
- 跟踪可汇总报告,以防在汇总报告时重复使用,因为重复使用可能会泄露个人身份信息 (PII)。
“无重复”规则
为了深入了解特定可汇总报告的内容,攻击者可能会制作报告的多个副本,并将这些副本包含在单个或多个批次中。因此,汇总服务会强制执行“无重复”规则:
- 批量处理:一个可汇总的报告只能在一个批次中显示一次。
- 跨批次:可汇总报告不能出现在多个批次中,也不能出现在多个摘要报告中。
为此,浏览器会为每个可汇总报告分配一个共享 ID。浏览器会根据多个数据点生成共享 ID,这些数据点包括:API 版本、报告来源、目标网站、来源注册时间和计划报告时间。此数据来自报告中的 shared_info 字段。
汇总服务确认具有相同共享 ID 的所有可汇总报告是否属于同一批次,并向协调者报告共享 ID 已处理。如果创建了具有相同 ID 的多个批次,则仅接受一个批次进行聚合,而拒绝其他批次。
执行调试运行时,系统不会跨批次强制执行“无重复项”规则。换句话说,先前批次的报告可能会显示在调试运行中。但是,该规则仍然会在一个批次中强制执行。这样,您就可以试用该服务和各种批处理策略,而不会限制未来生产环境中的处理。
噪声和缩放
为了保护用户隐私,汇总服务对可汇总报告中的原始数据应用了累加噪声机制。这意味着,每个汇总值都会先添加一定数量的统计噪声,然后再发布摘要报告。
虽然您无法直接控制噪声的添加方式,但您可以影响噪声对其测量数据的影响。

噪声值是从拉普拉斯概率分布中随机抽取的,无论可汇总报告中收集的数据量如何,该分布都相同。您收集的数据越多,噪声对摘要报告结果的影响越小。您可以将可汇总报告数据乘以缩放比例,以减少噪声的影响。
如需了解噪声的添加方式、您的控制措施以及对报告的影响,请参阅使用噪声中的贡献预算和纵向扩容以增加贡献预算。
生成摘要报告
摘要报告生成取决于您的 API 使用情况。详细了解如何为 Private Aggregation API 和 Attribution Reporting API 生成摘要报告。
测试汇总服务
建议您阅读要测试的每个 API 的相应指南:
要在 AWS 上测试汇总服务,请参阅这些说明。
您还可以使用本地测试工具为 Attribution Reporting 和 Private Aggregation API 处理可汇总报告。
汇总服务负载测试框架提供了一个建议的测试框架。
互动和分享反馈
汇总服务是 Privacy Sandbox 效果衡量 API 的关键一环。与其他 Privacy Sandbox API 一样,GitHub 上对此进行了公开文档和讨论。
- GitHub:阅读说明文档、提出问题并参与讨论。此外,请查看汇总服务实现并提供有关实现的反馈。
- 开发者支持:在 Privacy Sandbox 开发者支持代码库中提问并加入讨论。